Beyond Suffixes: Token Position in GCG Adversarial Attacks on Large Language Models
作者: Hicham Eddoubi, Umar Faruk Abdullahi, Fadi Hassan
分类: cs.LG
发布日期: 2026-02-03
备注: 12 pages, 10 figures
💡 一句话要点
揭示GCG攻击盲点:对抗性Token位置显著影响大语言模型越狱攻击成功率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 对抗攻击 越狱攻击 GCG攻击 对抗鲁棒性
📋 核心要点
- 现有大语言模型安全评估主要关注对抗性后缀,忽略了对抗性token在提示中的位置这一关键因素。
- 该论文通过调整GCG攻击策略,探索了对抗性token作为前缀以及改变其位置对攻击成功率的影响。
- 实验结果表明,对抗性token的位置对攻击效果有显著影响,揭示了当前安全评估的盲点。
📝 摘要(中文)
大型语言模型(LLMs)已在多个领域得到广泛应用,因此迫切需要强大的安全对齐机制。然而,由于越狱攻击可以通过对抗性提示绕过对齐,因此鲁棒性仍然具有挑战性。本文重点关注流行的贪婪坐标梯度(GCG)攻击,并识别出越狱攻击中一个先前未被充分探索的攻击维度,该维度通常被认为是基于后缀的:对抗性token在提示中的位置。以GCG作为案例研究,我们表明,优化攻击以生成前缀而不是后缀,以及在评估期间改变对抗性token的位置,都会显著影响攻击成功率。我们的研究结果突出了当前安全评估中的一个关键盲点,并强调需要在LLM的对抗鲁棒性评估中考虑对抗性token的位置。
🔬 方法详解
问题定义:现有的大语言模型安全评估,特别是针对越狱攻击的评估,通常侧重于对抗性后缀的生成和优化,而忽略了对抗性token在整个prompt中的位置对攻击效果的影响。这种以后缀为中心的评估方式可能无法全面反映模型的真实安全水平,存在被绕过的风险。
核心思路:该论文的核心思路是打破对抗性攻击通常以后缀形式存在的固有认知,探索对抗性token作为前缀以及在prompt中不同位置对攻击成功率的影响。通过系统性地改变对抗性token的位置,可以更全面地评估大语言模型的对抗鲁棒性,并发现潜在的安全漏洞。
技术框架:该研究以GCG(Greedy Coordinate Gradient)攻击作为案例研究。GCG是一种迭代式的攻击方法,通过贪婪地搜索和优化对抗性token,以最大化攻击目标。研究人员修改了GCG的实现,使其能够生成对抗性前缀,并能够控制对抗性token在prompt中的具体位置。
关键创新:该论文最重要的技术创新在于,它将对抗性token的位置作为一个重要的攻击维度引入到大语言模型的安全评估中。以往的研究主要关注对抗性token的内容,而忽略了其位置的影响。该研究表明,即使使用相同的对抗性token,不同的位置也会导致攻击成功率的显著差异。
关键设计:研究中,对抗性token的位置通过调整prompt的结构来控制。例如,可以通过将对抗性token添加到prompt的开头来生成前缀攻击,或者将其插入到prompt的中间位置。此外,研究人员还探索了不同的prompt模板和攻击目标,以评估对抗性token位置对攻击效果的影响。
🖼️ 关键图片
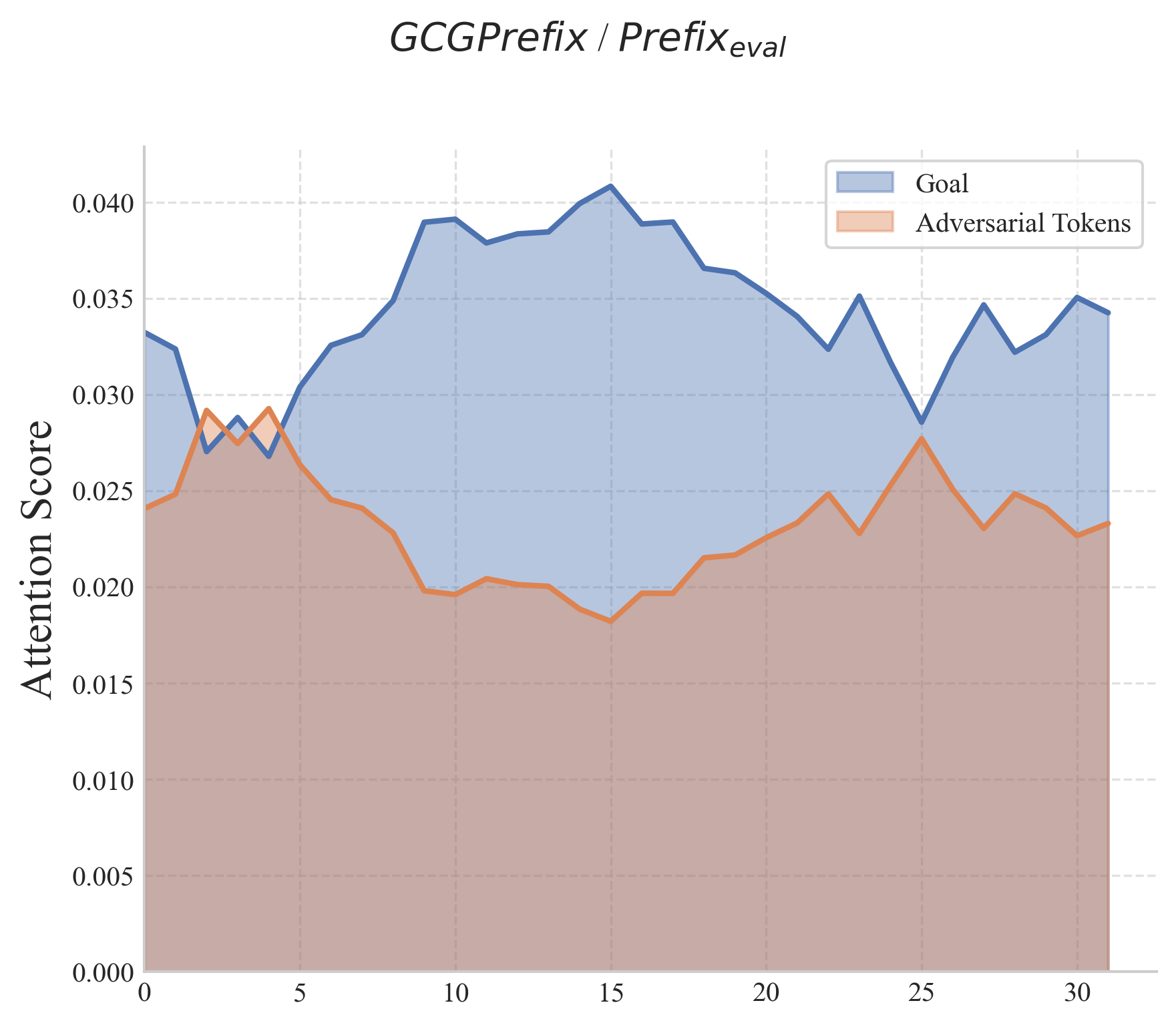
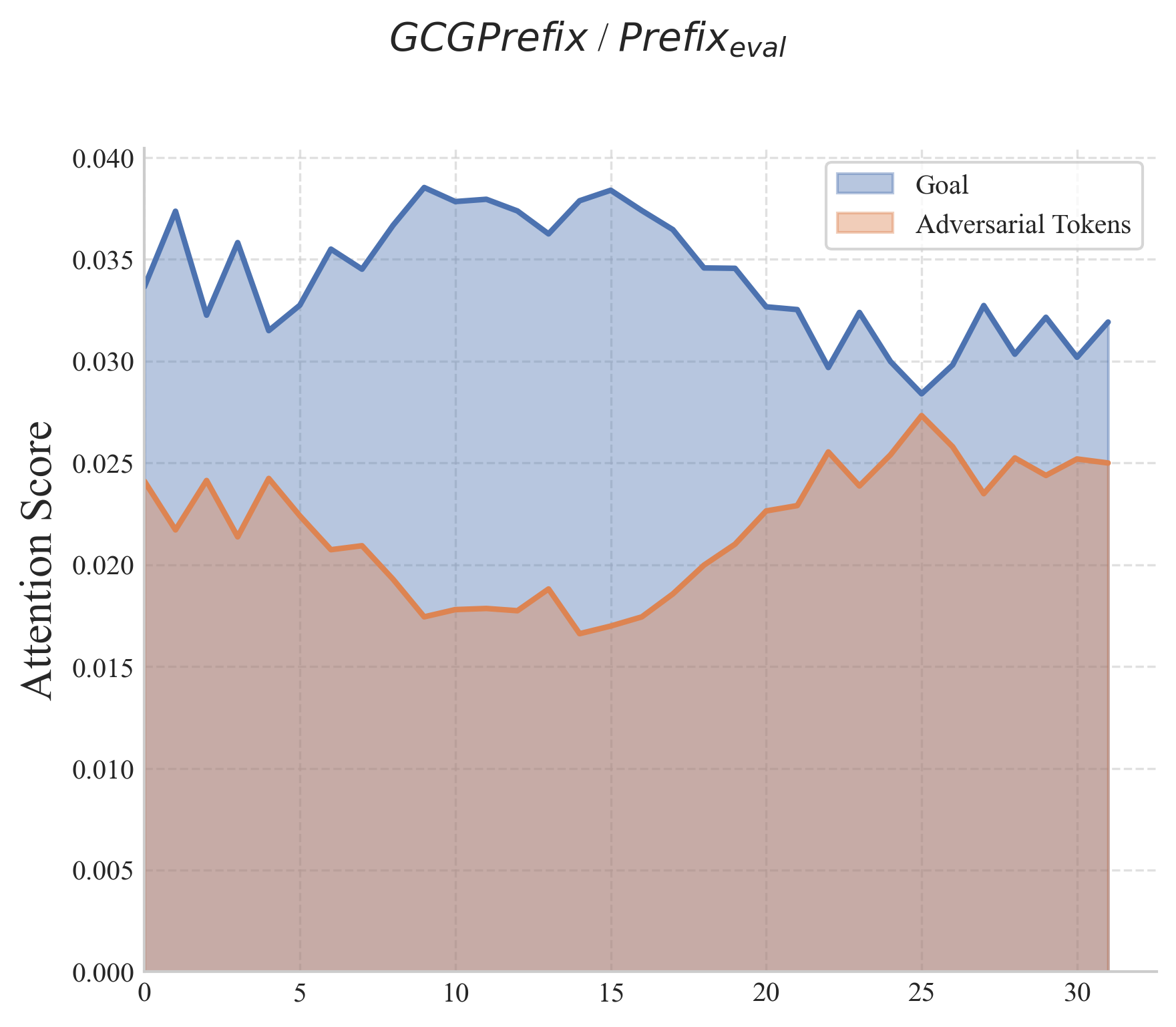
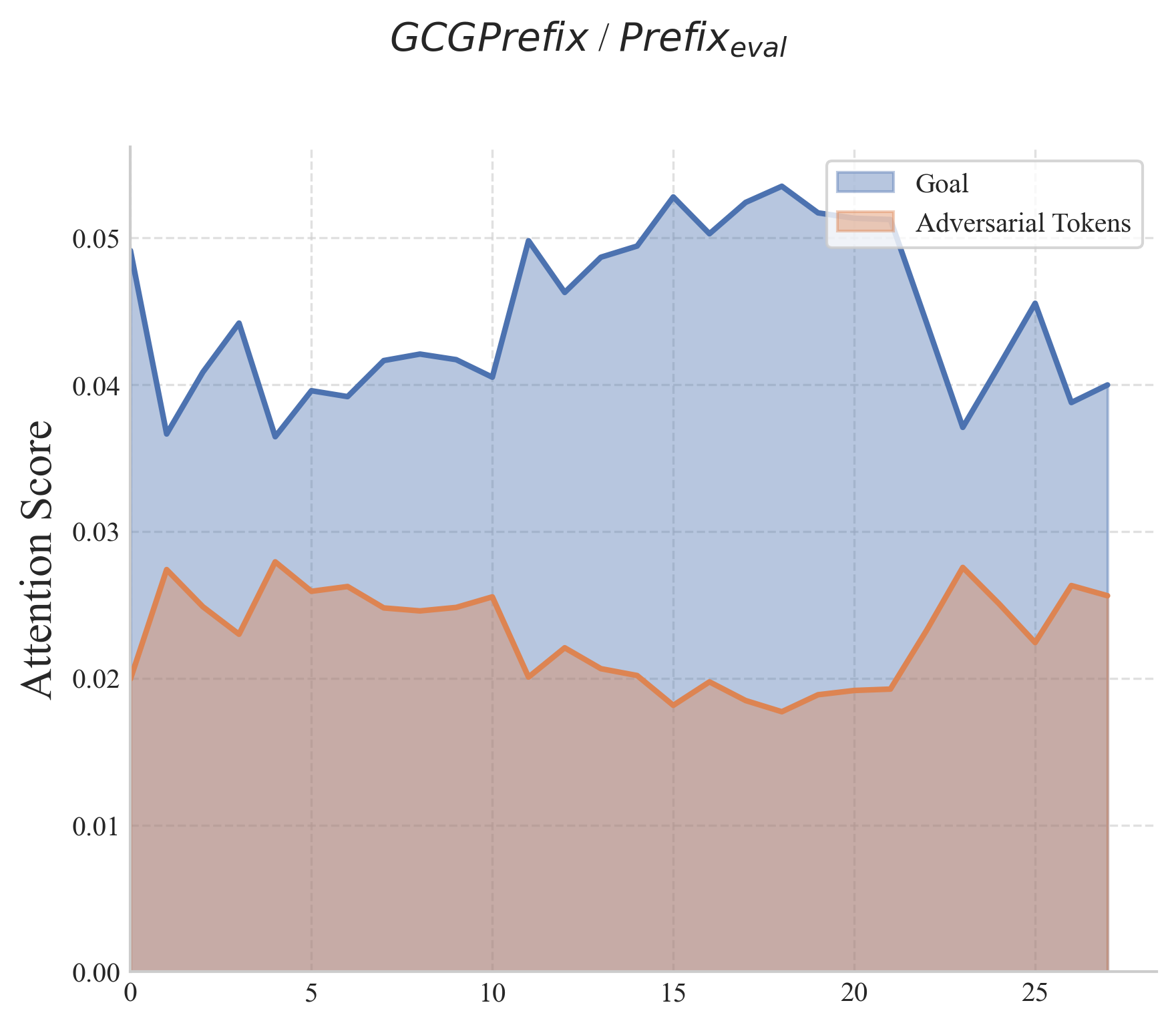
📊 实验亮点
研究表明,将GCG攻击从后缀优化改为前缀优化,可以显著提高攻击成功率。此外,在评估过程中改变对抗性token的位置也会对攻击效果产生重大影响。这些发现强调了当前安全评估中存在的盲点,并表明需要更全面地考虑对抗性token的位置。
🎯 应用场景
该研究成果可应用于大语言模型的安全评估和防御机制设计。通过考虑对抗性token的位置,可以更全面地评估模型的鲁棒性,并开发更有效的防御策略,例如对抗训练和输入过滤。此外,该研究还可以指导prompt工程,帮助用户设计更安全的prompt,避免触发潜在的越狱攻击。
📄 摘要(原文)
Large Language Models (LLMs) have seen widespread adoption across multiple domains, creating an urgent need for robust safety alignment mechanisms. However, robustness remains challenging due to jailbreak attacks that bypass alignment via adversarial prompts. In this work, we focus on the prevalent Greedy Coordinate Gradient (GCG) attack and identify a previously underexplored attack axis in jailbreak attacks typically framed as suffix-based: the placement of adversarial tokens within the prompt. Using GCG as a case study, we show that both optimizing attacks to generate prefixes instead of suffixes and varying adversarial token position during evaluation substantially influence attack success rates. Our findings highlight a critical blind spot in current safety evaluations and underline the need to account for the position of adversarial tokens in the adversarial robustness evaluation of LLMs.