Merging Beyond: Streaming LLM Updates via Activation-Guided Rotations
作者: Yuxuan Yao, Haonan Sheng, Qingsong Lv, Han Wu, Shuqi Liu, Zehua Liu, Zengyan Liu, Jiahui Gao, Haochen Tan, Xiaojin Fu, Haoli Bai, Hing Cheung So, Zhijiang Guo, Linqi Song
分类: cs.LG, cs.CL
发布日期: 2026-02-03
💡 一句话要点
提出基于激活引导旋转的流式LLM更新方法,超越SFT收敛性能
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模型合并 流式学习 激活引导 旋转感知 大语言模型 模型更新 监督微调
📋 核心要点
- 现有模型合并方法难以捕捉监督微调的动态优化优势,通常仅作为事后改进或缓解任务冲突。
- 提出流式合并范式,核心为ARM策略,通过激活引导的旋转来近似梯度下降,实现参数的有效更新。
- 实验表明,ARM仅需SFT早期检查点,即可通过迭代合并超越完全收敛的SFT模型,具有良好的可扩展性。
📝 摘要(中文)
大型语言模型(LLM)规模的不断扩大,需要高效的适应技术。模型合并因其效率和可控性而备受关注。然而,现有的合并技术通常作为事后改进或侧重于减轻任务干扰,往往无法捕捉到监督微调(SFT)的动态优化优势。本文提出了一种创新的模型更新范式——流式合并,将合并概念化为一个迭代优化过程。该范式的核心是ARM(激活引导的旋转感知合并),一种旨在近似梯度下降动态的策略。通过将合并系数视为学习率,并从激活子空间导出旋转向量,ARM有效地沿着数据驱动的轨迹引导参数更新。与传统的线性插值不同,ARM对齐语义子空间,以保持高维参数演化的几何结构。值得注意的是,ARM只需要早期的SFT检查点,并且通过迭代合并,超越了完全收敛的SFT模型。在模型规模(1.7B到14B)和不同领域(例如,数学、代码)的实验结果表明,ARM可以超越收敛的检查点。大量实验表明,ARM为高效的模型适应提供了一个可扩展且轻量级的框架。
🔬 方法详解
问题定义:现有模型合并方法主要存在两个痛点。一是无法充分利用监督微调(SFT)过程中的动态优化信息,二是通常只关注合并后的模型在特定任务上的性能,而忽略了模型参数在高维空间中的演化轨迹。因此,如何设计一种能够有效捕捉SFT动态优化优势,并保持参数演化几何结构的合并方法是本文要解决的问题。
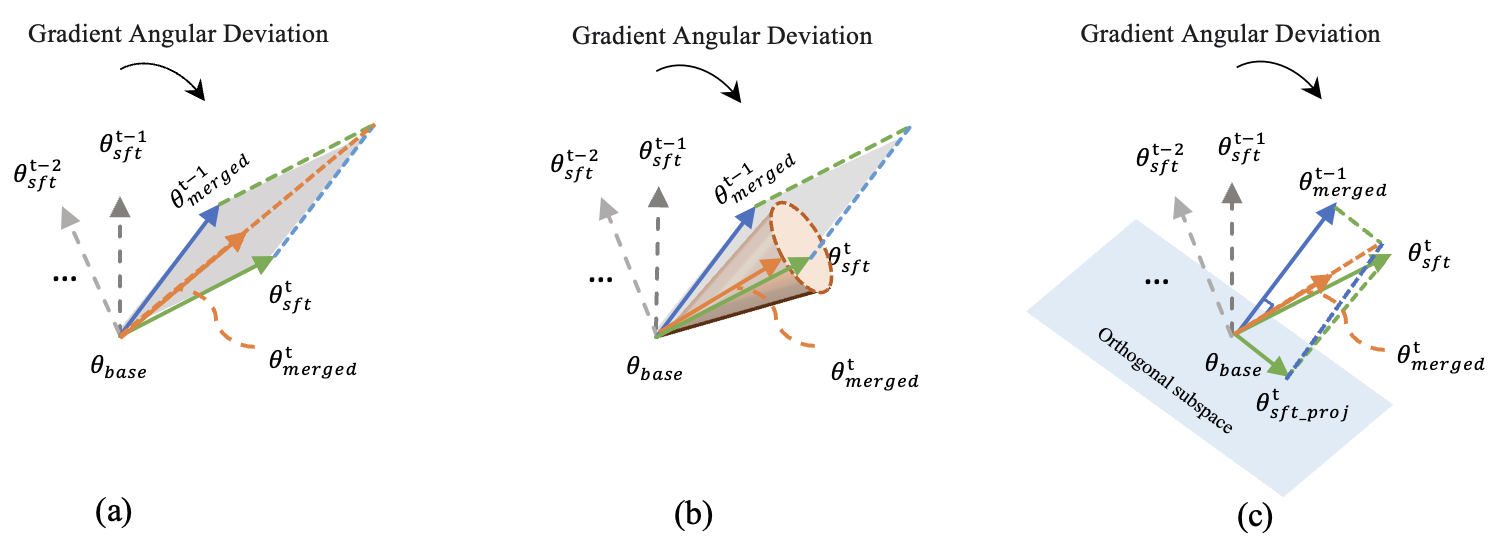
核心思路:本文的核心思路是将模型合并视为一个迭代优化过程,并设计一种能够近似梯度下降动态的合并策略。具体来说,将合并系数类比为学习率,并利用激活子空间的信息来指导参数更新的方向(即旋转向量)。通过这种方式,可以使合并后的模型参数沿着数据驱动的轨迹演化,从而更好地捕捉SFT的优化过程。
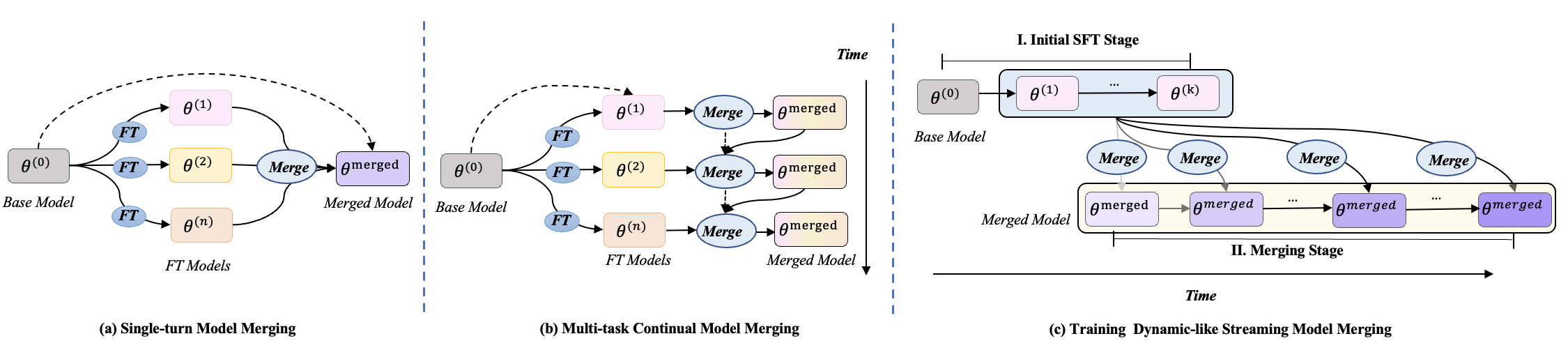
技术框架:流式合并框架主要包含以下几个阶段:1)获取SFT过程中的多个早期检查点;2)计算每个检查点对应的激活子空间;3)利用激活子空间的信息计算旋转向量;4)根据旋转向量和合并系数,迭代更新模型参数。整个过程可以看作是对SFT过程的模拟,通过逐步合并早期检查点的信息,最终得到一个性能优于完全收敛的SFT模型。
关键创新:本文最重要的技术创新点是提出了ARM(激活引导的旋转感知合并)策略。与传统的线性插值方法不同,ARM不仅考虑了模型参数的数值大小,还考虑了参数在激活子空间中的几何关系。通过旋转操作,可以更好地对齐不同模型之间的语义子空间,从而避免了信息损失和负迁移。
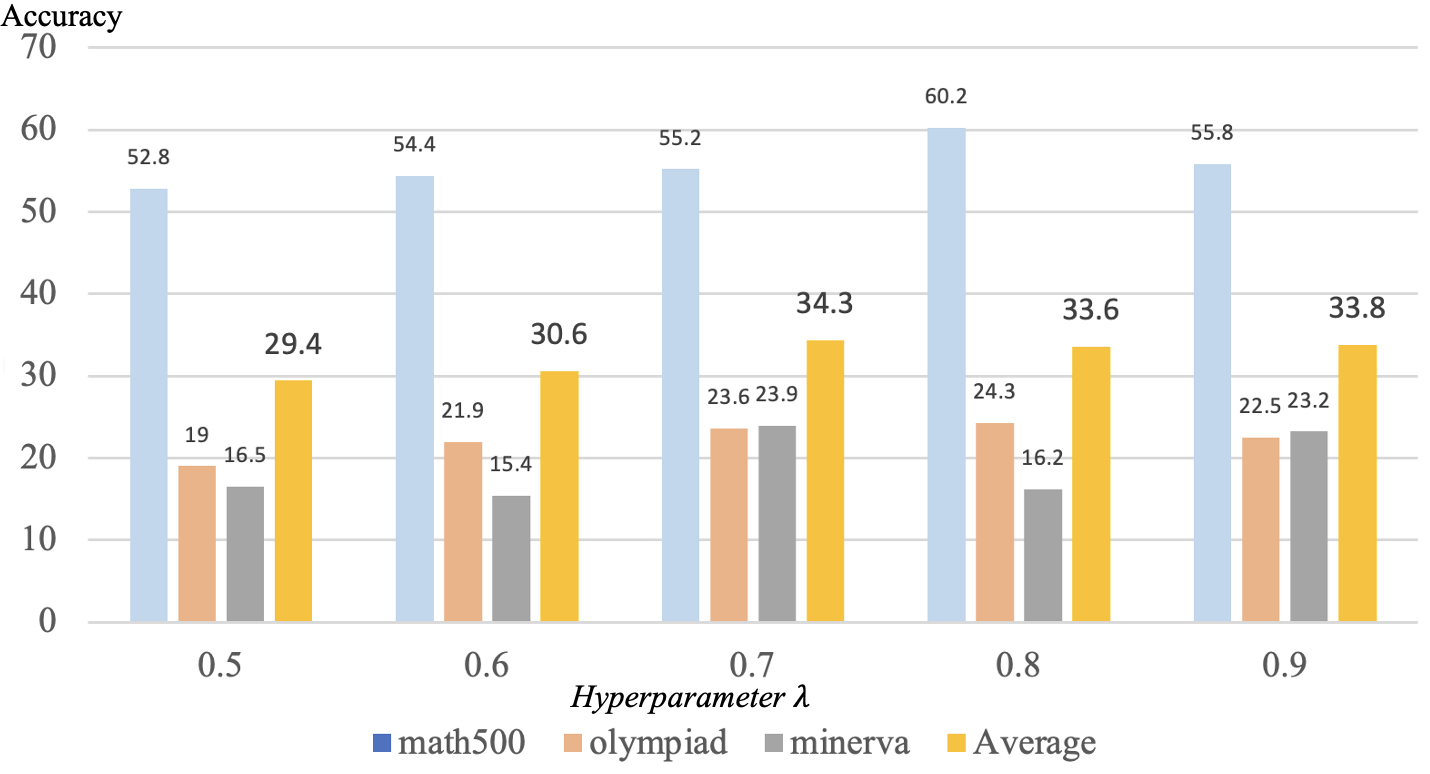
关键设计:ARM的关键设计包括:1)激活子空间的计算方法:论文中具体使用了何种方法来计算激活子空间(例如,主成分分析PCA);2)旋转向量的计算方法:如何利用激活子空间的信息来确定旋转向量的方向和大小;3)合并系数的设置:如何选择合适的合并系数,以保证合并过程的稳定性和收敛性。这些细节决定了ARM的最终性能。
🖼️ 关键图片
📊 实验亮点
实验结果表明,ARM在多个模型规模(1.7B到14B)和不同领域(例如,数学、代码)上均取得了显著的性能提升。特别是在某些任务上,ARM能够超越完全收敛的SFT模型,证明了其有效性和优越性。具体性能数据未知,但强调了ARM超越SFT收敛性能。
🎯 应用场景
该研究成果可应用于快速定制和更新大型语言模型,尤其是在计算资源有限或需要频繁迭代的场景下。例如,可以利用该方法快速将预训练模型适配到特定领域,或者根据用户反馈持续优化模型性能。此外,该方法还可以用于模型压缩和知识迁移等任务,具有广泛的应用前景。
📄 摘要(原文)
The escalating scale of Large Language Models (LLMs) necessitates efficient adaptation techniques. Model merging has gained prominence for its efficiency and controllability. However, existing merging techniques typically serve as post-hoc refinements or focus on mitigating task interference, often failing to capture the dynamic optimization benefits of supervised fine-tuning (SFT). In this work, we propose Streaming Merging, an innovative model updating paradigm that conceptualizes merging as an iterative optimization process. Central to this paradigm is \textbf{ARM} (\textbf{A}ctivation-guided \textbf{R}otation-aware \textbf{M}erging), a strategy designed to approximate gradient descent dynamics. By treating merging coefficients as learning rates and deriving rotation vectors from activation subspaces, ARM effectively steers parameter updates along data-driven trajectories. Unlike conventional linear interpolation, ARM aligns semantic subspaces to preserve the geometric structure of high-dimensional parameter evolution. Remarkably, ARM requires only early SFT checkpoints and, through iterative merging, surpasses the fully converged SFT model. Experimental results across model scales (1.7B to 14B) and diverse domains (e.g., math, code) demonstrate that ARM can transcend converged checkpoints. Extensive experiments show that ARM provides a scalable and lightweight framework for efficient model adaptation.