From Scalar Rewards to Potential Trends: Shaping Potential Landscapes for Model-Based Reinforcement Learning
作者: Yao-Hui Li, Zeyu Wang, Xin Li, Wei Pang, Yingfang Yuan, Zhengkun Chen, Boya Zhang, Riashat Islam, Alex Lamb, Yonggang Zhang
分类: cs.LG
发布日期: 2026-02-03
备注: 26 pages, 20 figures.Preprint. Work in progress
💡 一句话要点
SLOPE:通过塑造潜在趋势,解决基于模型的强化学习在稀疏奖励环境下的难题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 模型强化学习 稀疏奖励 乐观估计 潜在趋势 分布回归
📋 核心要点
- 传统MBRL在稀疏奖励环境下,由于奖励信号稀疏,导致学习到的奖励模型梯度消失,难以指导策略优化。
- SLOPE通过乐观分布回归估计奖励的置信上限,构建信息丰富的潜在landscape,为规划提供方向性指导。
- 实验表明,SLOPE在多种稀疏、半稀疏和密集奖励任务中,显著优于现有MBRL方法,提升了样本效率。
📝 摘要(中文)
基于模型的强化学习(MBRL)通过学习到的动力学和奖励模型模拟未来轨迹,从而实现高样本效率。然而,在稀疏奖励环境中,其有效性会严重降低。核心限制在于回归真实标量奖励的标准范式:在稀疏环境中,这会产生一个平坦、无梯度的landscape,无法为规划提供方向性指导。为了应对这一挑战,我们提出了一种名为“用乐观潜在估计塑造Landscape”(SLOPE)的新框架,该框架将奖励建模从预测标量转变为构建信息丰富的潜在landscape。SLOPE采用乐观分布回归来估计高置信度的上限,从而放大罕见的成功信号,并确保足够的探索梯度。在跨越5个基准的30多个任务上的评估表明,SLOPE在完全稀疏、半稀疏和密集奖励方面始终优于领先的基线。
🔬 方法详解
问题定义:在稀疏奖励的强化学习环境中,基于模型的强化学习方法通常依赖于学习奖励模型来预测未来奖励。然而,当奖励非常稀疏时,学习到的奖励模型往往是平坦的,缺乏有意义的梯度信息,导致策略无法有效地探索和学习。现有的方法难以在这种情况下提供有效的学习信号,从而限制了MBRL的性能。
核心思路:SLOPE的核心思想是将奖励建模从预测标量奖励值转变为构建一个信息丰富的潜在landscape。通过估计奖励的乐观上限,SLOPE旨在放大稀疏的成功信号,并为规划提供更强的探索梯度。这种方法鼓励智能体探索更有可能获得高奖励的区域,从而提高学习效率。
技术框架:SLOPE框架主要包含以下几个模块:1) 动态模型学习:使用标准方法学习环境的动态模型。2) 乐观奖励模型学习:使用乐观分布回归来估计奖励的置信上限,构建潜在landscape。3) 规划:使用学习到的动态模型和乐观奖励模型进行规划,选择能够最大化未来潜在奖励的动作。4) 策略优化:根据规划结果更新策略。
关键创新:SLOPE的关键创新在于使用乐观分布回归来估计奖励的置信上限,从而构建一个信息丰富的潜在landscape。与传统的标量奖励预测相比,这种方法能够更好地处理稀疏奖励环境,并为规划提供更强的探索梯度。通过放大罕见的成功信号,SLOPE鼓励智能体探索更有可能获得高奖励的区域。
关键设计:SLOPE使用分位数回归来估计奖励的分布,并选择一个高分位数作为乐观奖励的估计。具体来说,论文使用了CQR(Conditional Value at Risk Regression)方法来估计条件分位数。损失函数包括动态模型学习的损失和乐观奖励模型学习的损失。网络结构方面,可以使用常见的神经网络结构,如MLP或CNN,具体取决于任务的输入维度。
🖼️ 关键图片
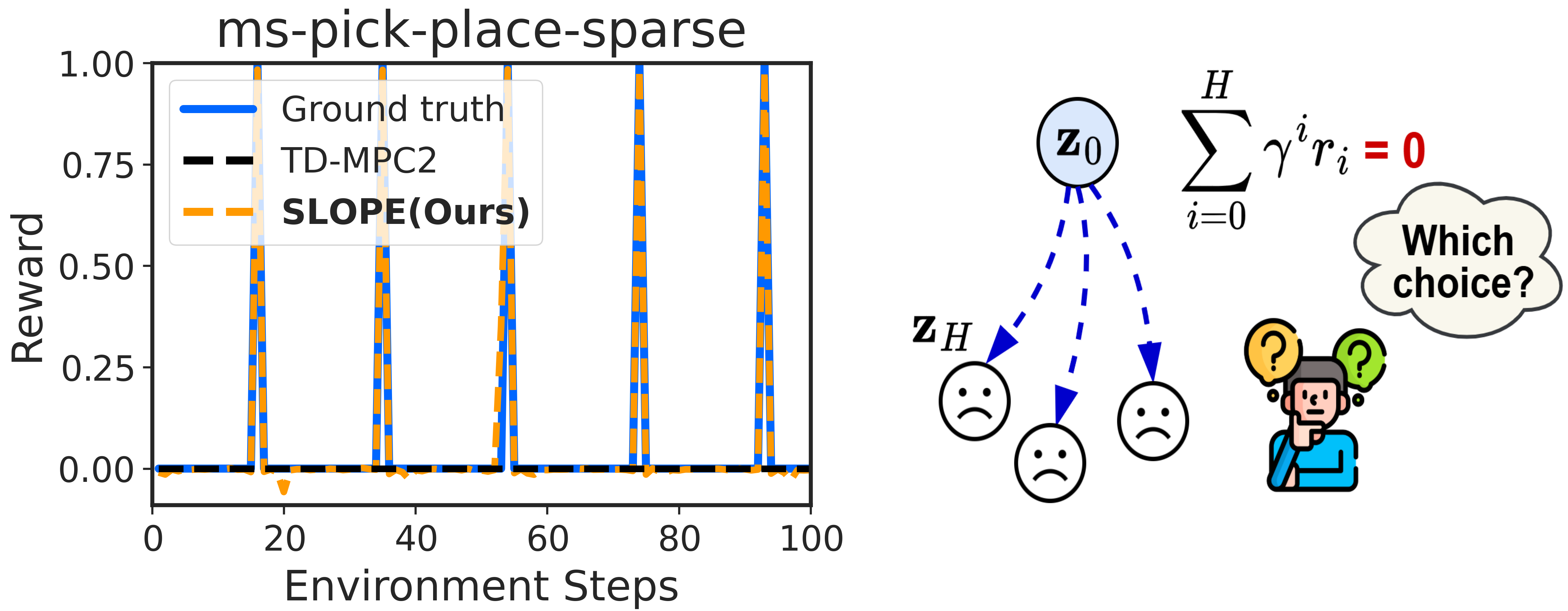


📊 实验亮点
SLOPE在30多个任务上进行了评估,包括MuJoCo、Meta-World等基准测试。实验结果表明,SLOPE在完全稀疏、半稀疏和密集奖励环境下均优于现有的MBRL方法,尤其是在稀疏奖励环境下,性能提升显著。例如,在某些任务上,SLOPE的性能超过了现有方法的两倍以上。
🎯 应用场景
SLOPE方法在机器人控制、游戏AI、自动驾驶等领域具有广泛的应用前景。尤其是在奖励函数难以设计或奖励信号稀疏的复杂环境中,SLOPE能够显著提高强化学习的效率和性能。例如,可以应用于机器人抓取、导航等任务,以及游戏中的探索和策略学习。
📄 摘要(原文)
Model-based reinforcement learning (MBRL) achieves high sample efficiency by simulating future trajectories with learned dynamics and reward models. However, its effectiveness is severely compromised in sparse reward settings. The core limitation lies in the standard paradigm of regressing ground-truth scalar rewards: in sparse environments, this yields a flat, gradient-free landscape that fails to provide directional guidance for planning. To address this challenge, we propose Shaping Landscapes with Optimistic Potential Estimates (SLOPE), a novel framework that shifts reward modeling from predicting scalars to constructing informative potential landscapes. SLOPE employs optimistic distributional regression to estimate high-confidence upper bounds, which amplifies rare success signals and ensures sufficient exploration gradients. Evaluations on 30+ tasks across 5 benchmarks demonstrate that SLOPE consistently outperforms leading baselines in fully sparse, semi-sparse, and dense rewards.