Reinforcement Learning with Promising Tokens for Large Language Models
作者: Jing-Cheng Pang, Liang Lu, Xian Tang, Kun Jiang, Sijie Wu, Kai Zhang, Xubin Li
分类: cs.LG, cs.AI
发布日期: 2026-02-03
💡 一句话要点
提出RLPT框架,通过有希望的tokens进行强化学习,提升LLM推理能力。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 大型语言模型 动作空间缩减 策略优化 推理能力 样本效率 低秩子空间 有希望的tokens
📋 核心要点
- 现有强化学习方法直接在LLM的完整词汇空间进行优化,导致动作空间巨大,包含大量无关tokens,分散了策略的注意力。
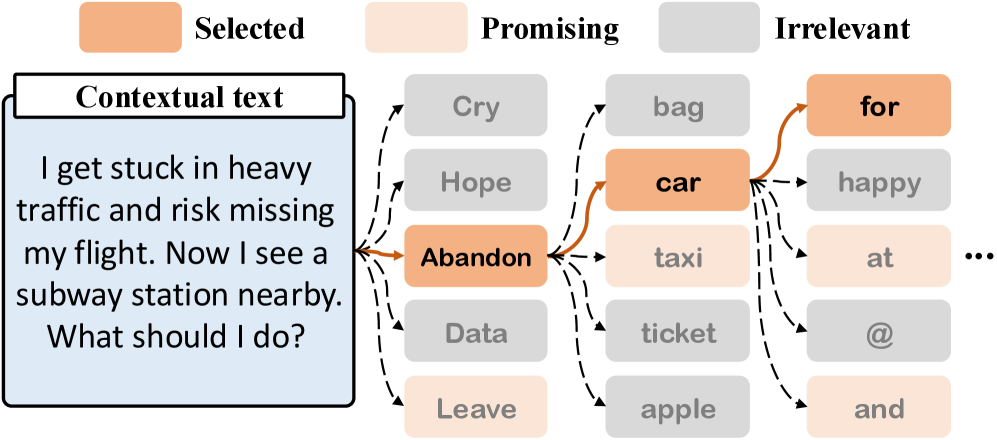
- RLPT框架的核心思想是利用基础模型的语义先验,动态识别并约束策略优化在“有希望的tokens”子集上,从而减小动作空间。
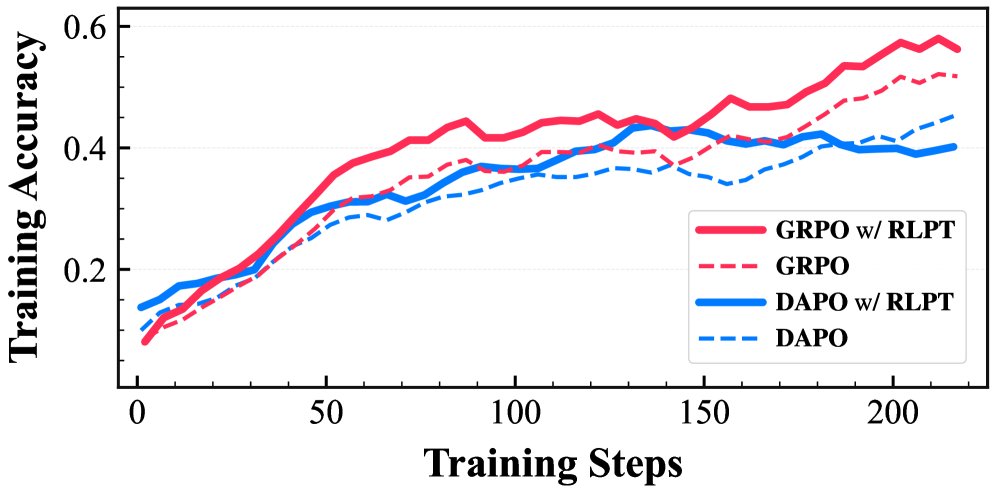
- 实验结果表明,RLPT能有效降低梯度方差,稳定训练过程,提升样本效率,并在数学、编码和电信推理任务上优于标准RL基线。
📝 摘要(中文)
强化学习(RL)已成为对齐和优化大型语言模型(LLM)的关键范式。标准方法将LLM视为策略,并直接在完整的词汇空间上应用RL。然而,这种公式在动作空间中包含了大量上下文无关的tokens,这可能会分散策略对真正合理的tokens进行决策的注意力。本文验证了有效的推理路径可能本质上集中在一个低秩子空间内。基于此,我们提出了基于有希望的tokens的强化学习(RLPT)框架,通过将策略决策与token生成解耦来缓解动作空间问题。具体而言,RLPT利用基础模型的语义先验来识别动态的“有希望的tokens”集合,并通过掩码将策略优化专门限制在这个精炼的子集上。理论分析和实验结果表明,RLPT有效地降低了梯度方差,稳定了训练过程,并提高了样本效率。在数学、编码和电信推理方面的实验结果表明,RLPT优于标准RL基线,并有效地集成了各种模型大小(4B和8B)和RL算法(GRPO和DAPO)。
🔬 方法详解
问题定义:现有基于强化学习的LLM优化方法,直接在整个词表空间进行策略学习,导致动作空间过大,其中包含大量与当前上下文无关的token。这些无关token会引入噪声,增加策略学习的难度,降低训练效率,并可能导致模型性能下降。现有方法的痛点在于无法有效区分和利用对推理过程真正有帮助的token。
核心思路:论文的核心思路是观察到有效的推理路径通常集中在一个低秩子空间中,即只有一小部分token对于生成合理的答案是重要的。因此,可以通过缩小动作空间,只关注这些“有希望的tokens”,来提高强化学习的效率和效果。这样可以减少策略学习的搜索空间,降低梯度方差,并使模型更容易学习到有效的策略。
技术框架:RLPT框架主要包含以下几个阶段: 1. Promising Token Identification(有希望的Token识别):利用基础LLM的语义先验知识,为每个上下文动态地识别出一组“有希望的tokens”。这可以通过计算每个token的概率分布,并选择概率较高的token来实现。 2. Policy Optimization with Masking(带掩码的策略优化):在强化学习过程中,使用掩码机制将策略优化限制在识别出的“有希望的tokens”集合上。这意味着策略只能选择这些token作为动作,从而避免了在整个词表空间进行搜索。 3. Reward Shaping(奖励塑造):使用合适的奖励函数来引导模型学习生成高质量的推理结果。
关键创新:RLPT的关键创新在于将策略决策与token生成解耦,通过动态识别“有希望的tokens”来缩小动作空间。与传统的直接在整个词表空间进行强化学习的方法相比,RLPT能够更有效地利用计算资源,提高训练效率,并获得更好的性能。这种方法避免了对大量无关token的探索,使模型能够更专注于学习有效的推理策略。
关键设计: * Promising Token Selection Criteria(有希望的Token选择标准):论文可能使用了top-k概率选择或者基于阈值的选择方法来确定“有希望的tokens”集合的大小。 * Masking Implementation(掩码实现):在策略网络中,对不在“有希望的tokens”集合中的token进行掩码,使其概率为零。 * Reward Function Design(奖励函数设计):奖励函数的设计需要与具体的任务目标相匹配,例如,在数学推理任务中,可以使用答案的正确性作为奖励信号。
🖼️ 关键图片

📊 实验亮点
实验结果表明,RLPT在数学、编码和电信推理任务上均优于标准RL基线。具体而言,RLPT在不同模型大小(4B和8B)和RL算法(GRPO和DAPO)上均表现出良好的性能。例如,在数学推理任务上,RLPT可能取得了显著的准确率提升,并且训练过程更加稳定,收敛速度更快。这些结果验证了RLPT框架的有效性和通用性。
🎯 应用场景
RLPT框架具有广泛的应用前景,可以应用于各种需要LLM进行推理和决策的任务中,例如数学问题求解、代码生成、对话系统、智能客服等。通过提高LLM的推理能力和效率,RLPT可以帮助开发更智能、更可靠的AI系统,并提升用户体验。该方法还有潜力应用于其他序列生成任务,例如机器翻译和文本摘要。
📄 摘要(原文)
Reinforcement learning (RL) has emerged as a key paradigm for aligning and optimizing large language models (LLMs). Standard approaches treat the LLM as the policy and apply RL directly over the full vocabulary space. However, this formulation includes the massive tail of contextually irrelevant tokens in the action space, which could distract the policy from focusing on decision-making among the truly reasonable tokens. In this work, we verify that valid reasoning paths could inherently concentrate within a low-rank subspace. Based on this insight, we introduce Reinforcement Learning with Promising Tokens (RLPT), a framework that mitigates the action space issue by decoupling strategic decision-making from token generation. Specifically, RLPT leverages the semantic priors of the base model to identify a dynamic set of \emph{promising tokens} and constrains policy optimization exclusively to this refined subset via masking. Theoretical analysis and empirical results demonstrate that RLPT effectively reduces gradient variance, stabilizes the training process, and improves sample efficiency. Experiment results on math, coding, and telecom reasoning show that RLPT outperforms standard RL baselines and integrates effectively across various model sizes (4B and 8B) and RL algorithms (GRPO and DAPO).