Prompt Augmentation Scales up GRPO Training on Mathematical Reasoning
作者: Wenquan Lu, Hai Huang, Randall Balestriero
分类: cs.LG, cs.AI, cs.CL
发布日期: 2026-02-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出Prompt Augmentation,稳定扩展GRPO在数学推理上的训练,显著提升模型性能。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Prompt Augmentation 群体相对策略优化 强化学习 数学推理 语言模型
📋 核心要点
- 现有基于GRPO的数学推理模型训练易发生熵崩溃,限制了训练时长和性能提升。
- Prompt Augmentation通过增加prompt的多样性,提升rollout的多样性,从而稳定训练过程。
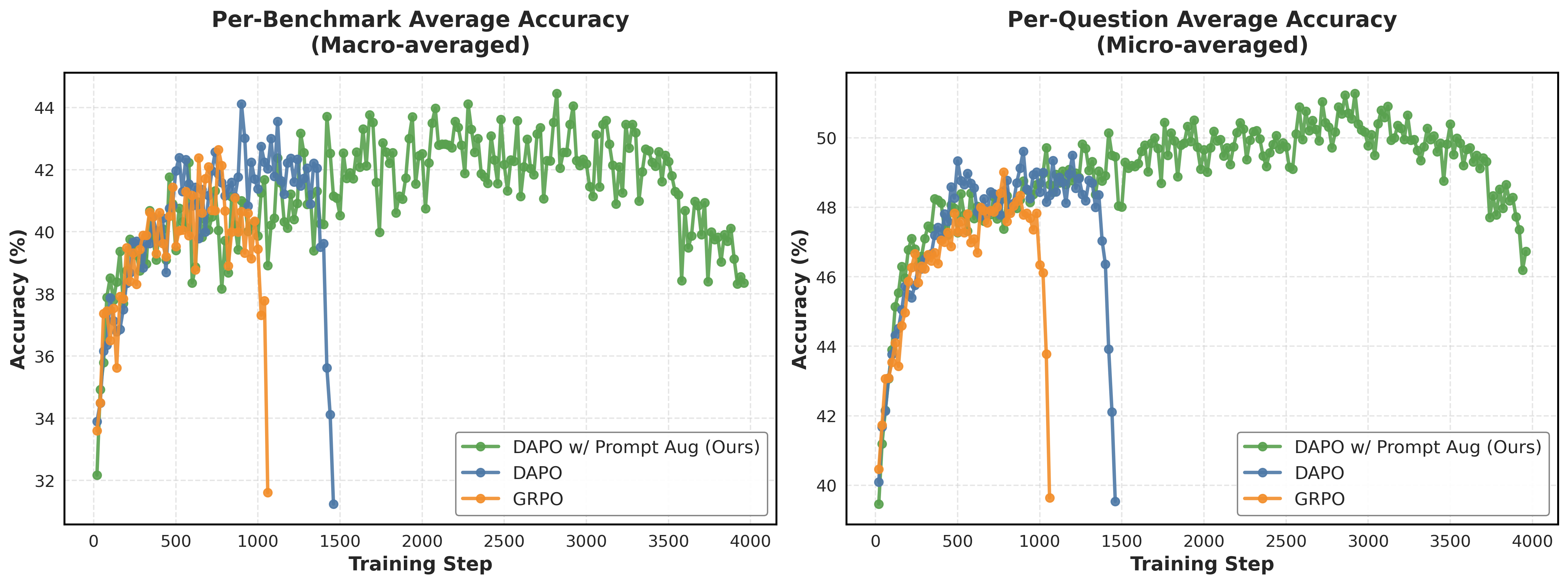
- 实验表明,该方法在数学推理基准测试中取得了SOTA结果,显著提升了模型性能。
📝 摘要(中文)
本文提出了一种名为Prompt Augmentation的训练策略,旨在解决基于群体相对策略优化(GRPO)的强化学习算法在提升大型语言模型数学推理能力时遇到的熵崩溃问题。以往研究发现,强化后训练期间策略熵单调递减,导致训练不稳定和崩溃,限制了训练时长和策略改进。Prompt Augmentation通过指示模型在不同的模板和格式下生成推理轨迹,从而增加rollout的多样性。实验结果表明,在固定数据集上,该方法无需KL正则化项即可稳定扩展训练时长,并允许模型在低熵状态下保持稳定。使用Prompt Augmentation训练的Qwen2.5-Math-1.5B模型在MATH Level 3-5数据集上达到了最先进的性能,在AIME24、AMC、MATH500、Minerva和OlympiadBench等标准数学推理基准测试中,分别达到了44.5%的单基准准确率和51.3%的单问题准确率。
🔬 方法详解
问题定义:现有基于GRPO的数学推理模型在训练过程中,普遍存在熵崩溃现象,即策略熵单调下降,最终导致训练不稳定甚至崩溃。这限制了模型的训练时长,无法充分探索策略空间,阻碍了模型性能的进一步提升。此外,以往工作通常依赖于单一固定的推理prompt或模板,限制了模型学习的多样性。
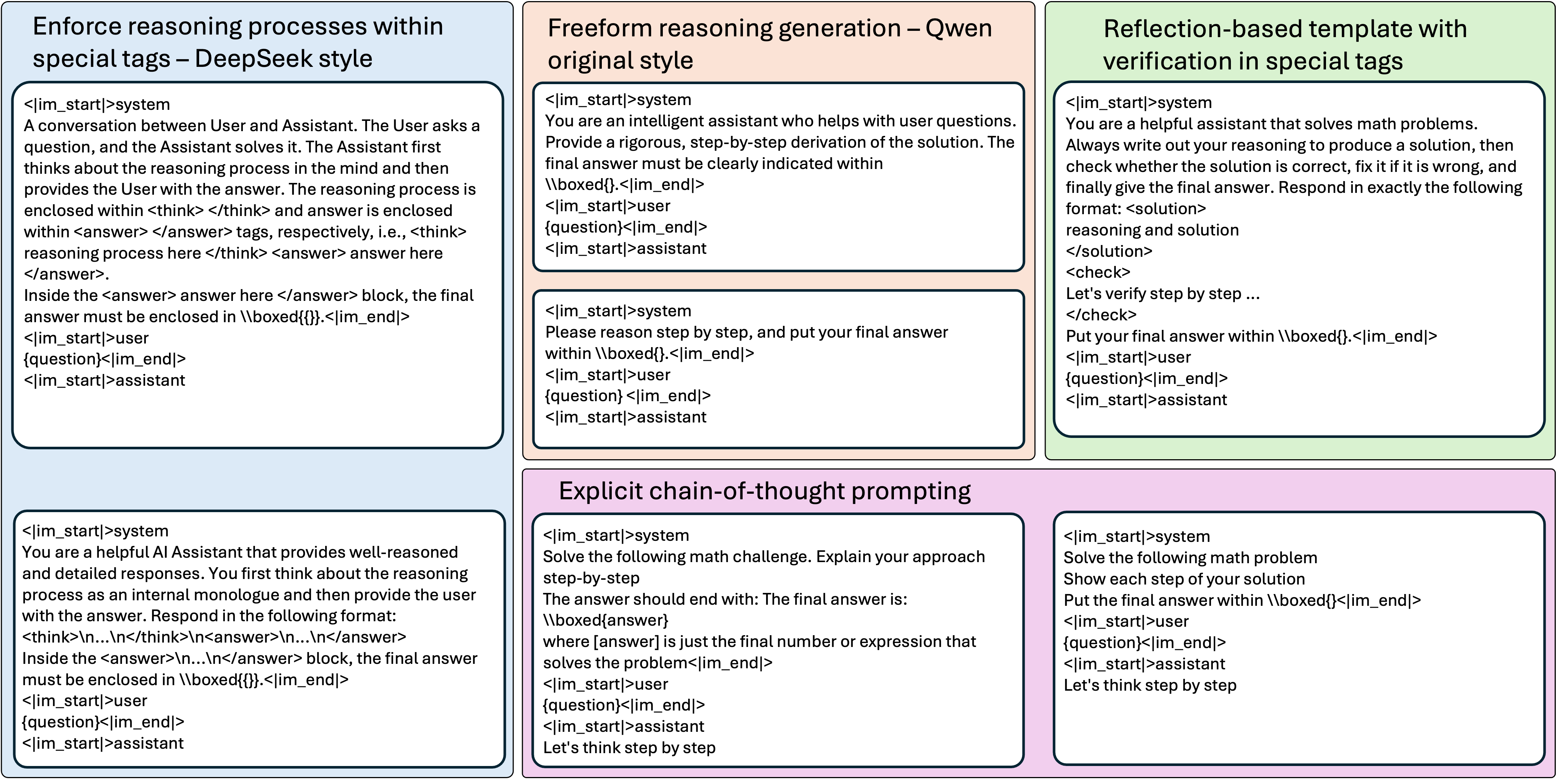
核心思路:本文的核心思路是通过Prompt Augmentation增加训练数据的多样性,从而缓解熵崩溃问题。具体来说,就是让模型在训练过程中接触到不同的prompt模板和格式,鼓励模型学习在不同prompt下进行推理,从而提升模型的泛化能力和鲁棒性。这种方式可以有效增加rollout的多样性,避免模型过拟合到单一prompt上。
技术框架:该方法主要是在GRPO训练框架中引入Prompt Augmentation模块。整体流程如下:首先,使用不同的prompt模板生成训练数据;然后,利用这些数据训练语言模型,使其能够根据不同的prompt生成推理轨迹;最后,使用GRPO算法对模型进行强化学习,优化模型的推理策略。关键在于prompt的生成和选择策略,需要保证prompt的多样性和有效性。
关键创新:最重要的技术创新点在于Prompt Augmentation本身,它通过增加prompt的多样性来提升模型的泛化能力和鲁棒性,从而缓解熵崩溃问题。与现有方法相比,该方法不需要依赖KL正则化项,就可以稳定扩展训练时长,允许模型在低熵状态下保持稳定。这使得模型可以进行更充分的探索,从而获得更好的性能。
关键设计:Prompt Augmentation的关键设计在于如何生成和选择prompt。具体来说,可以采用以下策略:1) 从预定义的prompt模板库中随机选择prompt;2) 使用语言模型自动生成prompt;3) 人工设计prompt。在选择prompt时,可以根据prompt的难度、多样性等指标进行筛选。此外,还可以设计一些特殊的prompt,例如包含错误信息的prompt,以增强模型的鲁棒性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,使用Prompt Augmentation训练的Qwen2.5-Math-1.5B模型在MATH Level 3-5数据集上达到了最先进的性能,在AIME24、AMC、MATH500、Minerva和OlympiadBench等标准数学推理基准测试中,分别达到了44.5%的单基准准确率和51.3%的单问题准确率。这表明Prompt Augmentation可以显著提升模型在数学推理任务上的性能。
🎯 应用场景
该研究成果可广泛应用于需要复杂推理能力的自然语言处理任务中,例如数学问题求解、代码生成、知识图谱推理等。通过Prompt Augmentation,可以有效提升模型在这些任务上的性能和鲁棒性,使其能够更好地应对实际应用中的各种挑战。此外,该方法还可以应用于其他强化学习任务中,以缓解熵崩溃问题,提升模型的训练效率和性能。
📄 摘要(原文)
Reinforcement learning algorithms such as group-relative policy optimization (GRPO) have demonstrated strong potential for improving the mathematical reasoning capabilities of large language models. However, prior work has consistently observed an entropy collapse phenomenon during reinforcement post-training, characterized by a monotonic decrease in policy entropy that ultimately leads to training instability and collapse. As a result, most existing approaches restrict training to short horizons (typically 5-20 epochs), limiting sustained exploration and hindering further policy improvement. In addition, nearly all prior work relies on a single, fixed reasoning prompt or template during training. In this work, we introduce prompt augmentation, a training strategy that instructs the model to generate reasoning traces under diverse templates and formats, thereby increasing rollout diversity. We show that, without a KL regularization term, prompt augmentation enables stable scaling of training duration under a fixed dataset and allows the model to tolerate low-entropy regimes without premature collapse. Empirically, a Qwen2.5-Math-1.5B model trained with prompt augmentation on the MATH Level 3-5 dataset achieves state-of-the-art performance, reaching 44.5 per-benchmark accuracy and 51.3 per-question accuracy on standard mathematical reasoning benchmarks, including AIME24, AMC, MATH500, Minerva, and OlympiadBench. The code and model checkpoints are available at https://github.com/wenquanlu/prompt-augmentation-GRPO.