DynSplit-KV: Dynamic Semantic Splitting for KVCache Compression in Efficient Long-Context LLM Inference
作者: Jiancai Ye, Jun Liu, Qingchen Li, Tianlang Zhao, Hanbin Zhang, Jiayi Pan, Ningyi Xu, Guohao Dai
分类: cs.LG, cs.CL
发布日期: 2026-02-03
💡 一句话要点
DynSplit-KV:针对长文本LLM推理,提出动态语义分割的KVCache压缩方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: KVCache压缩 长文本LLM 动态语义分割 大语言模型推理 内存优化
📋 核心要点
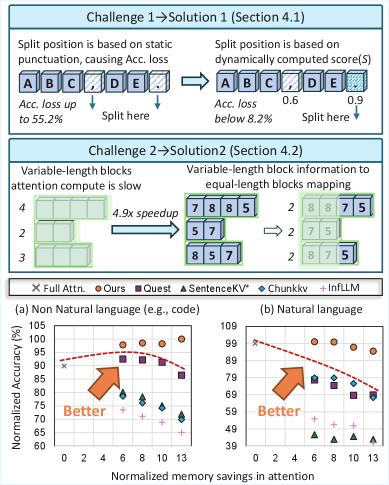
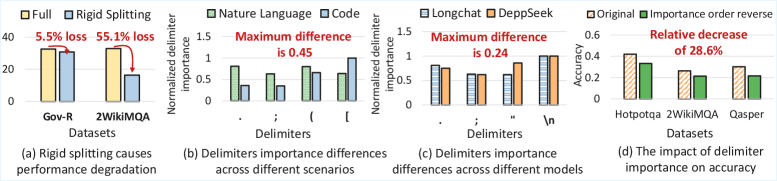
- 现有KVCache压缩方法采用固定分割策略,导致语义不对齐,精度显著下降,无法适应不同场景。
- DynSplit-KV通过动态选择重要性感知的分割符,并采用统一映射策略,将变长语义块转换为固定长度格式。
- 实验结果表明,DynSplit-KV在长文本场景中实现了最高的精度,并显著提升了推理速度和降低了峰值内存占用。
📝 摘要(中文)
Key-Value (KV) Cache对于高效的大语言模型(LLM)推理至关重要,但其在长文本场景中不断增长的内存占用构成了一个显著瓶颈,使得KVCache压缩变得至关重要。现有的压缩方法依赖于刚性的分割策略,例如固定间隔或预定义的分割符。我们观察到,由于语义边界的场景依赖性,刚性分割会导致显著的精度下降(范围从5.5%到55.1%)。这突出了动态语义分割以匹配语义的必要性。为了实现这一点,我们面临两个挑战。(1) 不正确的分割符选择会使语义与KVCache不对齐,导致28.6%的精度损失。(2) 分割后的变长块引入了超过73.1%的额外推理开销。为了解决上述挑战,我们提出了DynSplit-KV,一种动态识别分割符的KVCache压缩方法。我们提出:(1) 一种动态的重要性感知分割符选择策略,将精度提高了49.9%。(2) 一种统一的映射策略,将变长语义块转换为固定长度格式,从而将推理开销降低了4.9倍。实验表明,在长文本场景中,DynSplit-KV实现了最高的精度,与FlashAttention相比,速度提高了2.2倍,峰值内存减少了2.6倍。
🔬 方法详解
问题定义:论文旨在解决长文本LLM推理中,KVCache因内存占用过大而导致的推理效率瓶颈问题。现有KVCache压缩方法采用固定或预定义的分割策略,无法有效捕捉语义边界,导致压缩后精度显著下降,且变长分割块引入了额外的推理开销。
核心思路:论文的核心思路是动态地根据语义信息选择KVCache的分割点,并采用统一映射策略将变长语义块转换为固定长度格式。通过动态分割,使KVCache的分割与语义边界对齐,从而提高压缩后的精度。通过统一映射,消除变长块带来的额外推理开销。
技术框架:DynSplit-KV主要包含两个阶段:动态重要性感知分割符选择和统一映射。首先,通过动态重要性感知分割符选择策略,识别出合适的分割符,将KVCache分割成多个语义相关的变长块。然后,利用统一映射策略,将这些变长块转换为固定长度的格式,以便进行高效的推理。
关键创新:DynSplit-KV的关键创新在于动态重要性感知分割符选择策略和统一映射策略。动态重要性感知分割符选择策略能够根据上下文信息动态地选择分割符,从而使KVCache的分割与语义边界对齐。统一映射策略能够将变长语义块转换为固定长度格式,从而消除变长块带来的额外推理开销。与现有方法相比,DynSplit-KV能够更有效地压缩KVCache,同时保持较高的精度和推理效率。
关键设计:动态重要性感知分割符选择策略可能涉及到对每个token的重要性进行评估,例如通过attention score或者其他指标。然后,根据这些重要性得分,选择合适的token作为分割符。统一映射策略可能涉及到对变长块进行填充或者截断,使其达到统一的长度。具体的参数设置,例如重要性评估的阈值、填充/截断的长度等,需要在实验中进行调整。
🖼️ 关键图片

📊 实验亮点
DynSplit-KV在长文本场景中实现了显著的性能提升。实验结果表明,DynSplit-KV相比于FlashAttention,速度提高了2.2倍,峰值内存减少了2.6倍。同时,DynSplit-KV通过动态重要性感知分割符选择策略,将精度提高了49.9%。这些结果表明,DynSplit-KV是一种高效且精确的KVCache压缩方法。
🎯 应用场景
DynSplit-KV可应用于各种需要处理长文本的大语言模型推理场景,例如长篇文档摘要、机器翻译、对话系统等。通过降低内存占用和提高推理速度,DynSplit-KV能够支持更大规模的模型和更长的上下文,从而提升LLM在实际应用中的性能和效率。该研究对于推动LLM在资源受限设备上的部署具有重要意义。
📄 摘要(原文)
Although Key-Value (KV) Cache is essential for efficient large language models (LLMs) inference, its growing memory footprint in long-context scenarios poses a significant bottleneck, making KVCache compression crucial. Current compression methods rely on rigid splitting strategies, such as fixed intervals or pre-defined delimiters. We observe that rigid splitting suffers from significant accuracy degradation (ranging from 5.5% to 55.1%) across different scenarios, owing to the scenario-dependent nature of the semantic boundaries. This highlights the necessity of dynamic semantic splitting to match semantics. To achieve this, we face two challenges. (1) Improper delimiter selection misaligns semantics with the KVCache, resulting in 28.6% accuracy loss. (2) Variable-length blocks after splitting introduce over 73.1% additional inference overhead. To address the above challenges, we propose DynSplit-KV, a KVCache compression method that dynamically identifies delimiters for splitting. We propose: (1) a dynamic importance-aware delimiter selection strategy, improving accuracy by 49.9%. (2) A uniform mapping strategy that transforms variable-length semantic blocks into a fixed-length format, reducing inference overhead by 4.9x. Experiments show that DynSplit-KV achieves the highest accuracy, 2.2x speedup compared with FlashAttention and 2.6x peak memory reduction in long-context scenarios.