StepScorer: Accelerating Reinforcement Learning with Step-wise Scoring and Psychological Regret Modeling
作者: Zhe Xu
分类: cs.LG
发布日期: 2026-02-03
备注: 10 pages, 5 figures, 1 table
💡 一句话要点
提出基于心理后悔模型的强化学习加速方法,解决稀疏奖励下的收敛难题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 稀疏奖励 心理后悔模型 策略优化 连续控制
📋 核心要点
- 强化学习在稀疏奖励环境中收敛缓慢,是由于缺乏有效的中间反馈信号。
- 论文提出心理后悔模型(PRM),通过计算每一步的后悔值来提供密集的反馈信号,加速学习过程。
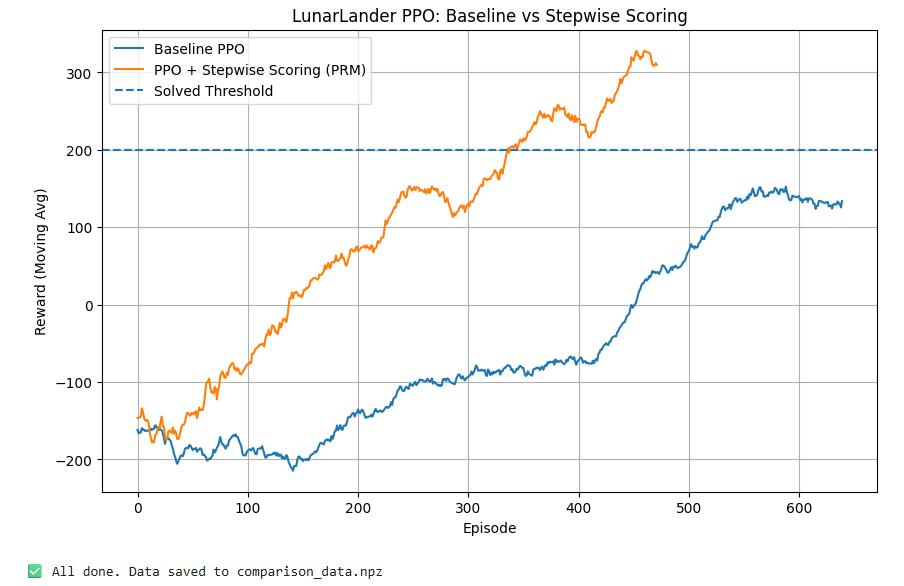
- 实验结果表明,PRM在Lunar Lander等环境中比PPO算法收敛速度提升约36%,尤其适用于连续控制任务。
📝 摘要(中文)
强化学习算法常常因奖励信号稀疏而收敛缓慢,尤其是在反馈延迟或不频繁的复杂环境中。本文提出了一种新的心理后悔模型(PRM),该模型通过在每个决策步骤后加入基于后悔的反馈信号来加速学习。PRM不是等待最终奖励,而是计算每个状态下最优动作的期望值与实际采取动作的价值之间的差异,从而产生后悔信号。这种方法通过逐步评分框架将稀疏奖励转化为密集反馈信号,从而实现更快的收敛。实验表明,在Lunar Lander等基准环境中,PRM的性能比传统的近端策略优化(PPO)算法稳定约36%。结果表明,PRM在连续控制任务和具有延迟反馈的环境中特别有效,使其适用于机器人、金融和自适应教育等需要快速策略适应的实际应用。该方法将受人类启发反事实思维形式化为可计算的后悔信号,从而连接了行为经济学和强化学习。
🔬 方法详解
问题定义:强化学习在奖励稀疏的环境中面临收敛速度慢的挑战。传统方法依赖于最终奖励来更新策略,导致学习效率低下,尤其是在复杂环境中,智能体需要探索很长时间才能获得有意义的反馈。现有的方法难以有效利用每一步的决策信息,造成了大量的时间和资源浪费。
核心思路:论文的核心思路是借鉴人类的后悔心理,在每一步决策后,计算智能体采取的动作与最优动作之间的价值差异,并将这个差异作为一种后悔信号。这个后悔信号可以作为一种密集的反馈,指导智能体更快地学习。通过将稀疏的最终奖励转化为密集的逐步后悔信号,可以显著加速强化学习的收敛速度。
技术框架:PRM的核心框架是在传统的强化学习算法(如PPO)的基础上,增加了一个后悔计算模块。该模块在每一步计算智能体采取的动作的价值,并估计最优动作的价值。两者之间的差异就是后悔值。这个后悔值被用作额外的奖励信号,与环境提供的奖励信号结合,共同用于更新策略。整体流程包括:状态观测、动作选择、环境交互、奖励获取、后悔计算、策略更新。
关键创新:PRM最重要的创新点在于将心理学中的后悔概念引入强化学习,并将其形式化为可计算的后悔信号。与传统的只依赖最终奖励的强化学习方法不同,PRM能够利用每一步的决策信息,提供更密集的反馈。这种方法能够有效地解决稀疏奖励问题,加速学习过程。
关键设计:PRM的关键设计包括:1) 如何准确估计最优动作的价值。论文可能采用了诸如Q-learning或Actor-Critic等方法来估计动作价值。2) 如何平衡环境奖励和后悔信号的权重。需要仔细调整这两个信号的比例,以避免后悔信号过度影响策略学习。3) 如何将后悔信号融入现有的强化学习算法中。例如,可以将后悔信号直接加到环境奖励上,或者将其作为额外的损失函数来优化策略。
🖼️ 关键图片
📊 实验亮点
实验结果表明,PRM在Lunar Lander等基准环境中比传统的PPO算法收敛速度提升约36%。这意味着在相同的训练时间内,PRM能够获得更高的性能。此外,PRM在连续控制任务和具有延迟反馈的环境中表现出更强的优势,表明其具有良好的泛化能力。这些结果验证了PRM在解决稀疏奖励问题方面的有效性。
🎯 应用场景
PRM适用于奖励稀疏且需要快速策略适应的领域,如机器人控制、金融交易和自适应教育。在机器人控制中,机器人可以通过后悔信号更快地学习复杂的动作序列。在金融交易中,交易员可以根据后悔信号调整交易策略,以获得更高的收益。在自适应教育中,系统可以根据学生的后悔信号调整教学内容,以提高学习效率。该研究有望推动强化学习在实际应用中的广泛应用。
📄 摘要(原文)
Reinforcement learning algorithms often suffer from slow convergence due to sparse reward signals, particularly in complex environments where feedback is delayed or infrequent. This paper introduces the Psychological Regret Model (PRM), a novel approach that accelerates learning by incorporating regret-based feedback signals after each decision step. Rather than waiting for terminal rewards, PRM computes a regret signal based on the difference between the expected value of the optimal action and the value of the action taken in each state. This transforms sparse rewards into dense feedback signals through a step-wise scoring framework, enabling faster convergence. We demonstrate that PRM achieves stable performance approximately 36\% faster than traditional Proximal Policy Optimization (PPO) in benchmark environments such as Lunar Lander. Our results indicate that PRM is particularly effective in continuous control tasks and environments with delayed feedback, making it suitable for real-world applications such as robotics, finance, and adaptive education where rapid policy adaptation is critical. The approach formalizes human-inspired counterfactual thinking as a computable regret signal, bridging behavioral economics and reinforcement learning.