Self-Hinting Language Models Enhance Reinforcement Learning
作者: Baohao Liao, Hanze Dong, Xinxing Xu, Christof Monz, Jiang Bian
分类: cs.LG, cs.AI, cs.CL, stat.ML
发布日期: 2026-02-03
🔗 代码/项目: GITHUB
💡 一句话要点
提出自提示对齐GRPO以解决稀疏奖励问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 语言模型 自提示机制 群体相对策略优化 稀疏奖励
📋 核心要点
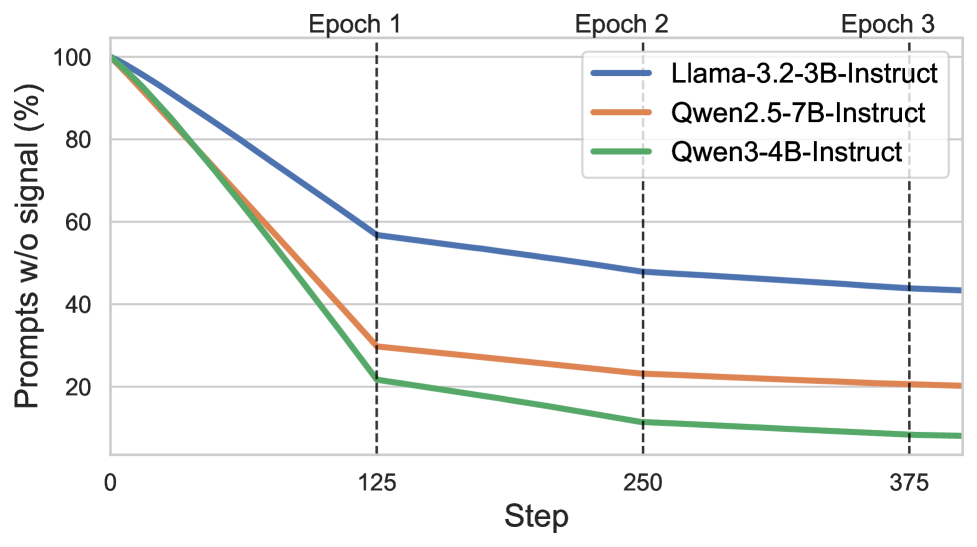
- 现有的GRPO方法在稀疏奖励环境中容易停滞,导致模型更新效果不佳。
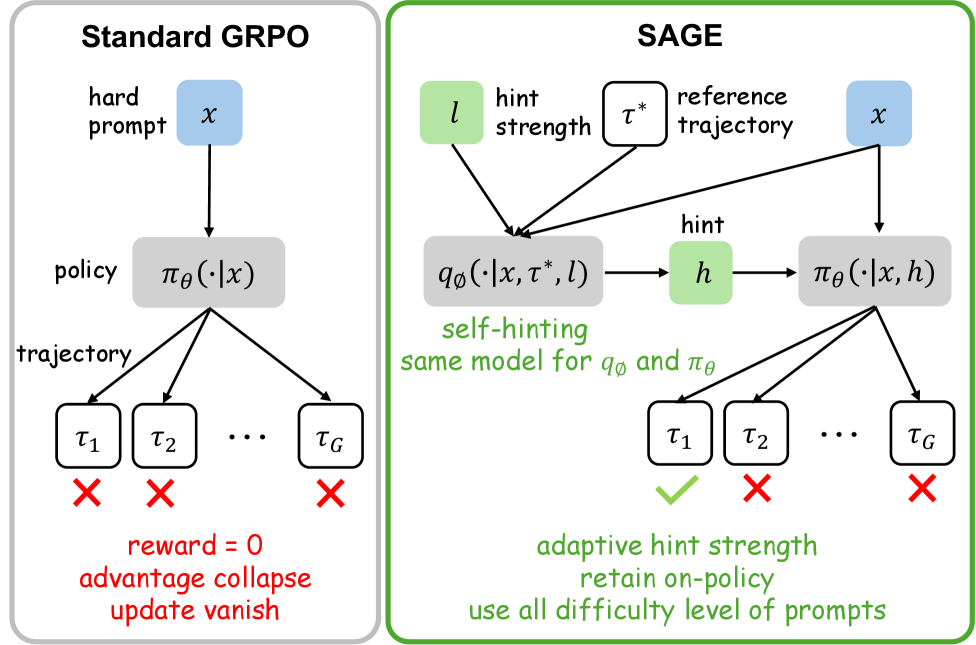
- 提出的SAGE框架通过在训练中引入特权提示,增强了回合结果的多样性,从而改善了模型的学习效果。
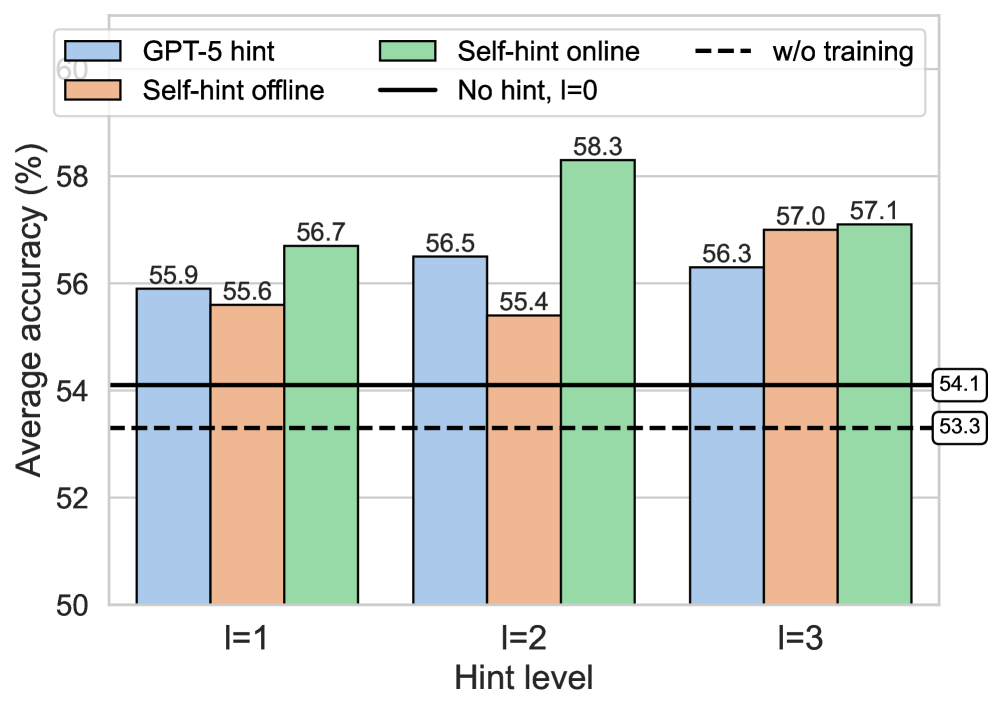
- 实验结果显示,SAGE在多个基准测试中显著优于GRPO,提升幅度在1.2到2.0之间,验证了其有效性。
📝 摘要(中文)
群体相对策略优化(GRPO)最近成为将大型语言模型与可验证目标对齐的实用方法。然而,在稀疏终端奖励下,GRPO常常停滞,因为组内的回合通常接收相同的奖励,导致相对优势崩溃和更新消失。我们提出了自提示对齐GRPO与特权监督(SAGE),这是一个在训练过程中注入特权提示的在线强化学习框架,以重塑在相同终端验证者奖励下的回合分布。每个提示$x$,模型会采样一个紧凑的提示$h$(例如计划或分解),然后生成一个基于$(x,h)$的解决方案$τ$。重要的是,任务奖励$R(x,τ)$保持不变;提示仅在有限采样下增加组内结果的多样性,防止GRPO优势在稀疏奖励下崩溃。实验表明,SAGE在6个基准上始终优于GRPO,平均提升为Llama-3.2-3B-Instruct +2.0,Qwen2.5-7B-Instruct +1.2,Qwen3-4B-Instruct +1.3。
🔬 方法详解
问题定义:论文要解决的问题是GRPO在稀疏奖励情况下的停滞现象,现有方法在这种情况下容易导致相对优势崩溃,更新效果消失。
核心思路:论文提出的SAGE框架通过引入自提示机制,在训练过程中为每个提示生成紧凑的提示,从而增加组内结果的多样性,保持任务奖励不变。
技术框架:SAGE框架包括提示生成模块、策略生成模块和奖励计算模块。模型首先根据输入提示生成自提示,然后基于提示生成解决方案,最后计算任务奖励。
关键创新:SAGE的关键创新在于自提示机制的引入,这与传统的GRPO方法不同,后者依赖于固定的奖励信号。自提示机制使得模型在稀疏奖励环境中仍能保持学习动力。
关键设计:在设计中,模型通过采样紧凑提示$h$来增强多样性,损失函数保持与GRPO一致,确保在训练过程中不会改变任务奖励的计算方式。
🖼️ 关键图片
📊 实验亮点
实验结果表明,SAGE在6个基准测试中均表现优异,Llama-3.2-3B-Instruct平均提升2.0,Qwen2.5-7B-Instruct提升1.2,Qwen3-4B-Instruct提升1.3,显示出其在强化学习中的有效性。
🎯 应用场景
该研究的潜在应用领域包括自然语言处理、智能对话系统和自动化决策支持等。通过提升模型在稀疏奖励环境中的学习能力,SAGE可以在实际应用中更有效地处理复杂任务,具有重要的实际价值和未来影响。
📄 摘要(原文)
Group Relative Policy Optimization (GRPO) has recently emerged as a practical recipe for aligning large language models with verifiable objectives. However, under sparse terminal rewards, GRPO often stalls because rollouts within a group frequently receive identical rewards, causing relative advantages to collapse and updates to vanish. We propose self-hint aligned GRPO with privileged supervision (SAGE), an on-policy reinforcement learning framework that injects privileged hints during training to reshape the rollout distribution under the same terminal verifier reward. For each prompt $x$, the model samples a compact hint $h$ (e.g., a plan or decomposition) and then generates a solution $τ$ conditioned on $(x,h)$. Crucially, the task reward $R(x,τ)$ is unchanged; hints only increase within-group outcome diversity under finite sampling, preventing GRPO advantages from collapsing under sparse rewards. At test time, we set $h=\varnothing$ and deploy the no-hint policy without any privileged information. Moreover, sampling diverse self-hints serves as an adaptive curriculum that tracks the learner's bottlenecks more effectively than fixed hints from an initial policy or a stronger external model. Experiments over 6 benchmarks with 3 LLMs show that SAGE consistently outperforms GRPO, on average +2.0 on Llama-3.2-3B-Instruct, +1.2 on Qwen2.5-7B-Instruct and +1.3 on Qwen3-4B-Instruct. The code is available at https://github.com/BaohaoLiao/SAGE.