Contrastive Concept-Tree Search for LLM-Assisted Algorithm Discovery
作者: Timothee Leleu, Sudeera Gunathilaka, Federico Ghimenti, Surya Ganguli
分类: cs.LG, cs.AI, cs.NE
发布日期: 2026-02-03
💡 一句话要点
提出对比概念树搜索(CCTS),提升LLM辅助的算法发现效率与可解释性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 算法发现 大语言模型 对比学习 概念树 程序合成
📋 核心要点
- 现有LLM辅助算法发现方法难以有效利用LLM内部对程序空间的表示,限制了性能提升。
- CCTS通过提取程序中的分层概念表示,学习对比概念模型,指导父节点选择,从而优化搜索过程。
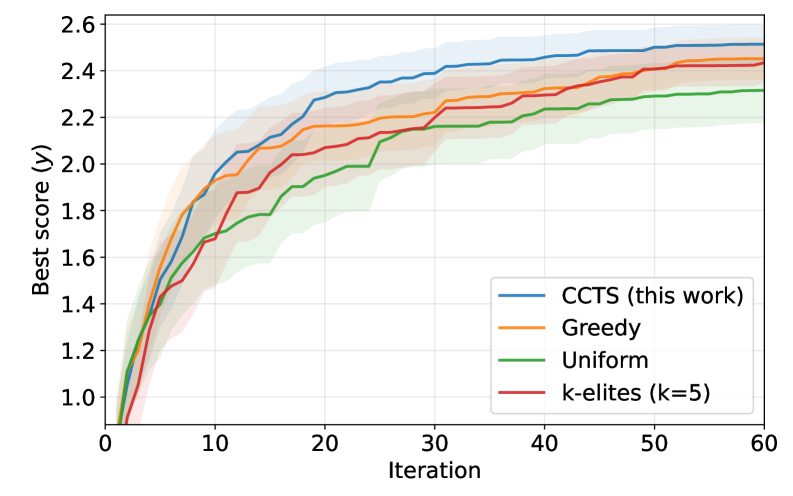
- 实验表明,CCTS在Erdős型组合学问题上提高了搜索效率,并生成了可解释的概念树,主要受益于避免无效概念。
📝 摘要(中文)
本文提出了一种名为对比概念树搜索(CCTS)的方法,旨在提升大语言模型(LLM)辅助的算法发现过程。该过程是一个迭代的黑盒优化,LLM提出候选程序,外部评估器提供任务反馈。CCTS从生成的程序中提取分层概念表示,并学习一个对比概念模型来指导父节点选择。通过使用高低性能解决方案之间的似然比得分重新加权父节点,CCTS将搜索偏向于有用的概念组合,并避免误导性的概念组合,从而通过显式的概念层次结构提供指导,而不是LLM构建的算法谱系。实验表明,CCTS提高了基于适应度的基线的搜索效率,并在开放的Erdős型组合学问题基准测试中生成了可解释的、特定于任务的概念树。分析表明,性能提升主要来自于学习避免哪些概念。这些发现也在一个受控的合成算法发现环境中得到了验证,该环境在质量上重现了LLM观察到的搜索动态。
🔬 方法详解
问题定义:LLM辅助的算法发现是一个黑盒优化问题,目标是找到能够近似解决特定任务的程序。现有的方法通常依赖于LLM生成候选程序,然后通过外部评估器进行评估。然而,如何有效地利用LLM内部对程序空间的表示,从而指导搜索过程,仍然是一个挑战。现有的方法,例如基于适应度的搜索,可能无法充分利用程序中蕴含的概念信息,导致搜索效率低下。
核心思路:CCTS的核心思路是从生成的程序中提取概念,构建概念树,并利用对比学习来区分有用的和无用的概念组合。通过学习一个对比概念模型,CCTS可以指导搜索过程,使其偏向于有用的概念组合,并避免误导性的概念组合。这种方法利用了程序中蕴含的结构化信息,从而提高了搜索效率和可解释性。
技术框架:CCTS的整体框架包括以下几个主要步骤:1) 程序生成:LLM生成候选程序;2) 概念提取:从生成的程序中提取概念,构建概念树;3) 对比学习:利用对比学习训练概念模型,区分有用的和无用的概念组合;4) 父节点选择:使用概念模型指导父节点选择,从而生成新的候选程序;5) 评估:使用外部评估器评估候选程序的性能;6) 迭代:重复以上步骤,直到找到满足要求的程序。
关键创新:CCTS的关键创新在于:1) 概念树表示:将程序表示为概念树,从而利用程序中蕴含的结构化信息;2) 对比学习:利用对比学习来区分有用的和无用的概念组合,从而指导搜索过程;3) 似然比加权:使用高低性能解决方案之间的似然比得分重新加权父节点,从而偏向于有用的概念组合。与现有方法相比,CCTS能够更有效地利用程序中蕴含的概念信息,从而提高搜索效率和可解释性。
关键设计:CCTS的关键设计包括:1) 概念提取方法:如何从程序中提取有意义的概念;2) 对比学习目标函数:如何设计对比学习目标函数,从而有效地学习概念模型;3) 似然比计算方法:如何计算高低性能解决方案之间的似然比得分;4) 父节点选择策略:如何使用概念模型指导父节点选择。具体的参数设置、损失函数、网络结构等技术细节在论文中有详细描述,此处不再赘述。
🖼️ 关键图片


📊 实验亮点
实验结果表明,CCTS在Erdős型组合学问题上显著提高了搜索效率,优于基于适应度的基线方法。分析表明,CCTS的性能提升主要来自于学习避免哪些概念。在受控的合成算法发现环境中,CCTS也表现出与LLM相似的搜索动态,验证了该方法的有效性。具体的性能数据和提升幅度在论文中有详细描述。
🎯 应用场景
CCTS方法可应用于各种需要算法自动发现的领域,例如程序合成、机器人控制、药物发现等。通过提高算法发现的效率和可解释性,CCTS可以帮助研究人员更快地找到解决特定问题的有效算法,并深入理解算法的工作原理。未来,CCTS可以与其他技术相结合,例如强化学习、元学习等,进一步提升算法发现的性能。
📄 摘要(原文)
Large language Model (LLM)-assisted algorithm discovery is an iterative, black-box optimization process over programs to approximatively solve a target task, where an LLM proposes candidate programs and an external evaluator provides task feedback. Despite intense recent research on the topic and promising results, how can the LLM internal representation of the space of possible programs be maximally exploited to improve performance is an open question. Here, we introduce Contrastive Concept-Tree Search (CCTS), which extracts a hierarchical concept representation from the generated programs and learns a contrastive concept model that guides parent selection. By reweighting parents using a likelihood-ratio score between high- and low-performing solutions, CCTS biases search toward useful concept combinations and away from misleading ones, providing guidance through an explicit concept hierarchy rather than the algorithm lineage constructed by the LLM. We show that CCTS improves search efficiency over fitness-based baselines and produces interpretable, task-specific concept trees across a benchmark of open Erdős-type combinatorics problems. Our analysis indicates that the gains are driven largely by learning which concepts to avoid. We further validate these findings in a controlled synthetic algorithm-discovery environment, which reproduces qualitatively the search dynamics observed with the LLMs.