Quantized Evolution Strategies: High-precision Fine-tuning of Quantized LLMs at Low-precision Cost
作者: Yinggan Xu, Risto Miikkulainen, Xin Qiu
分类: cs.LG, cs.AI
发布日期: 2026-02-03
备注: Preprint version
🔗 代码/项目: GITHUB
💡 一句话要点
提出量化进化策略QES,实现低精度代价下量化LLM的高精度微调
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 量化 大型语言模型 进化策略 微调 低精度 后训练量化 误差反馈 无状态种子重放
📋 核心要点
- 现有量化LLM微调方法依赖反向传播,无法直接应用于离散且不可微的量化参数空间。
- QES通过累积误差反馈保留高精度梯度信息,并利用无状态种子重放降低内存占用,实现量化空间直接微调。
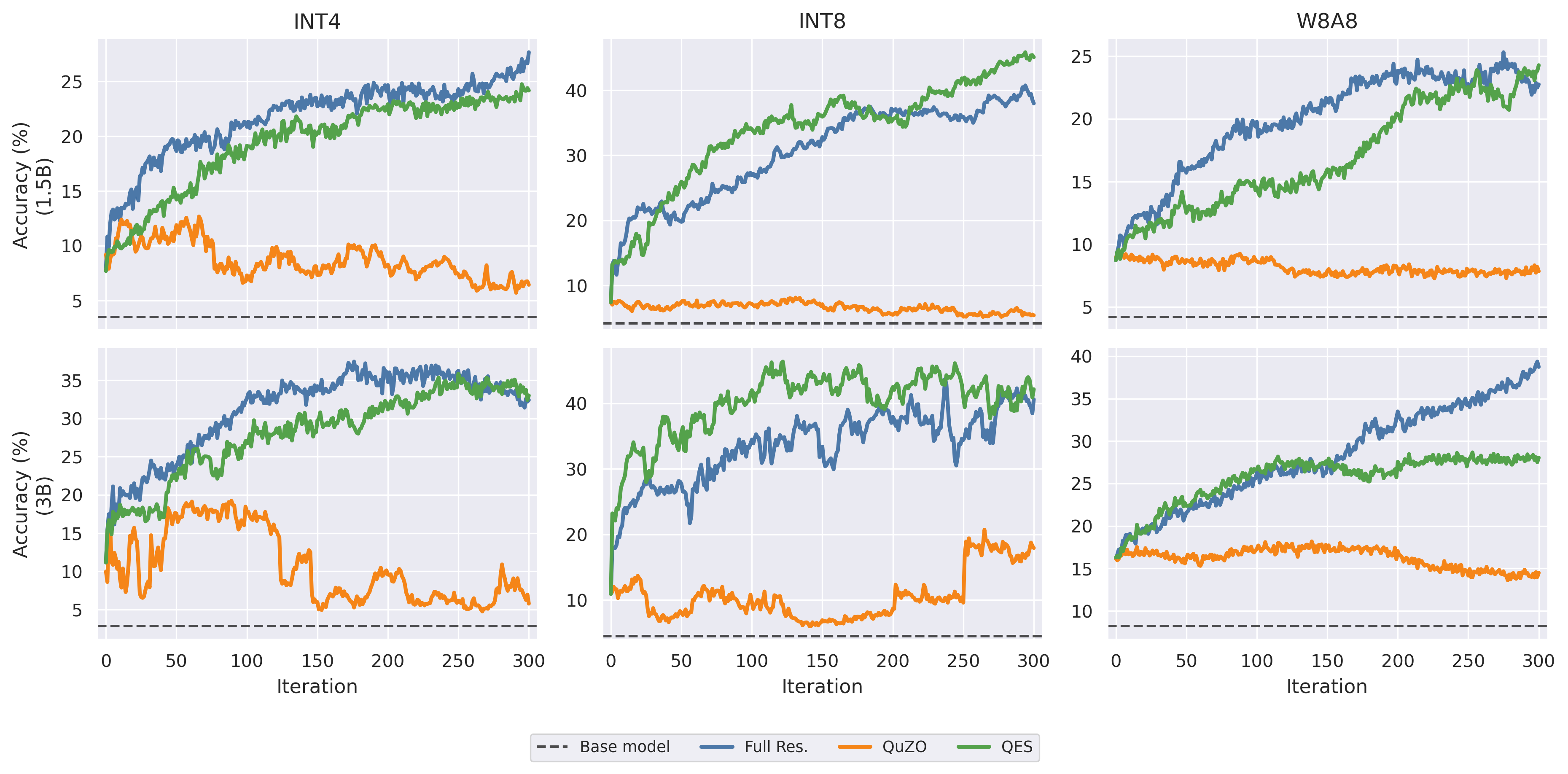
- 实验表明,QES在算术推理任务上显著优于现有零阶微调方法,为量化LLM的微调提供了有效方案。
📝 摘要(中文)
后训练量化(PTQ)对于在内存受限设备上部署大型语言模型(LLM)至关重要,但它使模型变得静态且难以微调。包括强化学习(RL)在内的标准微调范式,从根本上依赖于反向传播和高精度权重来计算梯度。因此,它们不能用于量化模型,因为量化模型的参数空间是离散且不可微的。虽然进化策略(ES)提供了一种无需反向传播的替代方案,但由于梯度消失或不准确,量化参数的优化仍然可能失败。本文介绍了一种量化进化策略(QES),它直接在量化空间中执行全参数微调。QES基于两项创新:(1)它集成了累积误差反馈以保留高精度梯度信号,以及(2)它利用无状态种子重放来将内存使用量降低到低精度推理水平。QES在算术推理任务上显著优于最先进的零阶微调方法,从而使量化模型的直接微调成为可能。因此,它为完全在量化空间中扩展LLM开辟了可能性。源代码可在https://github.com/dibbla/Quantized-Evolution-Strategies 获取。
🔬 方法详解
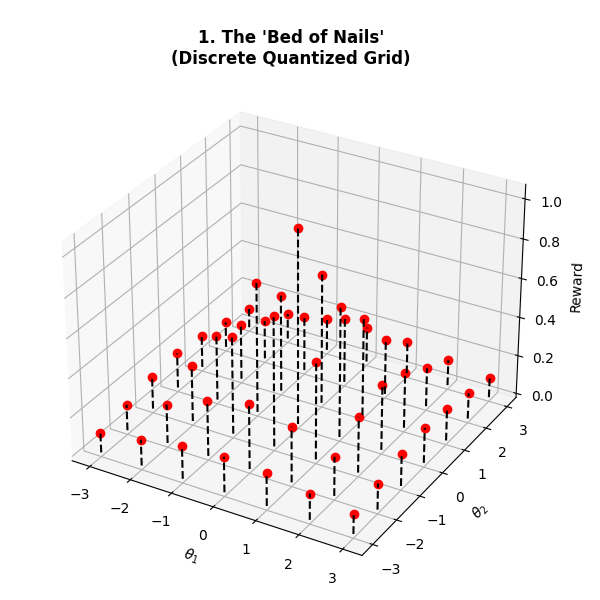
问题定义:论文旨在解决量化大型语言模型(LLM)难以进行微调的问题。现有的微调方法,例如基于反向传播的方法,依赖于高精度权重和可微的参数空间,这使得它们无法直接应用于量化后的LLM。量化操作将参数空间离散化,导致梯度消失或不准确,从而阻碍了有效的微调。
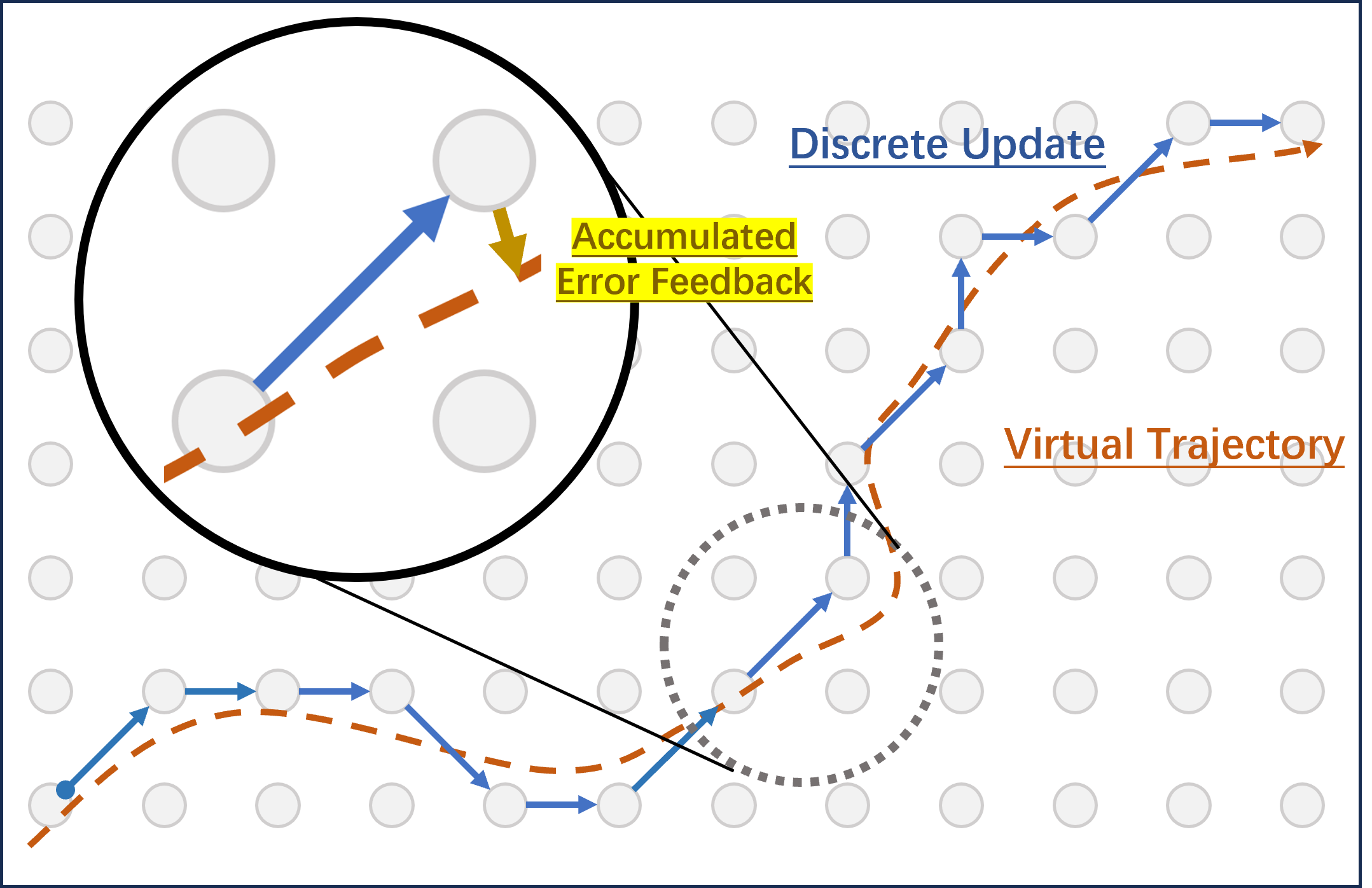
核心思路:论文的核心思路是利用进化策略(ES)作为一种免反向传播的优化方法,直接在量化后的参数空间中进行微调。为了解决量化带来的梯度问题,QES引入了累积误差反馈机制,以保留高精度的梯度信号。同时,为了降低内存消耗,QES采用了无状态种子重放策略。
技术框架:QES的整体框架包括以下几个主要步骤:1)初始化量化模型;2)使用进化策略生成一系列扰动;3)将扰动应用于量化模型,并评估其性能;4)使用累积误差反馈更新扰动策略;5)重复步骤2-4,直到收敛。无状态种子重放用于在每次迭代中生成相同的扰动序列,从而减少内存需求。
关键创新:QES的关键创新在于两个方面:1)累积误差反馈:通过累积误差信息,QES能够保留高精度的梯度信号,从而更有效地指导量化模型的微调。2)无状态种子重放:通过使用相同的种子生成扰动序列,QES避免了存储大量扰动信息,从而显著降低了内存消耗。这使得在低精度设备上进行量化LLM的微调成为可能。
关键设计:QES的关键设计包括:1)扰动策略的选择:论文可能采用了高斯扰动或其他类型的扰动策略来探索参数空间。2)累积误差反馈的实现方式:具体如何累积误差信息,并将其用于更新扰动策略。3)无状态种子重放的实现细节:如何使用种子生成相同的扰动序列,以及如何保证扰动的多样性。
🖼️ 关键图片
📊 实验亮点
QES在算术推理任务上取得了显著的性能提升,超越了现有的零阶微调方法。具体的性能数据和对比基线需要在论文中查找。QES的成功表明,直接在量化空间中进行微调是可行的,并且可以获得与高精度微调相媲美的性能。
🎯 应用场景
QES的应用场景包括:在资源受限的边缘设备上部署和微调大型语言模型,例如智能手机、嵌入式系统等。该方法可以降低模型部署的成本和能耗,并提高模型的适应性和泛化能力。此外,QES还可以用于对已量化的模型进行持续学习和个性化定制。
📄 摘要(原文)
Post-Training Quantization (PTQ) is essential for deploying Large Language Models (LLMs) on memory-constrained devices, yet it renders models static and difficult to fine-tune. Standard fine-tuning paradigms, including Reinforcement Learning (RL), fundamentally rely on backpropagation and high-precision weights to compute gradients. Thus they cannot be used on quantized models, where the parameter space is discrete and non-differentiable. While Evolution Strategies (ES) offer a backpropagation-free alternative, optimization of the quantized parameters can still fail due to vanishing or inaccurate gradient. This paper introduces Quantized Evolution Strategies (QES), an optimization paradigm that performs full-parameter fine-tuning directly in the quantized space. QES is based on two innovations: (1) it integrates accumulated error feedback to preserve high-precision gradient signals, and (2) it utilizes a stateless seed replay to reduce memory usage to low-precision inference levels. QES significantly outperforms the state-of-the-art zeroth-order fine-tuning method on arithmetic reasoning tasks, making direct fine-tuning for quantized models possible. It therefore opens up the possibility for scaling up LLMs entirely in the quantized space. The source code is available at https://github.com/dibbla/Quantized-Evolution-Strategies .