Neural Predictor-Corrector: Solving Homotopy Problems with Reinforcement Learning
作者: Jiayao Mai, Bangyan Liao, Zhenjun Zhao, Yingping Zeng, Haoang Li, Javier Civera, Tailin Wu, Yi Zhou, Peidong Liu
分类: cs.LG, cs.CV
发布日期: 2026-02-03
💡 一句话要点
提出神经预测-校正器(NPC),用强化学习解决同伦问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 同伦方法 神经预测-校正器 强化学习 序列决策 全局优化
📋 核心要点
- 传统同伦问题的求解器依赖手工设计的启发式策略,在步长选择和迭代终止方面存在次优和任务依赖性问题。
- 论文提出神经预测-校正器(NPC),利用强化学习自动学习高效策略,替代手工启发式,解决同伦问题。
- 实验表明,NPC在多个同伦问题上,相比传统方法和特定领域方法,在效率和稳定性上均有提升,并具备良好的泛化能力。
📝 摘要(中文)
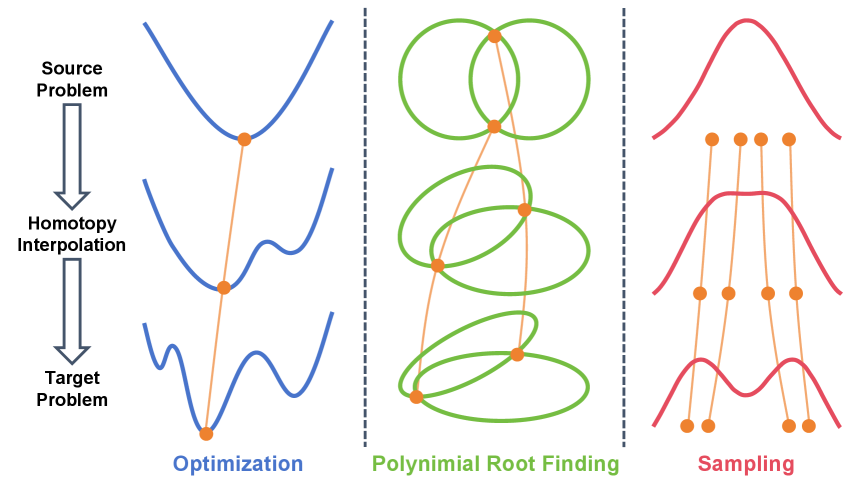
同伦范式是解决复杂问题的一种通用原则,广泛应用于鲁棒优化、全局优化、多项式求根和采样等领域。这些问题的实用求解器通常遵循预测-校正(PC)结构,但依赖于手工设计的步长和迭代终止启发式方法,这些方法通常是次优的且特定于任务。为了解决这个问题,我们将这些问题统一在一个框架下,从而能够设计一个通用的神经求解器。在此统一视图的基础上,我们提出了神经预测-校正器(NPC),它用自动学习的策略取代了手工设计的启发式方法。NPC将策略选择建模为一个序列决策问题,并利用强化学习自动发现有效的策略。为了进一步提高泛化能力,我们引入了一种摊销训练机制,从而能够对一类问题进行一次性离线训练,并对新实例进行高效的在线推理。在四个具有代表性的同伦问题上的实验表明,我们的方法能够有效地推广到未见过的实例。它在效率上始终优于经典和专门的基线,同时在任务中表现出卓越的稳定性,突出了将同伦方法统一到一个神经框架中的价值。
🔬 方法详解
问题定义:论文旨在解决同伦方法中手工设计启发式策略的局限性。现有方法在步长选择和迭代终止方面依赖人工经验,导致求解效率低下且难以泛化到不同类型的同伦问题。这些手工策略通常是次优的,并且需要针对特定任务进行调整,缺乏通用性。
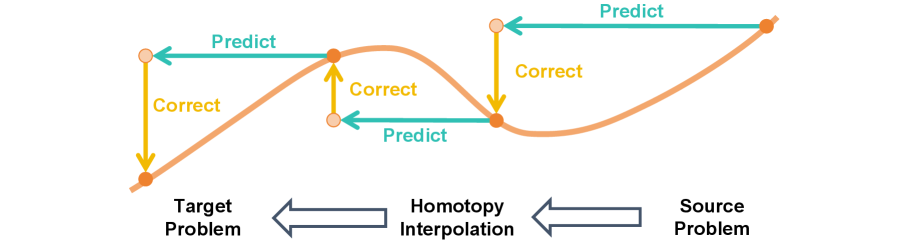
核心思路:论文的核心思路是将同伦问题的求解过程建模为一个序列决策问题,并利用强化学习自动学习最优的预测-校正策略。通过将步长选择和迭代终止视为智能体的动作,智能体可以根据当前状态(例如,同伦参数、解的质量)选择合适的动作,从而优化整个求解过程。这种方法避免了手工设计启发式策略的需要,并能够自动适应不同类型的同伦问题。
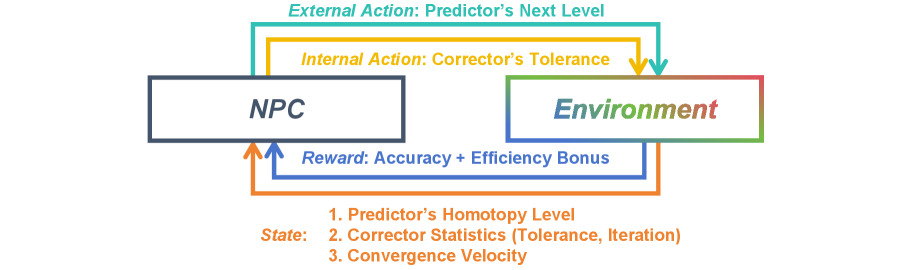
技术框架:NPC的整体框架包括以下几个主要模块:1) 预测器:使用神经网络预测下一个解的估计值。2) 校正器:使用迭代方法(例如,牛顿法)对预测的解进行修正。3) 策略网络:使用强化学习训练的策略网络,用于根据当前状态选择合适的步长和迭代终止条件。4) 环境:模拟同伦问题的求解过程,并根据智能体的动作给出奖励信号。训练过程中,智能体与环境进行交互,通过最大化累积奖励来学习最优策略。
关键创新:论文的关键创新在于将强化学习引入到同伦问题的求解中,并提出了神经预测-校正器(NPC)框架。与传统方法相比,NPC能够自动学习最优的预测-校正策略,避免了手工设计启发式策略的需要。此外,论文还引入了一种摊销训练机制,使得NPC能够对一类问题进行一次性离线训练,并对新实例进行高效的在线推理,从而提高了泛化能力。
关键设计:策略网络通常采用循环神经网络(RNN)或Transformer结构,以捕捉同伦求解过程中的时序信息。奖励函数的设计至关重要,通常包括解的质量、求解时间和迭代次数等因素。为了提高泛化能力,论文采用了数据增强和领域随机化等技术。此外,论文还探索了不同的强化学习算法,例如,策略梯度方法和值函数方法,以优化策略网络的训练。
🖼️ 关键图片
📊 实验亮点
实验结果表明,NPC在四个具有代表性的同伦问题上,包括参数优化、全局优化、多项式求根和采样,均优于传统方法和特定领域的基线方法。在效率方面,NPC能够显著减少求解时间和迭代次数。在稳定性方面,NPC在不同类型的同伦问题上均表现出良好的性能。此外,NPC还展现出良好的泛化能力,能够有效地推广到未见过的实例。
🎯 应用场景
该研究成果可应用于各种需要求解复杂优化问题的领域,例如机器人运动规划、结构优化设计、全局优化、以及机器学习模型的训练等。通过自动学习高效的求解策略,可以显著提高求解效率和鲁棒性,降低对人工经验的依赖,并加速相关领域的研究和应用。
📄 摘要(原文)
The Homotopy paradigm, a general principle for solving challenging problems, appears across diverse domains such as robust optimization, global optimization, polynomial root-finding, and sampling. Practical solvers for these problems typically follow a predictor-corrector (PC) structure, but rely on hand-crafted heuristics for step sizes and iteration termination, which are often suboptimal and task-specific. To address this, we unify these problems under a single framework, which enables the design of a general neural solver. Building on this unified view, we propose Neural Predictor-Corrector (NPC), which replaces hand-crafted heuristics with automatically learned policies. NPC formulates policy selection as a sequential decision-making problem and leverages reinforcement learning to automatically discover efficient strategies. To further enhance generalization, we introduce an amortized training mechanism, enabling one-time offline training for a class of problems and efficient online inference on new instances. Experiments on four representative homotopy problems demonstrate that our method generalizes effectively to unseen instances. It consistently outperforms classical and specialized baselines in efficiency while demonstrating superior stability across tasks, highlighting the value of unifying homotopy methods into a single neural framework.