TMS: Trajectory-Mixed Supervision for Reward-Free, On-Policy SFT
作者: Rana Muhammad Shahroz Khan, Zijie Liu, Zhen Tan, Charles Fleming, Tianlong Chen
分类: cs.LG
发布日期: 2026-02-03
💡 一句话要点
提出轨迹混合监督(TMS),解决SFT中策略漂移导致的灾难性遗忘问题。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 监督微调 灾难性遗忘 策略漂移 轨迹混合 动态课程学习
📋 核心要点
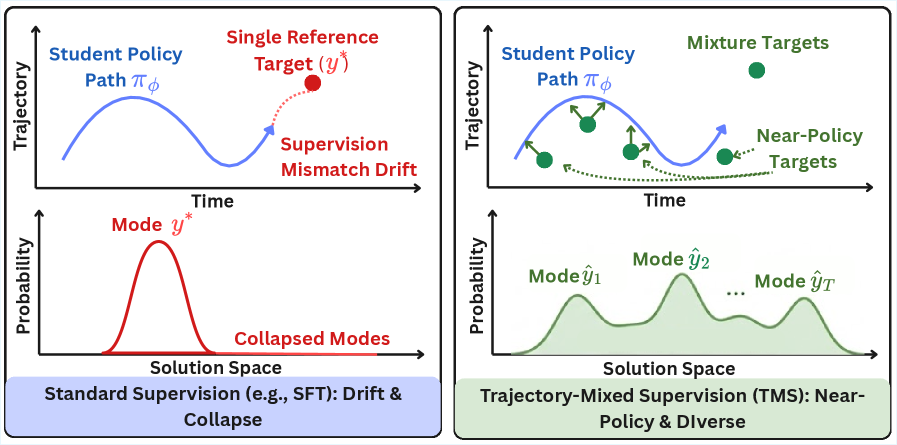
- 传统SFT微调虽然高效,但易受“监督不匹配”影响,导致灾难性遗忘,损害模型泛化能力。
- TMS通过混合模型自身历史轨迹的监督信号,构建动态课程,降低策略与标签之间的差异,缓解遗忘。
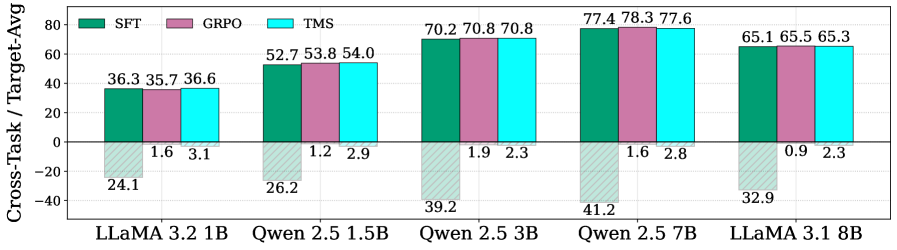
- 实验表明,TMS在推理和指令遵循任务上,显著提升了模型准确率,并有效缓解了灾难性遗忘现象。
📝 摘要(中文)
本文提出轨迹混合监督(TMS),一种免奖励的在线SFT框架,旨在解决大型语言模型(LLM)在下游任务中微调时出现的灾难性遗忘问题。TMS通过利用模型自身的历史检查点创建一个动态课程,从而近似模拟强化学习(RL)的在线优势。TMS最小化策略-标签差异(PLD),防止标准SFT中导致遗忘的模式崩溃。在推理(MATH, GSM8K)和指令遵循基准测试中,实验表明TMS有效地提升了准确率-保持率的帕累托前沿。虽然RL仍然是保持率的黄金标准,但TMS显著优于标准和迭代SFT,在不需要奖励模型或验证器的情况下缩小了与RL的差距。机制分析证实,PLD漂移能够准确预测遗忘,并且TMS成功地缓解了这种漂移。
🔬 方法详解
问题定义:现有SFT方法在微调大型语言模型时,由于训练数据(静态标签)与模型策略的不断演化之间存在差异(监督不匹配),导致模型在原始能力上的灾难性遗忘。这种遗忘限制了SFT在实际应用中的效果。
核心思路:TMS的核心在于通过混合模型自身历史轨迹的监督信号,构建一个动态的训练课程。这种动态课程能够更贴近模型当前的策略,从而降低策略与标签之间的差异,缓解遗忘。通过模仿在线强化学习的优势,但避免了复杂的奖励工程。
技术框架:TMS框架主要包含以下几个阶段:1) 使用初始SFT数据训练模型;2) 定期保存模型的检查点;3) 在后续训练中,混合使用来自不同检查点的模型生成的轨迹作为监督信号;4) 使用混合后的数据进行SFT训练。该过程持续迭代,不断更新模型和轨迹混合比例。
关键创新:TMS的关键创新在于使用模型自身的历史策略作为监督信号,构建动态训练课程。这与传统的SFT方法使用静态标签数据有本质区别。通过这种方式,TMS能够更好地适应模型策略的演化,降低策略-标签差异,从而缓解遗忘。
关键设计:TMS的关键设计包括:1) 轨迹混合比例的确定:可以采用均匀混合或基于模型性能的加权混合;2) 检查点保存频率:需要根据任务的复杂度和计算资源进行调整;3) 损失函数:可以使用标准的交叉熵损失函数,但也可以考虑加入正则化项,以进一步缓解遗忘。
🖼️ 关键图片

📊 实验亮点
实验结果表明,TMS在MATH和GSM8K等推理任务以及指令遵循任务上,显著优于标准SFT和迭代SFT方法。在保持模型原始能力方面,TMS也表现出更强的优势,缩小了与强化学习方法的差距。机制分析证实,策略-标签差异(PLD)能够准确预测遗忘,并且TMS成功地缓解了这种漂移。
🎯 应用场景
TMS方法可广泛应用于需要对大型语言模型进行微调的各种场景,例如对话系统、文本生成、代码生成等。尤其适用于那些对模型原始能力保持有较高要求的任务。该方法无需人工设计的奖励函数,降低了应用门槛,并有望提升微调后模型的综合性能。
📄 摘要(原文)
Reinforcement Learning (RL) and Supervised Fine-Tuning (SFT) are the two dominant paradigms for enhancing Large Language Model (LLM) performance on downstream tasks. While RL generally preserves broader model capabilities (retention) better than SFT, it comes with significant costs: complex reward engineering, instability, and expensive on-policy sampling. In contrast, SFT is efficient but brittle, often suffering from catastrophic forgetting due to $\textbf{Supervision Mismatch}$: the divergence between the model's evolving policy and static training labels. We address this trade-off with $\textbf{Trajectory-Mixed Supervision (TMS)}$, a reward-free framework that approximates the on-policy benefits of RL by creating a dynamic curriculum from the model's own historical checkpoints. TMS minimizes $\textit{Policy-Label Divergence (PLD)}$, preventing the mode collapse that drives forgetting in standard SFT. Experiments across reasoning (MATH, GSM8K) and instruction-following benchmarks demonstrate that TMS effectively shifts the accuracy--retention Pareto frontier. While RL remains the gold standard for retention, TMS significantly outperforms standard and iterative SFT, bridging the gap to RL without requiring reward models or verifiers. Mechanistic analysis confirms that PLD drift accurately predicts forgetting and that TMS successfully mitigates this drift.