CoBA-RL: Capability-Oriented Budget Allocation for Reinforcement Learning in LLMs
作者: Zhiyuan Yao, Yi-Kai Zhang, Yuxin Chen, Yueqing Sun, Zishan Xu, Yu Yang, Tianhao Hu, Qi Gu, Hui Su, Xunliang Cai
分类: cs.LG, cs.AI
发布日期: 2026-02-03
💡 一句话要点
CoBA-RL:面向大语言模型能力自适应的强化学习预算分配
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 强化学习 大语言模型 预算分配 能力导向 价值函数
📋 核心要点
- 现有RLVR方法在LLM推理增强中存在资源分配不均的问题,通常采用统一的rollout预算,效率低下。
- CoBA-RL通过面向能力的价值函数评估任务的训练收益,并使用贪婪策略自适应分配计算资源。
- 实验结果表明,CoBA-RL在多个基准测试中实现了泛化性能的持续提升,验证了其有效性。
📝 摘要(中文)
可验证奖励的强化学习(RLVR)已成为增强大语言模型(LLM)推理能力的关键方法。然而,诸如Group Relative Policy Optimization (GRPO)等标准框架通常采用统一的rollout预算,导致资源利用效率低下。此外,现有的自适应方法通常依赖于实例级别的指标,例如任务通过率,而未能捕捉模型动态的学习状态。为了解决这些限制,我们提出CoBA-RL,一种强化学习算法,旨在根据模型不断发展的能力自适应地分配rollout预算。具体来说,CoBA-RL利用面向能力的价值函数来将任务映射到其潜在的训练收益,并采用基于堆的贪婪策略来有效地自我校准计算资源到具有高训练价值的样本的分配。大量的实验表明,我们的方法有效地协调了探索和利用之间的权衡,从而在多个具有挑战性的基准测试中实现了持续的泛化改进。这些发现强调了量化样本训练价值和优化预算分配对于提高LLM后训练效率至关重要。
🔬 方法详解
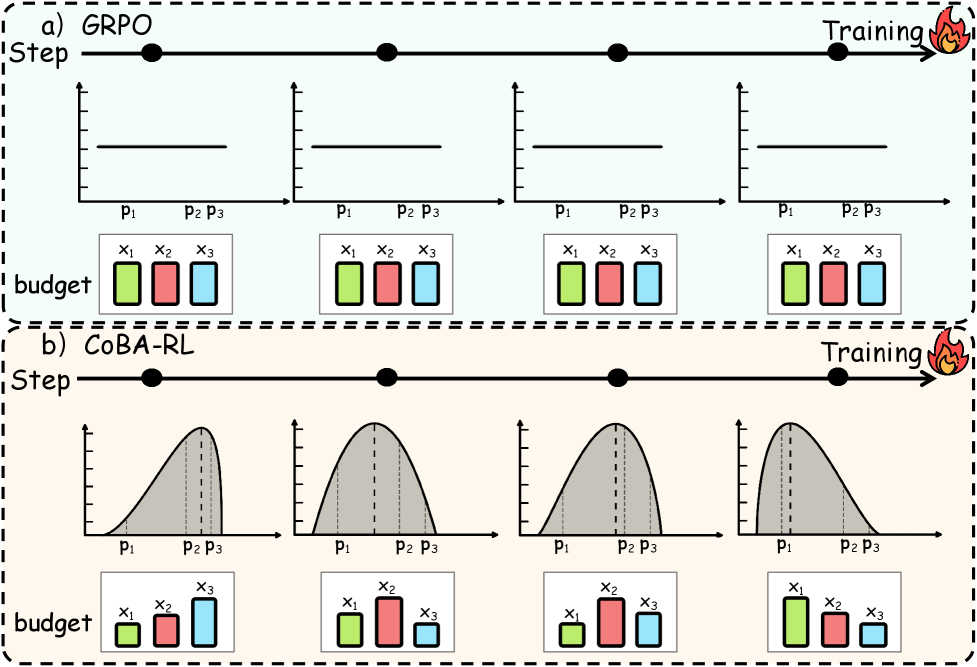
问题定义:现有基于强化学习的大语言模型训练方法,如GRPO,通常对所有样本采用相同的rollout预算,忽略了不同样本对模型能力提升的贡献差异。这种均匀分配方式导致计算资源浪费,降低了训练效率。此外,一些自适应方法依赖于实例级别的指标,无法准确反映模型的整体学习状态。
核心思路:CoBA-RL的核心思想是根据模型在不同任务上的能力水平,自适应地分配rollout预算。它认为,应该将更多的计算资源分配给那些能够带来更大训练收益的样本,从而更有效地提升模型的能力。通过量化样本的训练价值,并优化预算分配,CoBA-RL旨在提高LLM后训练的效率。
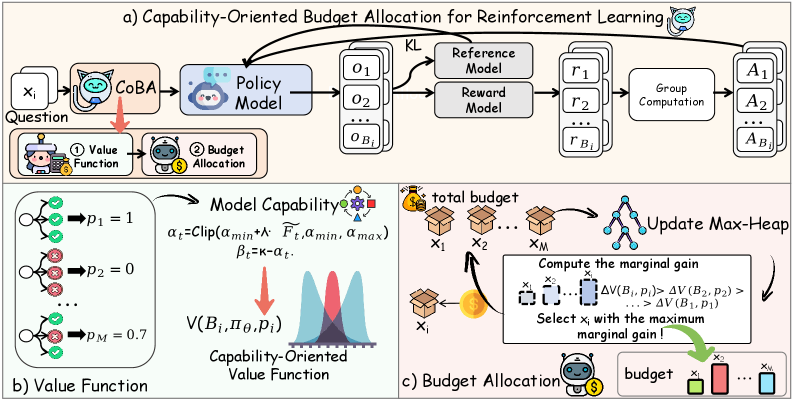
技术框架:CoBA-RL算法主要包含以下几个关键模块:1) 能力导向的价值函数:用于评估每个任务的潜在训练收益,即模型在该任务上进行训练后能力提升的程度。2) 基于堆的贪婪策略:用于根据价值函数的结果,动态地调整每个任务的rollout预算。算法维护一个堆数据结构,每次选择价值最高的任务进行训练,并更新其价值。3) Rollout与更新:根据分配的预算,对选定的任务进行rollout,并使用强化学习算法更新模型参数。
关键创新:CoBA-RL的关键创新在于提出了“能力导向的价值函数”这一概念,并将其用于指导rollout预算的分配。与传统的基于实例级别指标的自适应方法不同,CoBA-RL关注的是任务对模型整体能力提升的贡献,从而能够更有效地利用计算资源。此外,基于堆的贪婪策略能够高效地选择具有高训练价值的样本,进一步提高了训练效率。
关键设计:能力导向的价值函数的设计是关键。论文中价值函数的具体形式未知,但其核心思想是量化任务的训练价值。基于堆的贪婪策略的具体实现细节,例如堆的大小、更新频率等,也会影响算法的性能。此外,所使用的强化学习算法(例如,PPO)及其超参数设置也会对最终结果产生影响。损失函数的设计也未知。
🖼️ 关键图片
📊 实验亮点
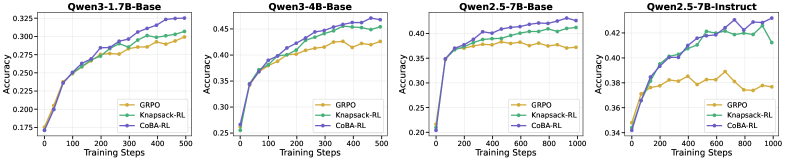
实验结果表明,CoBA-RL在多个具有挑战性的基准测试中实现了持续的泛化改进。具体性能数据和对比基线未知,但论文强调CoBA-RL有效地协调了探索和利用之间的权衡,并显著提高了LLM后训练的效率。CoBA-RL的性能提升证明了量化样本训练价值和优化预算分配对于提高LLM性能的重要性。
🎯 应用场景
CoBA-RL可应用于各种需要通过强化学习进行后训练的大语言模型,例如指令跟随、对话生成、代码生成等。该方法能够提升模型在特定任务上的性能,并提高训练效率,降低计算成本。未来,CoBA-RL可以进一步扩展到多任务学习和持续学习等场景,实现更高效的模型训练和能力提升。
📄 摘要(原文)
Reinforcement Learning with Verifiable Rewards (RLVR) has emerged as a key approach for enhancing LLM reasoning.However, standard frameworks like Group Relative Policy Optimization (GRPO) typically employ a uniform rollout budget, leading to resource inefficiency. Moreover, existing adaptive methods often rely on instance-level metrics, such as task pass rates, failing to capture the model's dynamic learning state. To address these limitations, we propose CoBA-RL, a reinforcement learning algorithm designed to adaptively allocate rollout budgets based on the model's evolving capability. Specifically, CoBA-RL utilizes a Capability-Oriented Value function to map tasks to their potential training gains and employs a heap-based greedy strategy to efficiently self-calibrate the distribution of computational resources to samples with high training value. Extensive experiments demonstrate that our approach effectively orchestrates the trade-off between exploration and exploitation, delivering consistent generalization improvements across multiple challenging benchmarks. These findings underscore that quantifying sample training value and optimizing budget allocation are pivotal for advancing LLM post-training efficiency.