Rethinking Music Captioning with Music Metadata LLMs
作者: Irmak Bukey, Zhepei Wang, Chris Donahue, Nicholas J. Bryan
分类: cs.SD, cs.LG
发布日期: 2026-02-03
备注: Accepted to ICASSP 2026
💡 一句话要点
提出基于音乐元数据的音乐描述方法,提升生成质量与灵活性
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 音乐描述 元数据预测 大型语言模型 风格迁移 元数据补全 音频理解 自然语言生成
📋 核心要点
- 高质量音乐描述数据稀缺,现有方法依赖LLM生成伪数据,存在风格固定和信息纠缠问题。
- 提出基于元数据的描述方法,先预测详细元数据,再用LLM生成描述,解耦风格与内容。
- 实验表明,该方法在更短时间内达到相当性能,并具备风格定制和元数据补全能力。
📝 摘要(中文)
音乐描述,即生成音乐的自然语言描述,对音乐理解和可控音乐生成都很有用。然而,训练描述模型通常需要高质量的音乐描述数据,但与元数据(如流派、情绪等)相比,这类数据非常稀缺。因此,通常使用大型语言模型(LLM)从元数据合成描述,以生成描述模型的训练数据,但此过程会强加固定的风格,并将事实信息与自然语言风格纠缠在一起。作为一种更直接的方法,我们提出了基于元数据的描述方法。我们训练一个元数据预测模型,从音频中推断详细的音乐元数据,然后在推理时通过预训练的LLM将其转换为富有表现力的描述。与在基于元数据生成的LLM描述上训练的强大的端到端基线相比,我们的方法:(1)在更短的训练时间内实现了与端到端描述器相当的性能,(2)提供了灵活的后训练风格更改,使输出描述能够根据特定的风格和质量要求进行定制,以及(3)可以使用音频和部分元数据进行提示,以实现强大的元数据推断或填充——这是组织音乐数据的常见任务。
🔬 方法详解
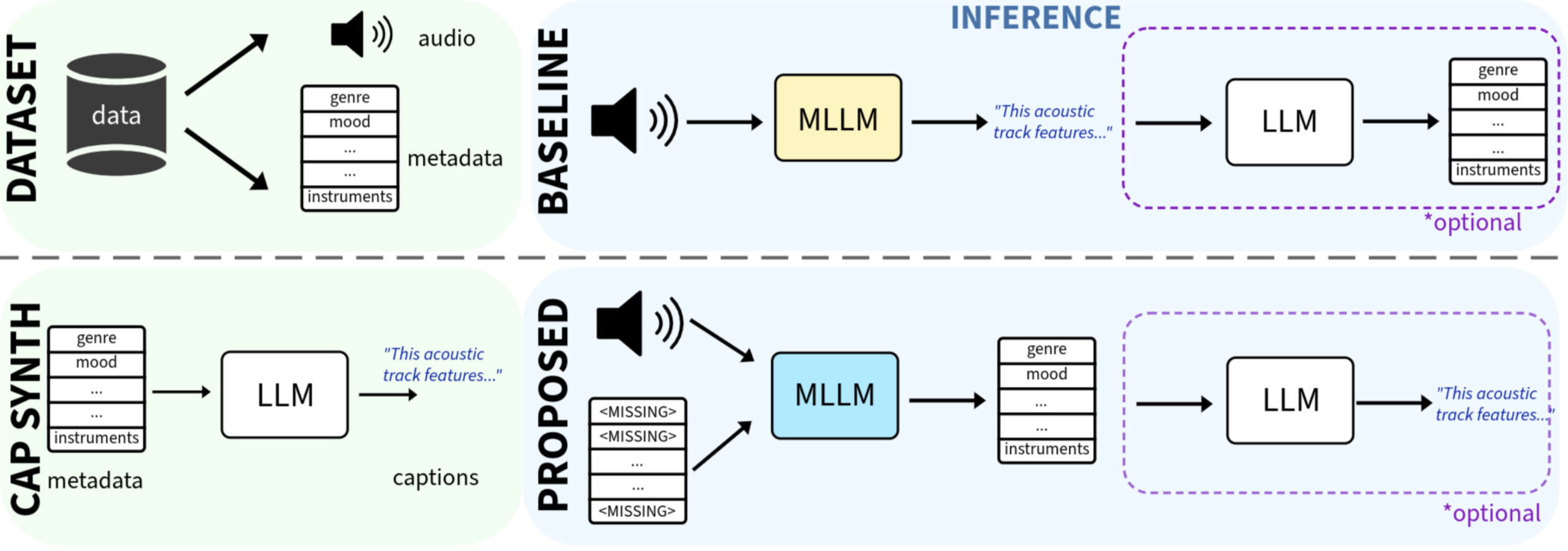
问题定义:音乐描述任务旨在为给定的音乐音频生成一段自然语言描述。现有方法通常依赖于使用大型语言模型(LLM)从音乐的元数据(如流派、情绪等)生成伪描述数据,然后使用这些数据训练端到端的描述模型。这种方法的痛点在于,LLM生成的描述数据会引入固定的风格,并且将音乐的事实信息与自然语言的风格表达纠缠在一起,限制了生成描述的多样性和可控性。
核心思路:论文的核心思路是将音乐描述任务分解为两个阶段:首先,从音乐音频中预测详细的音乐元数据;然后,利用预训练的LLM将预测的元数据转换为自然语言描述。这种解耦的设计使得可以独立地控制描述的风格,并且可以利用音频和部分元数据进行元数据补全。
技术框架:整体框架包含两个主要模块:1) 元数据预测模型:该模型接收音乐音频作为输入,并预测一系列详细的音乐元数据标签。可以使用各种音频特征提取方法(例如,梅尔频谱图)和机器学习模型(例如,卷积神经网络、循环神经网络)来实现。2) LLM描述生成器:该模块接收元数据预测模型输出的元数据标签作为输入,并使用预训练的LLM生成自然语言描述。可以使用各种提示工程技术来控制生成描述的风格和质量。
关键创新:最重要的技术创新点在于将音乐描述任务分解为元数据预测和描述生成两个阶段,从而解耦了音乐内容和描述风格。与直接使用LLM生成伪数据训练端到端模型相比,该方法可以更灵活地控制描述的风格,并且可以利用音频和部分元数据进行元数据补全。
关键设计:元数据预测模型可以使用卷积神经网络(CNN)或循环神经网络(RNN)进行训练,损失函数可以使用交叉熵损失或均方误差损失。LLM描述生成器可以使用预训练的Transformer模型,例如GPT-2或GPT-3,并使用提示工程技术来控制生成描述的风格和质量。关键参数包括CNN/RNN的网络结构、学习率、batch size,以及LLM的提示模板和生成参数(例如,temperature、top-p)。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在训练时间更短的情况下,能够达到与端到端模型相当的性能。此外,该方法还具备风格定制和元数据补全能力,能够根据用户的需求生成不同风格的音乐描述,并能够利用音频和部分元数据推断缺失的元数据信息。
🎯 应用场景
该研究成果可应用于音乐信息检索、音乐推荐、音乐创作辅助等领域。通过生成高质量的音乐描述,可以帮助用户更好地理解和发现音乐,并为音乐创作者提供灵感。此外,该方法还可以用于自动生成音乐标签,从而提高音乐数据的组织和管理效率。
📄 摘要(原文)
Music captioning, or the task of generating a natural language description of music, is useful for both music understanding and controllable music generation. Training captioning models, however, typically requires high-quality music caption data which is scarce compared to metadata (e.g., genre, mood, etc.). As a result, it is common to use large language models (LLMs) to synthesize captions from metadata to generate training data for captioning models, though this process imposes a fixed stylization and entangles factual information with natural language style. As a more direct approach, we propose metadata-based captioning. We train a metadata prediction model to infer detailed music metadata from audio and then convert it into expressive captions via pre-trained LLMs at inference time. Compared to a strong end-to-end baseline trained on LLM-generated captions derived from metadata, our method: (1) achieves comparable performance in less training time over end-to-end captioners, (2) offers flexibility to easily change stylization post-training, enabling output captions to be tailored to specific stylistic and quality requirements, and (3) can be prompted with audio and partial metadata to enable powerful metadata imputation or in-filling--a common task for organizing music data.