FedKRSO: Communication and Memory Efficient Federated Fine-Tuning of Large Language Models
作者: Guohao Yang, Tongle Wu, Yuanxiong Guo, Ying Sun, Yanmin Gong
分类: cs.LG, cs.AI
发布日期: 2026-02-03
备注: Accepted by INFOCOM 2026
💡 一句话要点
FedKRSO:一种通信和内存高效的联邦大语言模型全参数微调方法
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 联邦学习 大型语言模型 参数高效微调 随机子空间优化 通信效率 内存效率
📋 核心要点
- 现有联邦学习微调LLM方法面临通信和计算成本高的挑战,尤其是在资源受限的客户端上。
- FedKRSO的核心思想是在随机低维子空间内进行模型更新,并仅传输子空间内的更新累积量,从而降低通信和内存开销。
- 实验表明,FedKRSO在GLUE基准测试中实现了优越的性能,同时显著降低了通信和内存开销,接近联邦全参数微调的性能。
📝 摘要(中文)
本文提出FedKRSO(Federated $K$-Seed Random Subspace Optimization),一种新颖的方法,能够在联邦设置下对大型语言模型(LLM)进行通信和内存高效的全参数微调(FFT)。在FedKRSO中,客户端在一个由服务器生成的共享随机低维子空间集合内更新模型,从而节省内存使用。此外,客户端仅发送沿子空间的模型更新累积量到服务器,而不是在每个FL轮次中传输完整的模型参数,从而实现高效的全局模型聚合和分发。通过使用这些策略,FedKRSO可以显著降低通信和内存开销,同时克服参数高效微调(PEFT)的性能限制,接近联邦FFT的性能。本文对FedKRSO的收敛性在一般FL设置下进行了严格分析。在GLUE基准上进行的广泛实验,涵盖了不同的FL场景,证明FedKRSO实现了卓越的性能以及低通信和内存开销,为在资源受限的边缘进行联邦LLM微调铺平了道路。
🔬 方法详解
问题定义:联邦学习(FL)旨在利用分散的数据进行协同模型训练,同时保护数据隐私。然而,将通用大型语言模型(LLM)微调到特定领域任务需要大量的计算资源和通信带宽。传统的联邦全参数微调(FFT)方法在资源受限的客户端上成本过高,而参数高效微调(PEFT)方法虽然降低了成本,但通常会牺牲模型性能。因此,如何在联邦设置下实现通信和内存高效的LLM全参数微调是一个关键问题。
核心思路:FedKRSO的核心思路是利用随机子空间优化来降低通信和内存开销。具体来说,服务器生成一组共享的随机低维子空间,客户端仅在这些子空间内更新模型参数。通过限制更新范围,可以显著减少客户端的内存占用。此外,客户端不直接传输完整的模型参数,而是仅发送沿子空间的模型更新累积量,从而降低通信开销。这种设计能够在保证模型性能的同时,显著降低资源消耗。
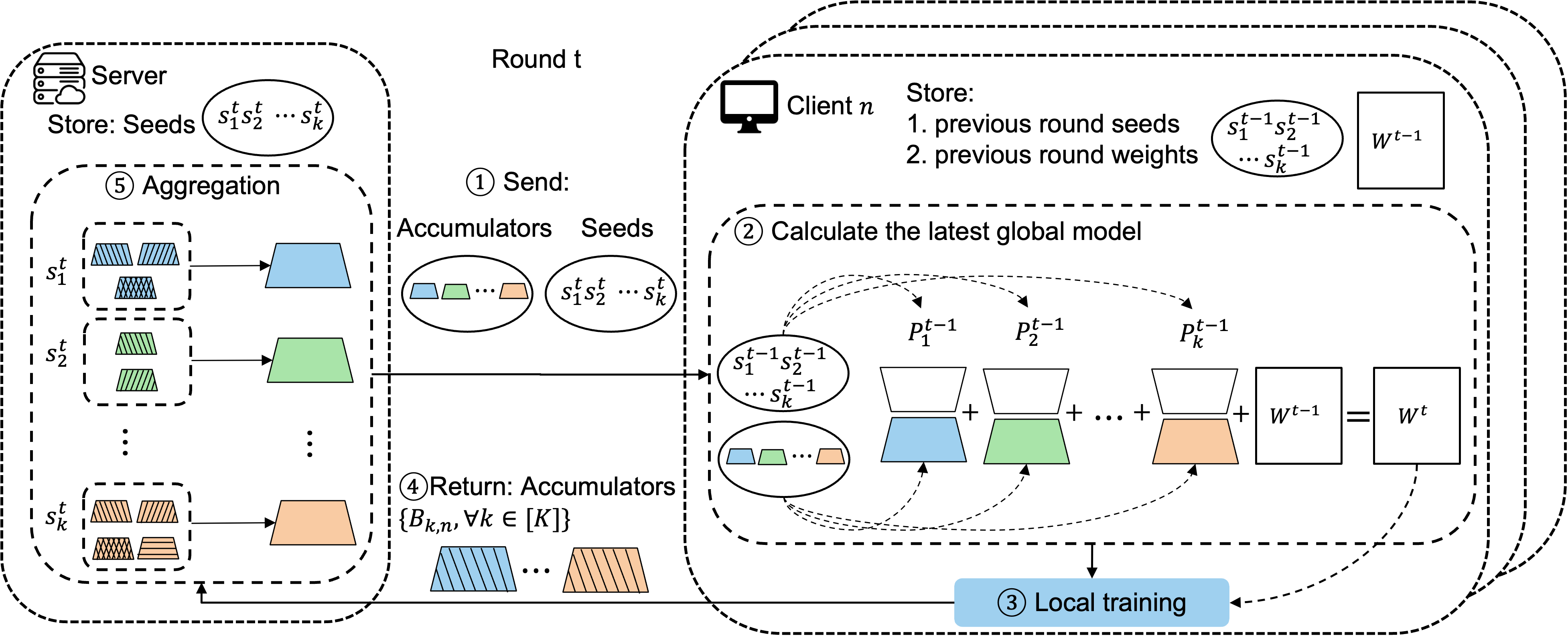
技术框架:FedKRSO的整体框架如下:1) 服务器初始化LLM模型并生成一组随机低维子空间;2) 服务器将模型和子空间信息分发给客户端;3) 客户端在本地数据上,仅在指定的子空间内进行模型更新;4) 客户端将子空间内的模型更新累积量发送回服务器;5) 服务器聚合来自所有客户端的更新,并更新全局模型;6) 服务器将更新后的全局模型分发给客户端,重复步骤2-5,直到模型收敛。
关键创新:FedKRSO的关键创新在于:1) 使用随机子空间优化,限制模型更新的范围,从而降低内存占用;2) 仅传输子空间内的模型更新累积量,而非完整的模型参数,从而降低通信开销;3) 理论分析证明了FedKRSO在一般FL设置下的收敛性。与现有PEFT方法相比,FedKRSO能够更接近联邦FFT的性能。
关键设计:FedKRSO的关键设计包括:1) 子空间的数量$K$和维度$d$的选择,需要权衡性能和资源开销;2) 使用$K$-Seed随机数生成器,确保客户端之间子空间的一致性;3) 模型更新累积量的计算方式,需要保证能够有效地聚合来自不同客户端的更新;4) 损失函数的选择,需要根据具体的任务进行调整。
🖼️ 关键图片

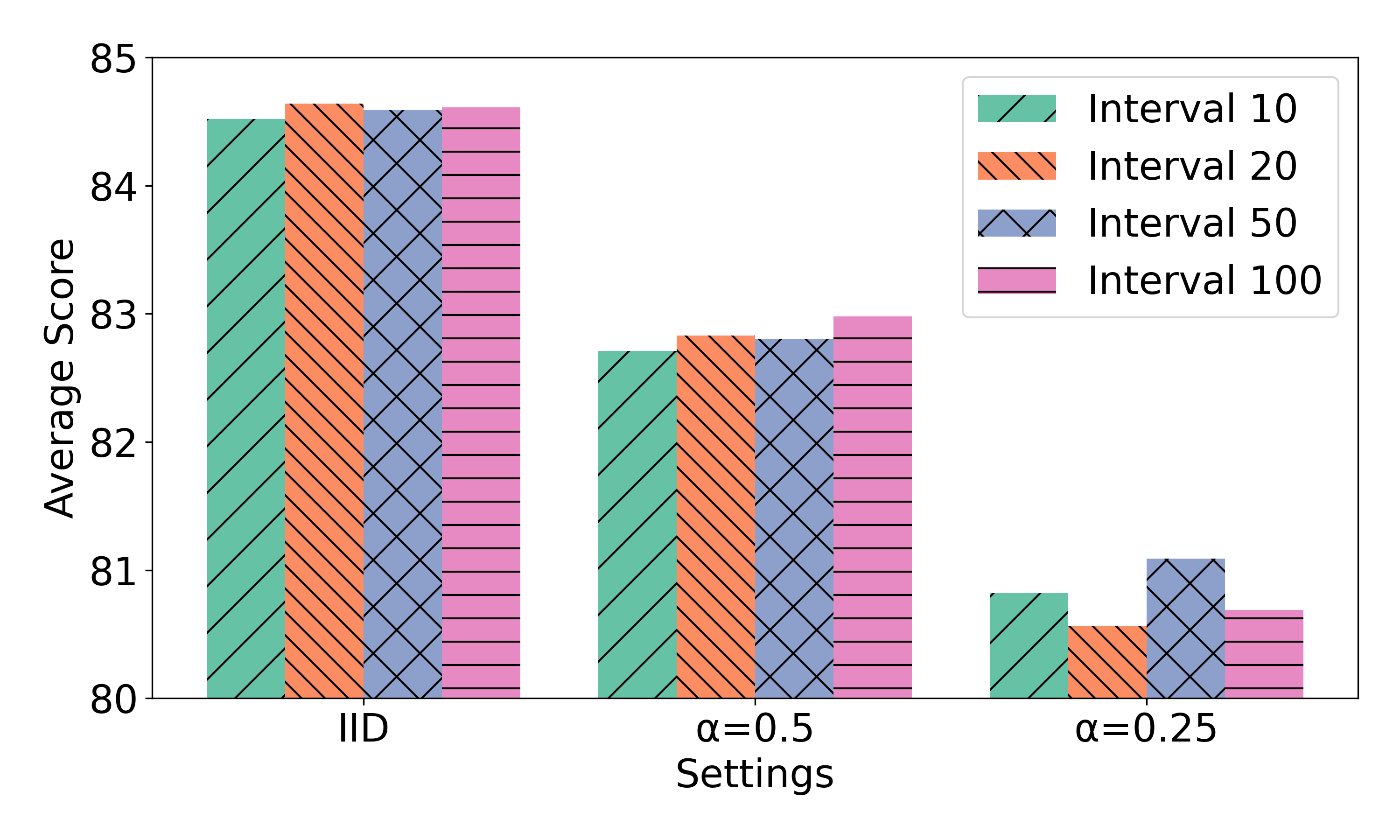
📊 实验亮点
在GLUE基准测试中,FedKRSO在多个FL场景下都取得了优异的性能。例如,在某些任务上,FedKRSO的性能接近联邦全参数微调(FFT),同时显著降低了通信和内存开销。与现有的参数高效微调(PEFT)方法相比,FedKRSO在性能上具有明显的优势。实验结果表明,FedKRSO能够在资源受限的边缘设备上实现高效的LLM微调。
🎯 应用场景
FedKRSO适用于各种需要保护用户隐私且计算资源受限的联邦学习场景,例如:移动设备上的个性化语言模型微调、医疗领域的电子病历分析、金融领域的反欺诈模型训练等。该方法能够降低通信和计算成本,使得在边缘设备上进行大规模LLM微调成为可能,具有广泛的应用前景。
📄 摘要(原文)
Fine-tuning is essential to adapt general-purpose large language models (LLMs) to domain-specific tasks. As a privacy-preserving framework to leverage decentralized data for collaborative model training, Federated Learning (FL) is gaining popularity in LLM fine-tuning, but remains challenging due to the high cost of transmitting full model parameters and computing full gradients on resource-constrained clients. While Parameter-Efficient Fine-Tuning (PEFT) methods are widely used in FL to reduce communication and memory costs, they often sacrifice model performance compared to FFT. This paper proposes FedKRSO (Federated $K$-Seed Random Subspace Optimization), a novel method that enables communication and memory efficient FFT of LLMs in federated settings. In FedKRSO, clients update the model within a shared set of random low-dimension subspaces generated by the server to save memory usage. Furthermore, instead of transmitting full model parameters in each FL round, clients send only the model update accumulators along the subspaces to the server, enabling efficient global model aggregation and dissemination. By using these strategies, FedKRSO can substantially reduce communication and memory overhead while overcoming the performance limitations of PEFT, closely approximating the performance of federated FFT. The convergence properties of FedKRSO are analyzed rigorously under general FL settings. Extensive experiments on the GLUE benchmark across diverse FL scenarios demonstrate that FedKRSO achieves both superior performance and low communication and memory overhead, paving the way towards on federated LLM fine-tuning at the resource-constrained edge.