From Zero to Hero: Advancing Zero-Shot Foundation Models for Tabular Outlier Detection
作者: Xueying Ding, Haomin Wen, Simon Klütterman, Leman Akoglu
分类: cs.LG
发布日期: 2026-02-03
备注: 37 pages
💡 一句话要点
OUTFORMER:通过混合先验和自适应课程学习提升表格异常检测零样本基础模型
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 异常检测 零样本学习 基础模型 表格数据 Transformer 上下文学习 合成数据 课程学习
📋 核心要点
- 现有异常检测方法依赖大量标注数据,在新任务上部署困难,算法和超参数选择是挑战。
- OUTFORMER通过混合合成先验和自适应课程学习,提升零样本异常检测基础模型FoMo-0D。
- OUTFORMER在AdBench和两个新大规模异常检测基准上达到SOTA,同时保持快速推理。
📝 摘要(中文)
异常检测(OD)在实践中应用广泛,但由于缺乏带标签的异常值,难以有效部署到新任务,这使得算法和超参数的选择异常困难。基础模型(FMs)已经改变了机器学习,异常检测也不例外。Shen等人(2025)提出了FoMo-0D,这是第一个用于异常检测的基础模型,相对于众多基线方法取得了显著的性能。本工作提出了OUTFORMER,通过(1)混合合成先验和(2)自适应课程训练来改进FoMo-0D。OUTFORMER仅在合成标记数据集上进行预训练,并通过使用其训练数据作为上下文输入来推断新任务的测试标签。推理速度快且是零样本的,仅需前向传递,无需标记的异常值。由于上下文学习,它不需要额外的工作——无需OD模型训练或定制模型选择——从而实现真正的即插即用部署。OUTFORMER在著名的AdBench以及我们引入的两个新的大规模OD基准测试(包含超过1500个数据集)上实现了最先进的性能,同时保持了快速的推理速度。
🔬 方法详解
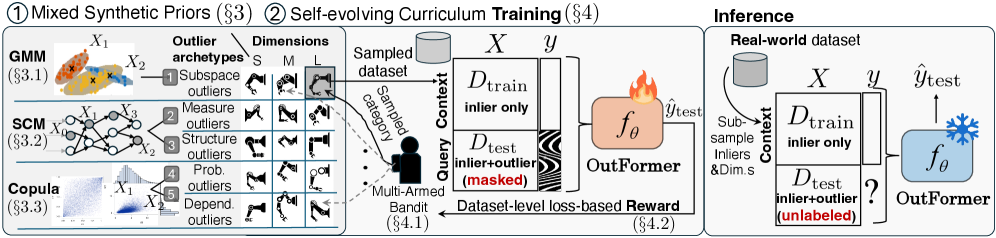
问题定义:论文旨在解决表格数据异常检测中,缺乏标注数据导致模型难以泛化到新任务的问题。现有方法需要针对每个新数据集进行模型训练或选择,成本高昂,难以实现即插即用。
核心思路:论文的核心思路是利用基础模型强大的上下文学习能力,通过在合成数据上预训练,使模型能够在新任务中利用训练数据作为上下文信息进行零样本异常检测。通过混合合成先验和自适应课程学习,提升模型的泛化能力和鲁棒性。
技术框架:OUTFORMER的整体框架包含预训练和推理两个阶段。在预训练阶段,模型在大量合成的异常检测数据集上进行训练,学习异常检测的通用模式。在推理阶段,模型接收目标数据集的训练数据作为上下文输入,直接预测测试数据的异常标签,无需任何额外的训练或微调。
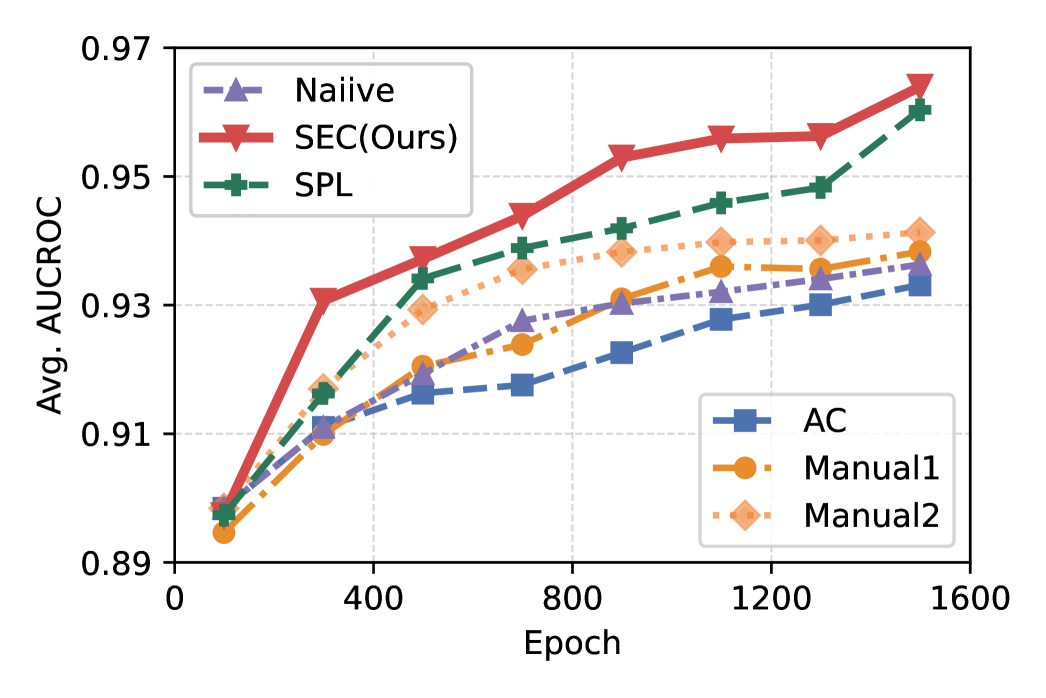
关键创新:OUTFORMER的关键创新在于:1) 混合合成先验:通过混合多种合成数据生成策略,增加训练数据的多样性,提升模型的泛化能力。2) 自适应课程学习:根据模型的学习进度,动态调整训练数据的难度,使模型能够更有效地学习异常检测的知识。3) 零样本异常检测:利用基础模型的上下文学习能力,实现无需任何目标数据集标注的异常检测。
关键设计:OUTFORMER使用Transformer作为基础架构,并针对异常检测任务进行了优化。混合合成先验包括多种异常注入方法,例如随机噪声、特征扰动等。自适应课程学习通过监控模型在验证集上的性能,动态调整训练数据的异常比例和难度。损失函数采用交叉熵损失,用于优化异常标签的预测。
🖼️ 关键图片

📊 实验亮点
OUTFORMER在AdBench以及两个新的大规模OD基准测试(包含超过1500个数据集)上实现了最先进的性能,显著优于现有的异常检测方法。由于论文中没有给出具体的性能数据和提升幅度,具体数值未知。
🎯 应用场景
OUTFORMER可广泛应用于金融欺诈检测、网络安全异常检测、工业设备故障诊断等领域。其零样本特性使其能够快速部署到新的应用场景,无需耗费大量时间和资源进行数据标注和模型训练,具有很高的实际应用价值和潜力。
📄 摘要(原文)
Outlier detection (OD) is widely used in practice; but its effective deployment on new tasks is hindered by lack of labeled outliers, which makes algorithm and hyperparameter selection notoriously hard. Foundation models (FMs) have transformed ML, and OD is no exception: Shen et. al. (2025) introduced FoMo-0D, the first FM for OD, achieving remarkable performance against numerous baselines. This work introduces OUTFORMER, which advances FoMo-0D with (1) a mixture of synthetic priors and (2) self-evolving curriculum training. OUTFORMER is pretrained solely on synthetic labeled datasets and infers test labels of a new task by using its training data as in-context input. Inference is fast and zero-shot, requiring merely forward pass and no labeled outliers. Thanks to in-context learning, it requires zero additional work-no OD model training or bespoke model selection-enabling truly plug-and-play deployment. OUTFORMER achieves state-of-the-art performance on the prominent AdBench, as well as two new large-scale OD benchmarks that we introduce, comprising over 1,500 datasets, while maintaining speedy inference.