NLI:Non-uniform Linear Interpolation Approximation of Nonlinear Operations for Efficient LLMs Inference
作者: Jiangyong Yu, Xiaomeng Han, Xing Hu, Chen Xu, Zhe Jiang, Dawei Yang
分类: cs.LG, cs.AI
发布日期: 2026-02-03
备注: Admitted to ICLR 18pages 5 figures
💡 一句话要点
提出NLI非均匀线性插值,高效近似LLM中的非线性运算,降低推理成本。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 非线性近似 线性插值 动态规划 大语言模型 LLM推理加速
📋 核心要点
- 现有LLM推理中,非线性层(如SiLU、RMSNorm、Softmax)的计算成本高昂,依赖高精度浮点运算,成为性能瓶颈。
- 提出非均匀线性插值(NLI)框架,通过动态规划优化切点选择,以低精度线性插值高效逼近非线性函数。
- 设计并实现了NLI引擎,硬件实验表明,相比现有技术,计算效率提升超过4倍,精度损失几乎可以忽略。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中表现出卓越的性能,但其部署常常受到巨大的内存占用和计算成本的限制。虽然先前的工作在压缩和加速线性层方面取得了显著进展,但诸如SiLU、RMSNorm和Softmax等非线性层仍然严重依赖于高精度浮点运算。本文提出了一种免校准、动态规划最优且硬件友好的框架,称为非均匀线性插值(NLI)。NLI能够有效地逼近各种非线性函数,从而能够无缝集成到LLM和其他深度神经网络中,且几乎没有精度损失。NLI巧妙地将切点选择重新定义为一个动态规划问题,通过贝尔曼最优性原理在O(MxN2)时间内实现全局最小插值误差。基于NLI算法,我们还设计并实现了一个即插即用的通用非线性计算单元。硬件实验表明,与最先进的设计相比,NLI引擎在计算效率方面提高了4倍以上。
🔬 方法详解
问题定义:现有大型语言模型在推理过程中,非线性激活函数(如SiLU、RMSNorm、Softmax等)的计算复杂度较高,需要高精度的浮点运算,成为影响推理速度和能效的关键瓶颈。现有方法在压缩和加速线性层方面取得了进展,但对非线性层的优化仍然不足。
核心思路:论文的核心思路是使用分段线性插值来近似非线性函数,从而降低计算复杂度。关键在于如何选择最佳的切点,使得在保证精度的前提下,线性插值的计算量最小。论文将切点选择问题转化为一个动态规划问题,通过寻找全局最优解来确定切点位置。
技术框架:NLI框架主要包含两个阶段:离线切点选择和在线线性插值。离线阶段,使用动态规划算法,基于训练数据或校准数据,计算出最优的切点位置。在线阶段,根据输入值所在的区间,使用预先计算好的线性插值参数进行计算。此外,论文还设计了一个通用的非线性计算单元,可以方便地集成到现有的硬件架构中。
关键创新:NLI的关键创新在于将切点选择问题建模成动态规划问题,并利用贝尔曼最优性原理求解全局最优解。与传统的均匀线性插值相比,非均匀线性插值可以根据函数的曲率自适应地调整切点密度,从而在相同精度下使用更少的切点,或者在相同切点数量下获得更高的精度。
关键设计:动态规划算法是NLI的核心。具体来说,定义状态dp[i][j]表示使用j个切点逼近前i个数据点的最小误差。状态转移方程为dp[i][j] = min(dp[k][j-1] + error(k+1, i)),其中error(k+1, i)表示使用一条直线逼近第k+1到第i个数据点的误差。通过迭代计算dp数组,可以得到最优的切点位置。此外,论文还考虑了硬件实现的友好性,选择了一些易于硬件实现的线性插值方法。
🖼️ 关键图片


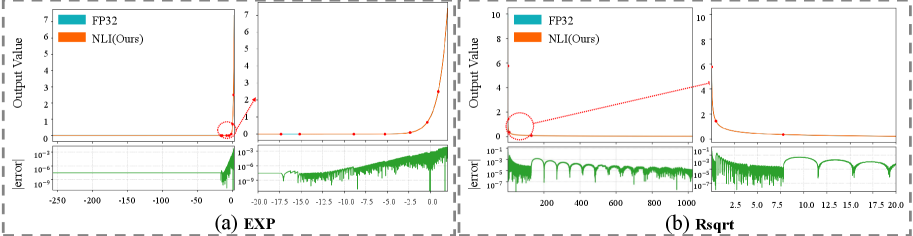
📊 实验亮点
实验结果表明,NLI引擎相比于最先进的设计,在计算效率上提升了4倍以上。同时,NLI能够以极小的精度损失(几乎可以忽略不计)逼近各种非线性函数,保证了LLM的性能。这些结果验证了NLI在加速LLM推理方面的有效性。
🎯 应用场景
NLI技术可广泛应用于各种需要高效推理的场景,如移动设备上的LLM部署、边缘计算设备上的AI应用、以及对计算资源敏感的嵌入式系统。通过降低非线性计算的成本,NLI可以显著提升这些场景下的AI应用性能,并降低能耗,从而加速AI技术的普及。
📄 摘要(原文)
Large Language Models (LLMs) have demonstrated remarkable performance across a wide range of tasks, but their deployment is often constrained by substantial memory footprints and computational costs. While prior work has achieved significant progress in compressing and accelerating linear layers, nonlinear layers-such as SiLU, RMSNorm, and Softmax-still heavily depend on high-precision floating-point operations. In this paper, we propose a calibration-free, dynamic-programming-optimal, and hardware-friendly framework called Non-uniform Linear Interpolation (NLI). NLI is capable of efficiently approximating a variety of nonlinear functions, enabling seamless integration into LLMs and other deep neural networks with almost no loss in accuracy. NLI ingeniously recasts cutpoint selection as a dynamic-programming problem, achieving the globally minimal interpolation error in O(MxN2) time via Bellman's optimality principle. Based on the NLI algorithm, we also design and implement a plug-and-play universal nonlinear computation unit. Hardware experiments demonstrate that the NLI Engine achieves more than 4x improvement in computational efficiency compared to the state-of-the-art designs.