Embedding Perturbation may Better Reflect the Uncertainty in LLM Reasoning
作者: Qihao Wen, Jiahao Wang, Yang Nan, Pengfei He, Ravi Tandon, Han Xu
分类: cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出基于嵌入扰动的不确定性量化方法,提升LLM推理过程不确定性评估。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性量化 嵌入扰动 推理过程 中间步骤
📋 核心要点
- 现有LLM推理不确定性量化方法难以有效评估中间步骤的不确定性,阻碍了细粒度干预。
- 通过扰动token嵌入,计算后续token对扰动的敏感度,以此量化中间推理步骤的不确定性。
- 实验表明,该方法在不确定性量化性能上优于token概率和熵等基线方法,且更简洁高效。
📝 摘要(中文)
大型语言模型(LLM)在各个领域取得了显著突破,但仍可能产生不可靠或误导性的输出。为了负责任地应用LLM,不确定性量化(UQ)技术被用于估计模型输出的不确定性,表明这些输出可能存在问题的可能性。对于LLM推理任务,不仅需要估计最终答案的不确定性,还需要估计推理的中间步骤的不确定性,因为这可以实现更细粒度和更有针对性的干预。本研究探讨了哪些UQ指标能更好地反映LLM在推理过程中的“中间不确定性”。研究表明,LLM不正确的推理步骤往往包含对前一个token嵌入的扰动高度敏感的token。因此,在实践中,可以使用这种敏感度得分作为指导,轻松识别不正确(不确定)的中间步骤。实验表明,与token(生成)概率和token熵等基线方法相比,这种基于扰动的指标实现了更强的不确定性量化性能。此外,与依赖于多次采样的方法不同,基于扰动的指标提供了更好的简洁性和效率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在推理过程中,中间步骤的不确定性难以有效量化的问题。现有方法,如基于token概率或熵的方法,无法准确反映中间推理步骤的可靠性,导致难以进行有针对性的干预,从而影响最终结果的准确性。
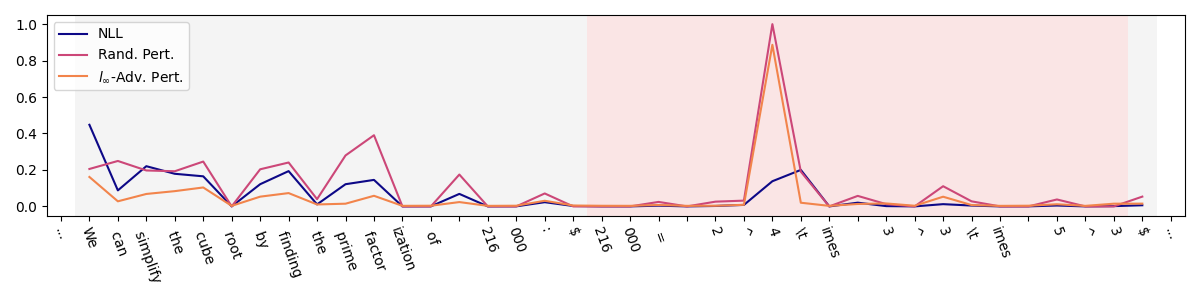
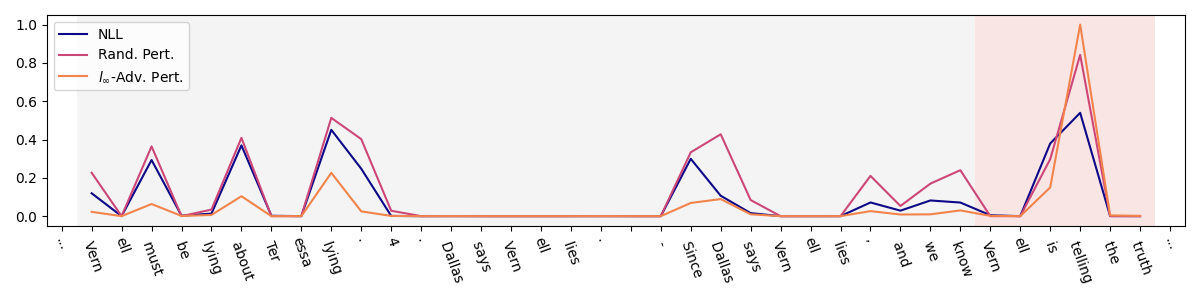
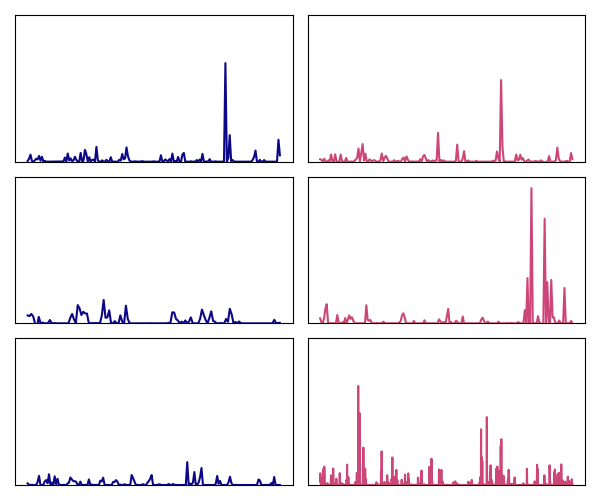
核心思路:论文的核心思路是,LLM在进行不正确的推理步骤时,其生成的token对前序token嵌入的微小扰动会表现出高度的敏感性。换句话说,如果一个token的生成强烈依赖于前一个token嵌入的特定表示,那么这个token很可能是不确定的。通过量化这种敏感性,可以有效地评估中间推理步骤的不确定性。
技术框架:该方法主要包含以下几个阶段:1) 对LLM的输入进行推理,获得中间步骤的token序列;2) 对每个token的前序token嵌入进行微小扰动;3) 测量在扰动下,当前token生成概率的变化;4) 使用生成概率的变化幅度作为不确定性度量,即敏感度得分。整体流程简单高效,无需多次采样。
关键创新:该方法最重要的创新点在于,它将token嵌入扰动与LLM推理过程中的不确定性联系起来,提出了一种新的不确定性量化指标。与传统的基于概率或熵的方法不同,该方法直接关注token对嵌入扰动的敏感性,从而更准确地反映了中间推理步骤的可靠性。
关键设计:关键设计包括:1) 扰动的大小和方向:论文需要确定合适的扰动幅度,既要足够小以保证不影响整体推理过程,又要足够大以能够检测到敏感性;2) 敏感度得分的计算方式:论文需要定义一个合适的函数来量化token生成概率的变化,例如使用KL散度或JS散度等。3) 如何将敏感度得分应用于实际的干预策略,例如,当敏感度得分超过某个阈值时,触发重新推理或人工干预。
🖼️ 关键图片
📊 实验亮点
实验结果表明,基于嵌入扰动的敏感度得分在不确定性量化方面优于传统的token概率和熵方法。该方法能够更准确地识别LLM推理过程中不正确的中间步骤,且计算效率更高,无需多次采样。具体性能提升数据未知。
🎯 应用场景
该研究成果可应用于对LLM推理过程进行监控和调试,提高LLM在医疗诊断、金融分析等高风险领域的可靠性。通过识别不确定的中间步骤,可以提前进行干预,避免错误结论的产生,并提升用户对LLM的信任度。未来可进一步探索如何利用不确定性信息进行主动学习和模型优化。
📄 摘要(原文)
Large language Models (LLMs) have achieved significant breakthroughs across diverse domains; however, they can still produce unreliable or misleading outputs. For responsible LLM application, Uncertainty Quantification (UQ) techniques are used to estimate a model's uncertainty about its outputs, indicating the likelihood that those outputs may be problematic. For LLM reasoning tasks, it is essential to estimate the uncertainty not only for the final answer, but also for the intermediate steps of the reasoning, as this can enable more fine-grained and targeted interventions. In this study, we explore what UQ metrics better reflect the LLM's ``intermediate uncertainty''during reasoning. Our study reveals that an LLMs' incorrect reasoning steps tend to contain tokens which are highly sensitive to the perturbations on the preceding token embeddings. In this way, incorrect (uncertain) intermediate steps can be readily identified using this sensitivity score as guidance in practice. In our experiments, we show such perturbation-based metric achieves stronger uncertainty quantification performance compared with baseline methods such as token (generation) probability and token entropy. Besides, different from approaches that rely on multiple sampling, the perturbation-based metrics offer better simplicity and efficiency.