Masked Autoencoders as Universal Speech Enhancer
作者: Rajalaxmi Rajagopalan, Ritwik Giri, Zhiqiang Tang, Kyu Han
分类: cs.SD, cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出基于掩码自编码器的通用语音增强器,实现自监督学习和多场景适应。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 语音增强 掩码自编码器 自监督学习 通用语音增强 去噪 去混响 预训练 迁移学习
📋 核心要点
- 现有监督语音增强方法依赖大量干净语音数据,实际应用中难以获取,限制了其泛化能力。
- 论文提出基于掩码自编码器的自监督学习框架,通过预训练学习通用的语音表征,无需配对数据。
- 实验表明,该方法在去噪和去混响等任务上,优于现有方法,并在领域内和领域外数据集上均取得SOTA性能。
📝 摘要(中文)
本文提出了一种基于掩码自编码器的通用语音增强器,该方法无需依赖干净语音,以自监督的方式学习,并且能够处理多种类型的语音失真。该模型通过一个增强堆栈对带噪输入数据添加额外的失真。掩码自编码器学习去除这些人为添加的失真,并重建频谱图的掩码区域。预训练得到的嵌入表示可以用于微调模型,以适应特定的下游任务,例如去噪和去混响。实验评估了预训练特征在这些下游任务上的性能。研究还探索了预训练增强堆栈中不同增强方法(如单说话人或多说话人)以及不同噪声输入特征表示(如$log1p$压缩)对预训练嵌入和下游微调增强性能的影响。结果表明,该方法不仅优于基线方法,而且在领域内和领域外评估数据集上均达到了最先进的性能。
🔬 方法详解
问题定义:现有的监督语音增强方法依赖于大量的干净语音数据,但在实际应用场景中,干净语音数据往往难以获取。此外,针对特定噪声类型训练的模型泛化能力有限,难以处理多种失真共存的情况。因此,需要一种能够自监督学习、适应多种失真类型的通用语音增强方法。
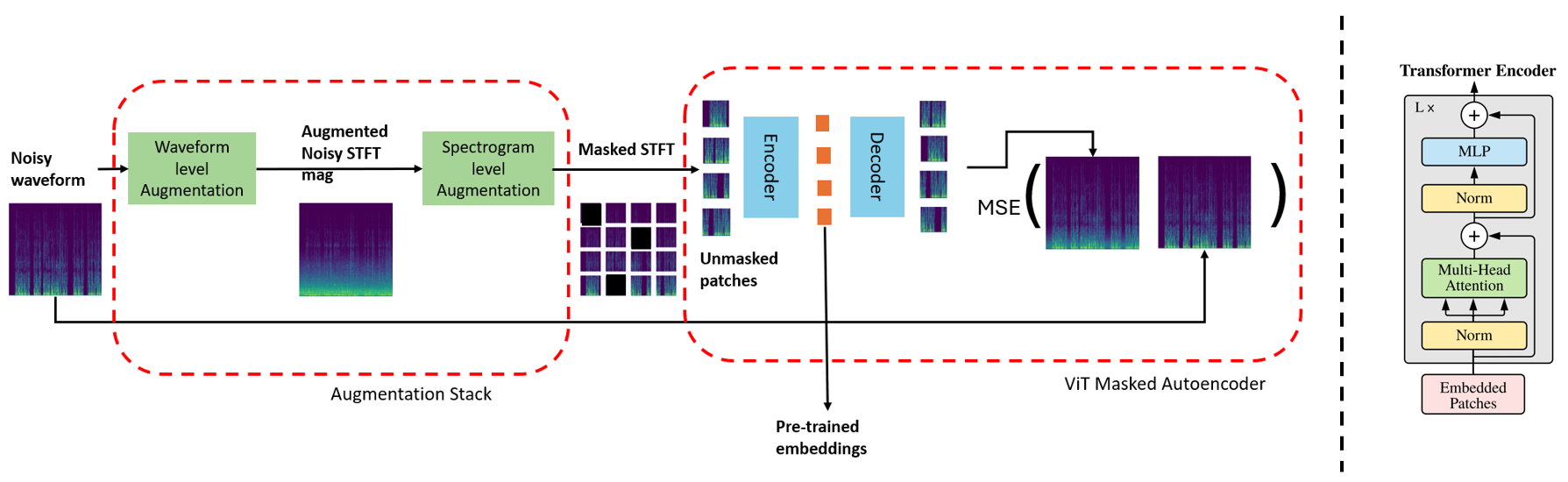
核心思路:论文的核心思路是利用掩码自编码器(MAE)进行自监督预训练,学习通用的语音表征。通过对带噪语音进行增强,并随机掩盖部分频谱图,迫使模型学习从剩余信息中重建原始语音,从而提高模型的鲁棒性和泛化能力。
技术框架:该方法主要包含两个阶段:预训练阶段和微调阶段。在预训练阶段,首先使用增强堆栈对带噪语音进行增强,然后随机掩盖部分频谱图。接着,将增强后的带噪语音输入到掩码自编码器中,模型学习重建原始频谱图。在微调阶段,使用少量配对数据(带噪语音和干净语音)对预训练模型进行微调,以适应特定的下游任务,如去噪和去混响。
关键创新:该方法的主要创新点在于:1) 提出了一种基于掩码自编码器的自监督语音增强框架,无需依赖大量配对数据;2) 通过增强堆栈和掩码策略,提高了模型的鲁棒性和泛化能力;3) 预训练得到的嵌入表示可以用于多种下游任务,实现了通用语音增强。与现有方法的本质区别在于,该方法采用自监督学习,避免了对大量干净语音数据的依赖。
关键设计:在预训练阶段,增强堆栈包含多种增强方法,如添加噪声、混响等。掩码比例设置为一个超参数,控制被掩盖的频谱图区域的比例。掩码自编码器的网络结构可以采用Transformer或其他自编码器结构。损失函数采用均方误差(MSE)或L1损失,用于衡量重建频谱图与原始频谱图之间的差异。
🖼️ 关键图片

📊 实验亮点
实验结果表明,该方法在去噪和去混响任务上均取得了显著的性能提升。在领域内数据集上,该方法优于基线方法,并在领域外数据集上达到了最先进的性能。通过调整预训练增强堆栈和输入特征表示,可以进一步提高模型的性能。例如,使用多说话人增强和$log1p$压缩可以获得更好的效果。
🎯 应用场景
该研究成果可广泛应用于语音通信、语音识别、助听器等领域。例如,在嘈杂环境下,可以利用该方法提高语音通信的清晰度;在语音识别系统中,可以提高识别的准确率;在助听器中,可以帮助听力受损人士更好地理解语音。此外,该方法还可以应用于语音合成、语音转换等领域,具有广阔的应用前景。
📄 摘要(原文)
Supervised speech enhancement methods have been very successful. However, in practical scenarios, there is a lack of clean speech, and self-supervised learning-based (SSL) speech enhancement methods that offer comparable enhancement performance and can be applied to other speech-related downstream applications are desired. In this work, we develop a masked autoencoder based universal speech enhancer that is agnostic to the type of distortion affecting speech, can handle multiple distortions simultaneously, and is trained in a self-supervised manner. An augmentation stack adds further distortions to the noisy input data. The masked autoencoder model learns to remove the added distortions along with reconstructing the masked regions of the spectrogram during pre-training. The pre-trained embeddings are then used by fine-tuning models trained on a small amount of paired data for specific downstream tasks. We evaluate the pre-trained features for denoising and dereverberation downstream tasks. We explore different augmentations (like single or multi-speaker) in the pre-training augmentation stack and the effect of different noisy input feature representations (like $log1p$ compression) on pre-trained embeddings and downstream fine-tuning enhancement performance. We show that the proposed method not only outperforms the baseline but also achieves state-of-the-art performance for both in-domain and out-of-domain evaluation datasets.