Didactic to Constructive: Turning Expert Solutions into Learnable Reasoning
作者: Ethan Mendes, Jungsoo Park, Alan Ritter
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
提出DAIL方法,利用少量专家解提升LLM推理能力并提高效率。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 模仿学习 分布对齐 对比学习 专家知识 推理能力 大型语言模型 样本高效
📋 核心要点
- 现有LLM推理能力提升依赖大量数据或更强模型,但难题难以解决,专家解的直接模仿因分布差异而失效。
- DAIL方法通过将专家解转化为详细推理轨迹,并使用对比学习聚焦专家知识,弥合分布差异。
- 实验表明,DAIL仅需少量专家解即可显著提升Qwen系列模型的推理性能和效率,并具备泛化能力。
📝 摘要(中文)
为了提升大型语言模型(LLM)的推理能力,通常依赖于模型采样正确解并进行强化学习,或者利用更强大的模型来解决问题。然而,许多难题对于当前最先进的模型来说仍然难以解决,阻碍了有效训练信号的提取。一个有希望的替代方案是利用高质量的专家人工解,但直接模仿这些数据是无效的,因为专家解通常是教学性的,包含面向人类读者而非计算模型的隐式推理差距。此外,高质量的专家解成本高昂,需要具有泛化能力的样本高效训练方法。我们提出了分布对齐模仿学习(DAIL),这是一种两步法,通过首先将专家解转换为详细的、分布内的推理轨迹来弥合分布差距,然后应用对比目标来集中学习专家见解和方法。我们发现,DAIL 可以利用少于 1000 个高质量的专家解,在 Qwen2.5-Instruct 和 Qwen3 模型上实现 10-25% 的 pass@k 增益,将推理效率提高 2 到 4 倍,并实现领域外泛化。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)在复杂推理任务中,难以有效利用少量高质量专家解进行学习的问题。现有方法要么依赖大量数据,要么需要更强大的模型作为指导,而直接模仿专家解又因专家解的教学性(包含隐式推理步骤)导致分布不匹配,效果不佳。
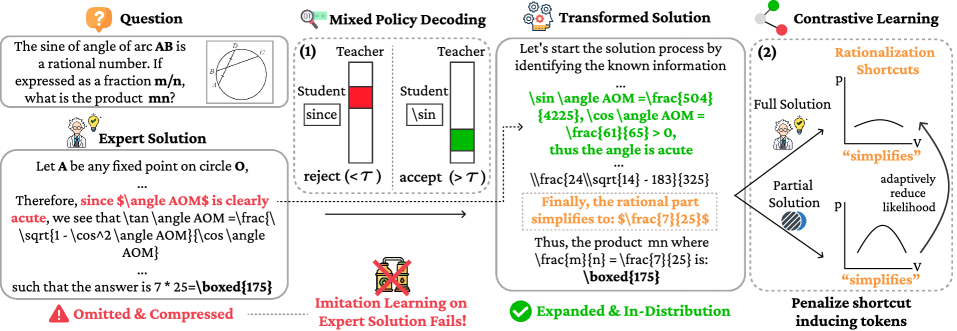
核心思路:论文的核心思路是通过分布对齐,将专家解转化为LLM更容易学习的、分布内的推理轨迹。具体来说,就是将专家解中隐含的推理步骤显式地补充出来,形成详细的推理过程,从而弥合专家解与LLM生成解之间的分布差异。然后,通过对比学习,让模型学习专家解中的关键推理步骤和方法。
技术框架:DAIL方法包含两个主要步骤:1) 专家解转换:将专家解转化为详细的推理轨迹,使其更符合LLM的生成分布。这一步可能涉及到对专家解进行分解、补充中间步骤等操作。2) 对比学习:使用对比损失函数,鼓励模型生成的推理轨迹与专家解的推理轨迹相似,同时区分不同的专家解。整体流程是先进行专家解的预处理,然后使用处理后的数据训练LLM。
关键创新:DAIL的关键创新在于其分布对齐的思想,即通过显式地补充推理步骤,将专家解转化为LLM更容易学习的形式。这避免了直接模仿专家解带来的分布不匹配问题,使得LLM能够更有效地利用少量高质量的专家解。此外,对比学习的使用也使得模型能够更好地学习专家解中的关键信息。
关键设计:论文中可能涉及的关键设计包括:1) 如何将专家解转化为详细的推理轨迹的具体方法,例如使用规则、模板或者其他LLM来生成中间步骤。2) 对比损失函数的具体形式,例如使用InfoNCE损失或者其他变体。3) 如何选择合适的负样本,以提高对比学习的效果。4) 如何平衡专家解和模型生成解之间的权重,以避免模型过度拟合专家解。
🖼️ 关键图片
📊 实验亮点
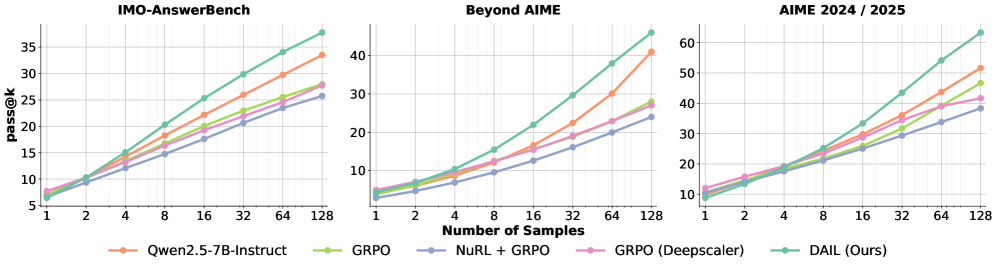
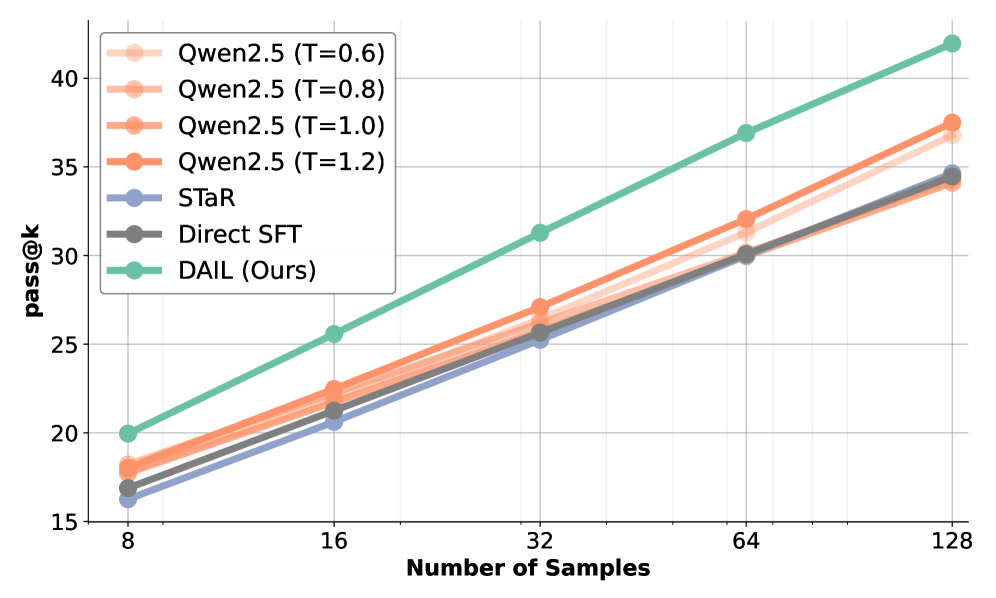
实验结果表明,DAIL方法在Qwen2.5-Instruct和Qwen3模型上实现了10-25%的pass@k增益,并且将推理效率提高了2到4倍。此外,DAIL还展现出了良好的领域外泛化能力,表明其学习到的推理方法具有通用性。
🎯 应用场景
DAIL方法可应用于各种需要复杂推理的场景,如数学问题求解、代码生成、知识图谱推理等。该方法能够有效利用少量专家知识,提升LLM在这些领域的性能,降低对大规模标注数据的依赖,具有重要的实际应用价值和潜力。
📄 摘要(原文)
Improving the reasoning capabilities of large language models (LLMs) typically relies either on the model's ability to sample a correct solution to be reinforced or on the existence of a stronger model able to solve the problem. However, many difficult problems remain intractable for even current frontier models, preventing the extraction of valid training signals. A promising alternative is to leverage high-quality expert human solutions, yet naive imitation of this data fails because it is fundamentally out of distribution: expert solutions are typically didactic, containing implicit reasoning gaps intended for human readers rather than computational models. Furthermore, high-quality expert solutions are expensive, necessitating generalizable sample-efficient training methods. We propose Distribution Aligned Imitation Learning (DAIL), a two-step method that bridges the distributional gap by first transforming expert solutions into detailed, in-distribution reasoning traces and then applying a contrastive objective to focus learning on expert insights and methodologies. We find that DAIL can leverage fewer than 1000 high-quality expert solutions to achieve 10-25% pass@k gains on Qwen2.5-Instruct and Qwen3 models, improve reasoning efficiency by 2x to 4x, and enable out-of-domain generalization.