An Empirical Study on Noisy Data and LLM Pretraining Loss Divergence
作者: Qizhen Zhang, Ankush Garg, Jakob Foerster, Niladri Chatterji, Kshitiz Malik, Mike Lewis
分类: cs.LG
发布日期: 2026-02-02
💡 一句话要点
研究噪声数据对LLM预训练损失发散的影响,揭示噪声类型、噪声量和模型规模的关键作用。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 预训练 噪声数据 损失发散 模型稳定性
📋 核心要点
- 大规模LLM预训练依赖海量数据,但Web数据固有的噪声可能导致训练不稳定甚至损失发散。
- 通过注入可控噪声,研究不同噪声类型、噪声量和模型规模对LLM训练动态的影响。
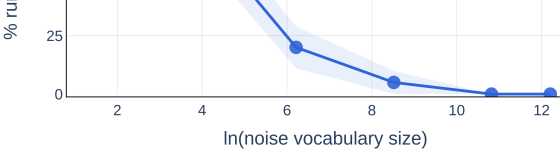
- 实验表明噪声确实会导致损失发散,且发散概率与噪声特性和模型规模密切相关,并提供了诊断工具。
📝 摘要(中文)
大规模预训练数据集是大型语言模型(LLM)成功的关键。然而,这些网络规模的语料库不可避免地包含大量噪声数据,这是由于不受监管的网络内容或数据中固有的随机性造成的。尽管LLM预训练人员经常推测这种噪声会导致大规模LLM预训练的不稳定性,在最坏的情况下会导致损失发散,但这种现象仍然知之甚少。本文对噪声数据是否会导致LLM预训练发散以及如何导致发散进行了系统的实证研究。通过将受控的合成均匀随机噪声注入到原本干净的数据集中,我们分析了模型规模从480M到5.2B参数的训练动态。我们表明,噪声数据确实会导致训练损失发散,并且发散的概率强烈依赖于噪声类型、噪声量和模型规模。我们进一步发现,噪声引起的发散表现出与高学习率引起的发散不同的激活模式,并且我们提供了区分这两种失效模式的诊断方法。总之,这些结果提供了一个大规模、受控的特征,描述了噪声数据如何影响LLM预训练中的损失发散。
🔬 方法详解
问题定义:论文旨在研究噪声数据对大型语言模型(LLM)预训练过程的影响,特别是关注噪声数据是否会导致训练损失发散。现有方法缺乏对噪声数据如何影响LLM训练动态的系统性理解,以及如何区分由噪声引起的发散和其他因素(如高学习率)引起的发散。
核心思路:论文的核心思路是通过向干净的数据集中注入可控的合成噪声,来模拟真实世界中LLM预训练数据集中存在的噪声。通过控制噪声的类型和数量,并观察不同模型规模下的训练动态,从而量化噪声对损失发散的影响。这种受控实验的方法能够更清晰地揭示噪声与损失发散之间的因果关系。
技术框架:该研究的技术框架主要包括以下几个步骤:1) 构建干净的预训练数据集;2) 向数据集中注入不同类型和数量的合成噪声;3) 使用不同规模的LLM模型(480M到5.2B参数)在噪声数据集上进行预训练;4) 监测训练过程中的损失函数变化,并记录损失发散的发生情况;5) 分析损失发散的激活模式,并与高学习率引起的发散进行比较;6) 开发诊断工具,用于区分不同原因引起的损失发散。
关键创新:该研究的关键创新在于其系统性和可控性。通过使用合成噪声,研究人员能够精确控制噪声的类型和数量,从而避免了真实世界数据集中噪声的复杂性和不确定性。此外,该研究还提出了区分噪声引起的发散和高学习率引起的发散的诊断方法,这对于实际LLM预训练过程中的问题排查具有重要意义。
关键设计:论文的关键设计包括:1) 使用均匀随机噪声作为合成噪声的主要类型;2) 采用不同规模的LLM模型,以研究模型规模对噪声鲁棒性的影响;3) 监测训练损失的变化,并定义损失发散的阈值;4) 分析损失发散时的激活模式,例如梯度范数和权重更新幅度;5) 开发基于激活模式的诊断工具,用于区分不同原因引起的损失发散。
🖼️ 关键图片

📊 实验亮点
实验结果表明,噪声数据确实会导致LLM预训练过程中的损失发散,且发散的概率与噪声类型、噪声量和模型规模密切相关。例如,在特定噪声水平下,模型规模越大,越容易发生损失发散。此外,研究还发现噪声引起的发散与高学习率引起的发散具有不同的激活模式,并提出了相应的诊断方法。
🎯 应用场景
该研究成果可应用于提升大型语言模型的预训练稳定性。通过理解噪声数据对训练的影响,可以设计更有效的数据清洗策略、更鲁棒的训练方法,并开发诊断工具来识别和解决训练过程中的问题。这有助于降低LLM预训练的成本和风险,并提高模型的性能和可靠性。
📄 摘要(原文)
Large-scale pretraining datasets drive the success of large language models (LLMs). However, these web-scale corpora inevitably contain large amounts of noisy data due to unregulated web content or randomness inherent in data. Although LLM pretrainers often speculate that such noise contributes to instabilities in large-scale LLM pretraining and, in the worst cases, loss divergence, this phenomenon remains poorly understood.In this work, we present a systematic empirical study of whether noisy data causes LLM pretraining divergences and how it does so. By injecting controlled synthetic uniformly random noise into otherwise clean datasets, we analyze training dynamics across model sizes ranging from 480M to 5.2B parameters. We show that noisy data indeed induces training loss divergence, and that the probability of divergence depends strongly on the noise type, amount of noise, and model scale. We further find that noise-induced divergences exhibit activation patterns distinct from those caused by high learning rates, and we provide diagnostics that differentiate these two failure modes. Together, these results provide a large-scale, controlled characterization of how noisy data affects loss divergence in LLM pretraining.