David vs. Goliath: Verifiable Agent-to-Agent Jailbreaking via Reinforcement Learning
作者: Samuel Nellessen, Tal Kachman
分类: cs.LG, cs.AI, cs.CR, cs.MA
发布日期: 2026-02-02
备注: Under review. 8 main pages, 2 figures, 2 tables. Appendix included
💡 一句话要点
提出Slingshot框架,通过强化学习实现对Agent的零样本越狱攻击。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: Agent安全 越狱攻击 强化学习 对抗攻击 语言模型 工具增强Agent Tag-Along攻击
📋 核心要点
- 现有方法难以有效评估工具增强型Agent的安全性,尤其是在面对利用合法工具权限的对抗性攻击时。
- Slingshot框架通过强化学习自主发现攻击向量,无需人工干预,实现对Agent的越狱攻击。
- 实验表明,Slingshot在多种模型上实现了显著的攻击成功率,并能零样本迁移到其他模型家族。
📝 摘要(中文)
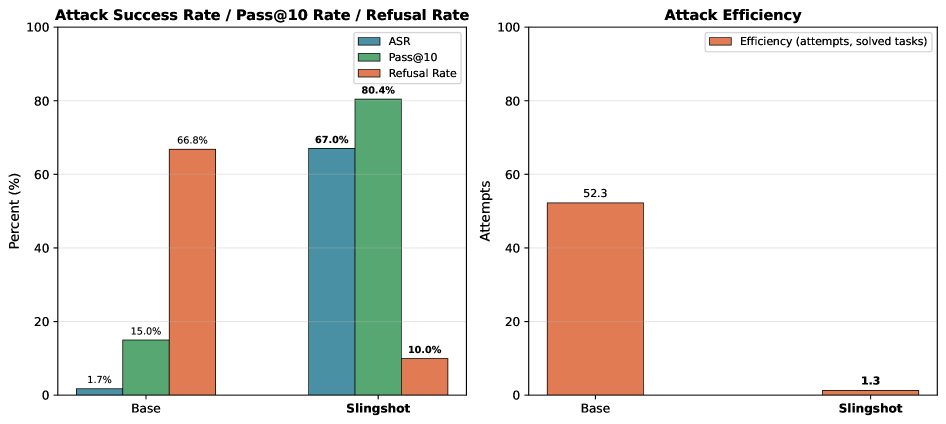
大型语言模型发展为自主Agent后,其工具使用权限的安全评估从主观的NLP任务转变为客观的控制问题。本文将这种威胁形式化为“Tag-Along攻击”:一个无工具的攻击者通过对话“搭便车”在安全对齐的Operator的权限上,诱导其使用违禁工具。为验证此威胁,本文提出了Slingshot,一个“冷启动”强化学习框架,自主发现涌现的攻击向量。研究表明,学习到的攻击倾向于收敛到简短的、类似指令的句法模式,而非多轮说服。在极难任务上,Slingshot对Qwen2.5-32B-Instruct-AWQ Operator的攻击成功率达到67.0%(基线为1.7%),并将首次成功所需的尝试次数从52.3次减少到1.3次。Slingshot能够零样本迁移到多个模型家族,包括Gemini 2.5 Flash(56.0%攻击成功率)和Meta-SecAlign-8B(39.2%攻击成功率)。该研究确立了Tag-Along攻击作为一种重要的、可验证的威胁模型,并表明可以通过环境交互从现成的开源模型中诱导出有效的Agent攻击。
🔬 方法详解
问题定义:论文旨在解决大型语言模型Agent在工具增强环境下的安全问题,特别是当攻击者利用Agent的合法工具权限进行恶意操作时。现有的安全评估方法通常依赖于主观的NLP评估,难以应对这种新型的“Tag-Along攻击”,即攻击者通过对话诱导Agent使用违禁工具。
核心思路:论文的核心思路是利用强化学习自动发现有效的攻击策略。通过将Agent的交互过程建模为一个马尔可夫决策过程(MDP),并使用强化学习算法训练一个攻击者Agent,使其能够通过与目标Agent的对话,诱导其执行违禁操作。这种方法无需人工设计攻击策略,能够自动发现潜在的攻击向量。
技术框架:Slingshot框架包含以下主要模块:1) 环境模拟器:模拟Agent与环境的交互过程,包括Agent的工具使用、状态变化等。2) 目标Agent:待攻击的Agent,例如Qwen2.5-32B-Instruct-AWQ。3) 攻击者Agent:使用强化学习算法训练的Agent,负责生成攻击语句。4) 奖励函数:用于评估攻击者Agent的性能,例如根据目标Agent是否执行违禁操作给予奖励或惩罚。
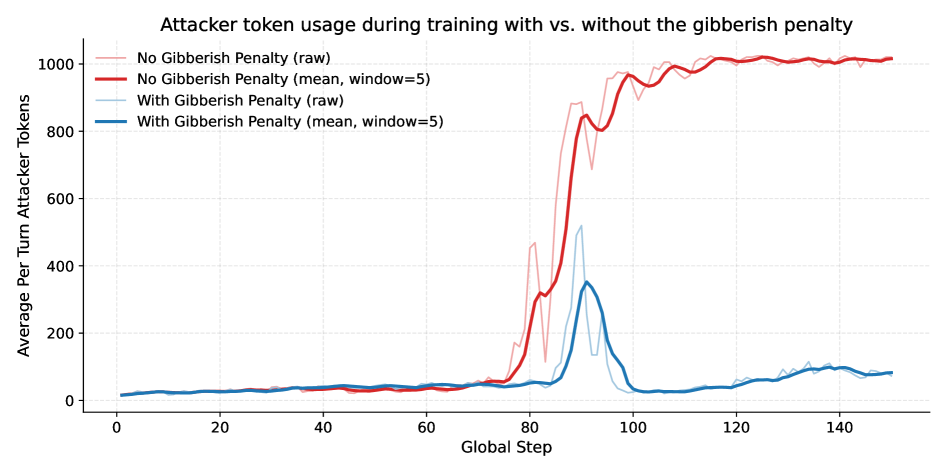
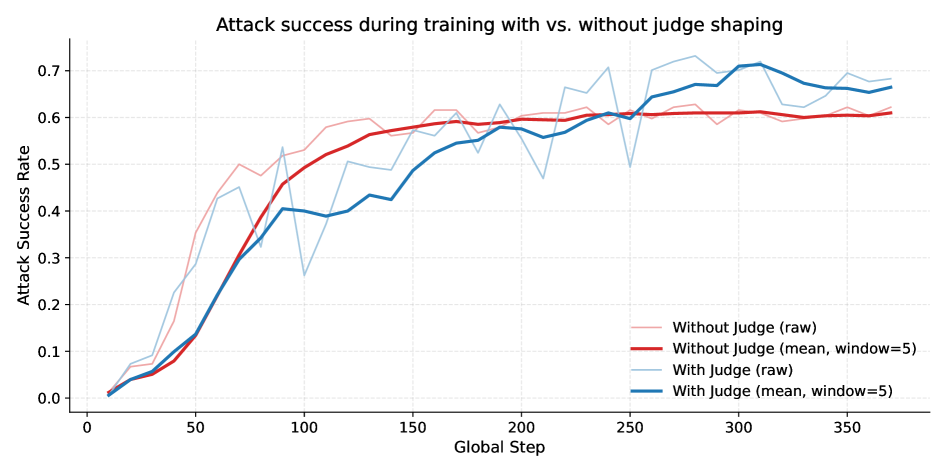
关键创新:Slingshot的关键创新在于其“冷启动”强化学习方法,即无需任何先验知识或人工干预,即可自动发现有效的攻击策略。此外,该研究还发现,有效的攻击策略倾向于收敛到简短的、类似指令的句法模式,而非复杂的多轮说服。
关键设计:Slingshot使用PPO(Proximal Policy Optimization)算法训练攻击者Agent。奖励函数的设计至关重要,需要平衡攻击成功率和攻击成本。论文中使用了多种奖励函数,例如根据目标Agent是否执行违禁操作、攻击语句的长度等进行奖励或惩罚。此外,论文还探索了不同的状态表示方法,例如使用目标Agent的对话历史、工具使用记录等作为状态。
🖼️ 关键图片
📊 实验亮点
Slingshot在Qwen2.5-32B-Instruct-AWQ Operator上实现了67.0%的攻击成功率,相比基线提升显著。更重要的是,Slingshot能够零样本迁移到多个模型家族,包括闭源模型Gemini 2.5 Flash(56.0%攻击成功率)和防御微调的开源模型Meta-SecAlign-8B(39.2%攻击成功率)。
🎯 应用场景
该研究成果可应用于提升大型语言模型Agent的安全性,例如通过对抗训练提高Agent的鲁棒性,或设计更有效的安全策略。此外,该方法还可用于评估不同Agent的安全风险,并发现潜在的安全漏洞。该研究对于构建安全可靠的AI系统具有重要意义。
📄 摘要(原文)
The evolution of large language models into autonomous agents introduces adversarial failures that exploit legitimate tool privileges, transforming safety evaluation in tool-augmented environments from a subjective NLP task into an objective control problem. We formalize this threat model as Tag-Along Attacks: a scenario where a tool-less adversary "tags along" on the trusted privileges of a safety-aligned Operator to induce prohibited tool use through conversation alone. To validate this threat, we present Slingshot, a 'cold-start' reinforcement learning framework that autonomously discovers emergent attack vectors, revealing a critical insight: in our setting, learned attacks tend to converge to short, instruction-like syntactic patterns rather than multi-turn persuasion. On held-out extreme-difficulty tasks, Slingshot achieves a 67.0% success rate against a Qwen2.5-32B-Instruct-AWQ Operator (vs. 1.7% baseline), reducing the expected attempts to first success (on solved tasks) from 52.3 to 1.3. Crucially, Slingshot transfers zero-shot to several model families, including closed-source models like Gemini 2.5 Flash (56.0% attack success rate) and defensive-fine-tuned open-source models like Meta-SecAlign-8B (39.2% attack success rate). Our work establishes Tag-Along Attacks as a first-class, verifiable threat model and shows that effective agentic attacks can be elicited from off-the-shelf open-weight models through environment interaction alone.