ReasonCACHE: Teaching LLMs To Reason Without Weight Updates
作者: Sharut Gupta, Phillip Isola, Stefanie Jegelka, David Lopez-Paz, Kartik Ahuja, Mark Ibrahim, Mohammad Pezeshki
分类: cs.LG, cs.AI
发布日期: 2026-02-02
备注: 26 pages, 17 Figures
💡 一句话要点
ReasonCACHE:无需权重更新,教LLM进行推理
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 上下文学习 大型语言模型 推理 Prefix Tuning 键值缓存
📋 核心要点
- 现有上下文学习(ICL)在复杂推理任务中需要大量示例,直接扩展会导致性能下降和成本增加。
- 提出ReasonCACHE,利用Prefix Tuning将演示知识提炼成固定键值缓存,无需权重更新即可推理。
- 实验表明,ReasonCACHE在推理基准上优于ICL,媲美IWL,同时更高效,且理论上更具表达力。
📝 摘要(中文)
大型语言模型(LLM)能否在不更新权重的情况下,仅通过上下文学习(ICL)来学习推理?ICL在样本效率方面表现出色,通常只需少量演示即可学习,但复杂的推理任务通常需要大量的训练示例。然而,通过简单地增加演示来扩展ICL会失效:注意力成本呈二次方增长,性能随着上下文长度的增加而饱和或下降,并且该方法仍然是一种浅层学习形式。由于这些限制,从业者主要依赖于权重内学习(IWL)来诱导推理。在这项工作中,我们表明,通过使用Prefix Tuning,LLM可以在不超载上下文窗口且不进行任何权重更新的情况下学习推理。我们引入了ReasonCACHE,它是这种机制的一个实例,将演示提炼成一个固定的键值缓存。在包括GPQA-Diamond在内的具有挑战性的推理基准测试中,ReasonCACHE优于标准ICL,并且与IWL方法相匹配或超过。此外,它在数据、推理成本和可训练参数这三个关键方面都更加高效。我们还在理论上证明了ReasonCACHE可以严格地比低秩权重更新更具表现力,因为后者将表现力与输入秩联系起来,而ReasonCACHE通过直接将键值注入注意力机制来绕过此约束。总之,我们的发现将ReasonCACHE确定为上下文学习和权重内学习之间的一种中间路径,提供了一种可扩展的算法,用于学习超出上下文窗口的推理技能,而无需修改参数。
🔬 方法详解
问题定义:论文旨在解决大型语言模型在复杂推理任务中,传统上下文学习方法面临的挑战。现有方法,如直接增加上下文示例,会导致注意力机制计算成本呈平方级增长,同时性能提升有限甚至下降。此外,这种方法本质上是浅层学习,难以捕捉深层次的推理逻辑。权重内学习虽然有效,但需要更新模型参数,成本较高。
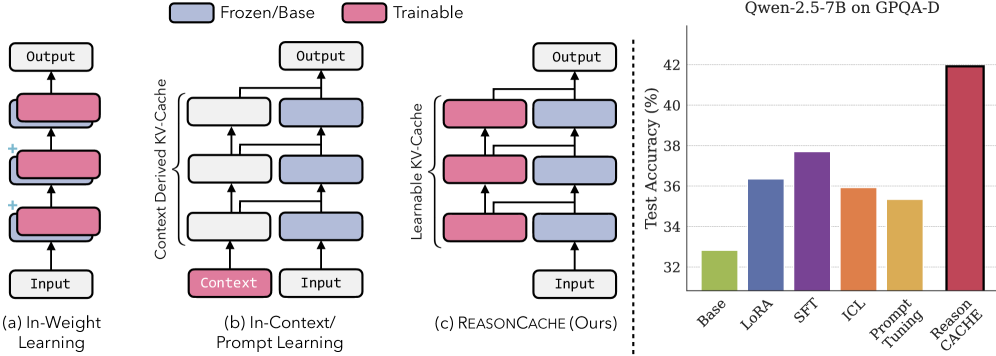
核心思路:论文的核心思路是利用Prefix Tuning,将大量的推理示例压缩成一个固定大小的键值缓存(ReasonCACHE)。这样,模型在推理时,可以通过检索缓存中的相关信息,而无需直接处理大量的上下文示例,从而避免了计算成本的增加和性能的下降。这种方法既保留了上下文学习的灵活性,又避免了权重更新的开销。
技术框架:ReasonCACHE的整体框架包括以下几个主要步骤:1) 使用Prefix Tuning训练一个小型的前缀编码器,将推理示例编码成键值对。2) 将这些键值对存储在一个固定大小的缓存中。3) 在推理时,根据输入查询,从缓存中检索最相关的键值对。4) 将检索到的键值对作为前缀添加到输入中,然后输入到大型语言模型进行推理。整个过程无需更新大型语言模型的权重。
关键创新:ReasonCACHE的关键创新在于它将上下文学习和Prefix Tuning结合起来,创造了一种新的推理学习范式。与传统的上下文学习相比,ReasonCACHE可以处理更多的推理示例,而不会导致计算成本的增加。与权重内学习相比,ReasonCACHE无需更新模型参数,更加高效。此外,论文还从理论上证明了ReasonCACHE比低秩权重更新更具表达力。
关键设计:ReasonCACHE的关键设计包括:1) 使用Prefix Tuning来训练前缀编码器,这可以有效地将推理示例编码成键值对。2) 使用固定大小的缓存来存储键值对,这可以控制计算成本。3) 使用合适的检索算法来从缓存中检索最相关的键值对。具体的参数设置和损失函数取决于具体的任务和数据集,论文中给出了详细的实验设置。
🖼️ 关键图片
📊 实验亮点
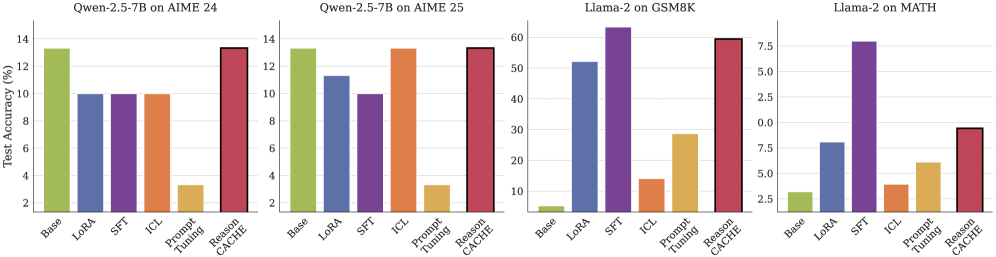
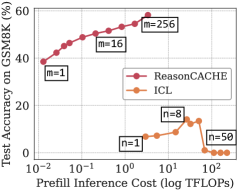
ReasonCACHE在GPQA-Diamond等具有挑战性的推理基准测试中,性能优于标准ICL,并与IWL方法相匹配或超过。更重要的是,ReasonCACHE在数据效率、推理成本和可训练参数数量方面都表现出更高的效率。例如,在某些任务上,ReasonCACHE仅需少量示例即可达到与IWL相当的性能,同时避免了权重更新的开销。
🎯 应用场景
ReasonCACHE具有广泛的应用前景,可用于提升大型语言模型在各种推理任务中的性能,例如问答、数学问题求解、代码生成等。该方法尤其适用于资源受限的场景,例如移动设备或边缘计算环境,因为其无需更新模型参数,降低了计算和存储成本。未来,ReasonCACHE可以进一步扩展到其他类型的任务和模型,例如多模态推理和视觉语言模型。
📄 摘要(原文)
Can Large language models (LLMs) learn to reason without any weight update and only through in-context learning (ICL)? ICL is strikingly sample-efficient, often learning from only a handful of demonstrations, but complex reasoning tasks typically demand many training examples to learn from. However, naively scaling ICL by adding more demonstrations breaks down at this scale: attention costs grow quadratically, performance saturates or degrades with longer contexts, and the approach remains a shallow form of learning. Due to these limitations, practitioners predominantly rely on in-weight learning (IWL) to induce reasoning. In this work, we show that by using Prefix Tuning, LLMs can learn to reason without overloading the context window and without any weight updates. We introduce $\textbf{ReasonCACHE}$, an instantiation of this mechanism that distills demonstrations into a fixed key-value cache. Empirically, across challenging reasoning benchmarks, including GPQA-Diamond, ReasonCACHE outperforms standard ICL and matches or surpasses IWL approaches. Further, it achieves this all while being more efficient across three key axes: data, inference cost, and trainable parameters. We also theoretically prove that ReasonCACHE can be strictly more expressive than low-rank weight update since the latter ties expressivity to input rank, whereas ReasonCACHE bypasses this constraint by directly injecting key-values into the attention mechanism. Together, our findings identify ReasonCACHE as a middle path between in-context and in-weight learning, providing a scalable algorithm for learning reasoning skills beyond the context window without modifying parameters. Our project page: https://reasoncache.github.io/