EvalQReason: A Framework for Step-Level Reasoning Evaluation in Large Language Models
作者: Shaima Ahmad Freja, Ferhat Ozgur Catak, Betul Yurdem, Chunming Rong
分类: cs.LG
发布日期: 2026-02-02
备注: 15 pages (including appendix), 11 figures
💡 一句话要点
提出EvalQReason框架以解决大语言模型推理评估问题
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 推理评估 大语言模型 概率分布分析 机器学习 医疗应用 数学推理 可解释性AI
📋 核心要点
- 现有方法主要关注最终答案的正确性,缺乏对推理过程的逐步评估,限制了对模型推理能力的深入理解。
- EvalQReason框架通过引入CSD和SFC算法,提供了一种无须人工标注的逐步推理质量量化方法,增强了推理过程的可解释性。
- 实验表明,CSD特征在正确性分类中表现优异,序列神经模型的性能显著提升,显示出推理动态的领域特异性。
📝 摘要(中文)
大语言模型(LLMs)在关键应用中越来越多地被部署,但其内部推理过程的系统评估仍然困难。现有方法主要关注最终答案的正确性,无法深入了解推理过程中的中间步骤。本文提出EvalQReason框架,通过逐步概率分布分析量化LLM推理质量,无需人工标注。框架引入了两个互补算法:连续步骤差异(CSD)和步骤到最终收敛(SFC),分别测量相邻推理步骤之间的局部一致性和与最终答案的全局对齐。实验结果显示,CSD特征在正确性分类中表现出色,经典机器学习模型的F1值为0.78,ROC-AUC为0.82,而序列神经模型显著提升至F1=0.88,ROC-AUC=0.97。CSD在性能上优于SFC,推理动态表现出领域特异性。
🔬 方法详解
问题定义:本文旨在解决大语言模型推理过程的系统评估问题,现有方法仅关注最终答案的正确性,无法深入分析推理过程中的中间步骤。
核心思路:EvalQReason框架通过逐步概率分布分析,量化LLM的推理质量,采用CSD和SFC算法来评估推理的局部一致性和全局对齐,提供了无须人工标注的评估方式。
技术框架:EvalQReason框架包括两个主要模块:CSD算法用于测量相邻推理步骤之间的局部一致性,SFC算法用于评估推理过程与最终答案的全局对齐。每个算法使用五个统计指标来捕捉推理动态。
关键创新:CSD和SFC算法的引入是本文的主要创新,CSD通过分析相邻步骤的差异性,能够更好地反映推理过程的质量,而SFC则关注最终答案的对齐情况,这种双重评估方式与现有方法形成了显著区别。
关键设计:在算法设计中,CSD和SFC均采用了五个统计指标来捕捉推理动态,实验中使用了开源的7B参数模型,确保了评估的广泛适用性和有效性。实验结果显示,序列神经模型在推理质量评估中表现优于传统的机器学习模型。
🖼️ 关键图片
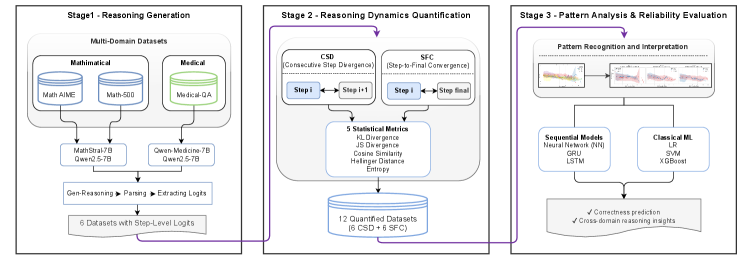
📊 实验亮点
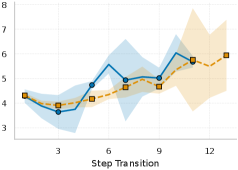
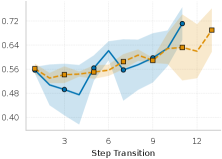
实验结果显示,基于CSD的特征在正确性分类中表现优异,经典机器学习模型的F1值达到0.78,ROC-AUC为0.82,而使用序列神经模型后,F1值提升至0.88,ROC-AUC达到0.97,显示出显著的性能提升。CSD在推理动态评估中优于SFC,且不同领域的推理动态表现出明显差异。
🎯 应用场景
EvalQReason框架具有广泛的应用潜力,尤其在需要高可靠性推理的领域,如医疗诊断和数学问题解决等。通过提供对推理过程的深入分析,该框架能够帮助开发更可信赖的人工智能系统,提升其在实际应用中的表现和安全性。
📄 摘要(原文)
Large Language Models (LLMs) are increasingly deployed in critical applications requiring reliable reasoning, yet their internal reasoning processes remain difficult to evaluate systematically. Existing methods focus on final-answer correctness, providing limited insight into how reasoning unfolds across intermediate steps. We present EvalQReason, a framework that quantifies LLM reasoning quality through step-level probability distribution analysis without requiring human annotation. The framework introduces two complementary algorithms: Consecutive Step Divergence (CSD), which measures local coherence between adjacent reasoning steps, and Step-to-Final Convergence (SFC), which assesses global alignment with final answers. Each algorithm employs five statistical metrics to capture reasoning dynamics. Experiments across mathematical and medical datasets with open-source 7B-parameter models demonstrate that CSD-based features achieve strong predictive performance for correctness classification, with classical machine learning models reaching F1=0.78 and ROC-AUC=0.82, and sequential neural models substantially improving performance (F1=0.88, ROC-AUC=0.97). CSD consistently outperforms SFC, and sequential architectures outperform classical machine learning approaches. Critically, reasoning dynamics prove domain-specific: mathematical reasoning exhibits clear divergence-based discrimination patterns between correct and incorrect solutions, while medical reasoning shows minimal discriminative signals, revealing fundamental differences in how LLMs process different reasoning types. EvalQReason enables scalable, process-aware evaluation of reasoning reliability, establishing probability-based divergence analysis as a principled approach for trustworthy AI deployment.