An Optimization Method for Autoregressive Time Series Forecasting
作者: Zheng Li, Jerry Cheng, Huanying Gu
分类: cs.LG, cs.AI
发布日期: 2026-02-02
备注: 10 pages, 2 figures, 2 tables
🔗 代码/项目: GITHUB
💡 一句话要点
提出一种优化自回归时间序列预测的新方法,提升长程预测精度。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 时间序列预测 自回归模型 长程预测 因果关系 损失函数 优化方法 Transformer 深度学习
📋 核心要点
- 现有时间序列预测模型依赖扩大模型规模实现长程预测,忽略了时间序列的因果关系,限制了预测性能。
- 该论文提出一种新的训练方法,通过在损失函数中惩罚违反自回归预测误差单调递增的现象,强化时间因果性。
- 实验表明,该方法在多个基准测试中取得了显著的性能提升,MSE降低超过10%,并能有效扩展预测范围。
📝 摘要(中文)
当前的时间序列预测模型主要基于Transformer架构的神经网络。这些模型主要通过扩大模型规模来实现长期预测,而不是通过真正的自回归(AR)展开。从大型语言模型训练的角度来看,传统的时间序列预测模型训练过程忽略了时间因果关系。本文提出了一种新的时间序列预测训练方法,该方法强制执行两个关键属性:(1)AR预测误差应随预测范围的增加而增加。任何违反此原则的行为都被认为是随机猜测,并在损失函数中明确惩罚;(2)该方法使模型能够连接短期AR预测,从而形成灵活的长期预测。实验结果表明,我们的方法在多个基准测试中建立了新的state-of-the-art,与iTransformer和其他最新的强大基线相比,MSE降低了10%以上。此外,它使短程预测模型能够在超过7.5倍的更长范围内执行可靠的长期预测。
🔬 方法详解
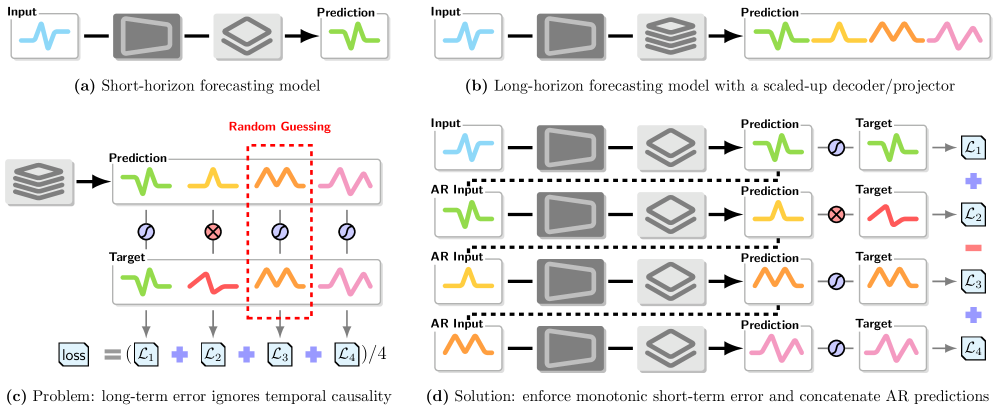
问题定义:现有时间序列预测模型,特别是基于Transformer的模型,在长程预测中过度依赖模型规模的扩大,而忽略了时间序列固有的自回归特性和时间因果关系。这导致模型难以捕捉时间序列的长期依赖性,预测精度受到限制。传统训练方法没有对违反时间因果关系的预测行为进行惩罚,使得模型容易产生不合理的预测结果。
核心思路:论文的核心思路是通过在训练过程中显式地强化时间因果关系,来提升模型的长程预测能力。具体而言,论文提出了一种新的训练方法,该方法的核心在于惩罚违反自回归预测误差单调递增的现象。这意味着,随着预测范围的增加,预测误差应该相应增加,否则将被视为随机猜测并受到惩罚。
技术框架:该方法主要包含以下几个阶段:首先,使用标准的自回归模型进行短期预测。然后,计算每个预测步长的预测误差。接着,根据预测范围计算误差的单调性约束。最后,将单调性约束融入到损失函数中,用于训练模型。整体框架是在现有时间序列预测模型的基础上,增加了一个正则化项,用于约束预测误差的单调性。
关键创新:该论文最重要的技术创新点在于提出了一个显式的损失函数,用于惩罚违反自回归预测误差单调递增的现象。与现有方法相比,该方法不是简单地扩大模型规模或使用更复杂的网络结构,而是从训练的角度出发,通过强化时间因果关系来提升模型的预测能力。这种方法能够有效地提高模型的泛化能力和鲁棒性。
关键设计:关键设计在于损失函数的设计。损失函数包含两部分:一部分是标准的预测误差损失,另一部分是单调性约束损失。单调性约束损失用于惩罚违反自回归预测误差单调递增的现象。具体而言,该损失函数计算相邻预测步长的误差差,如果误差差小于零,则施加一个惩罚。惩罚的大小与误差差的绝对值成正比。此外,论文还对惩罚项的权重进行了调整,以平衡预测精度和单调性约束。
🖼️ 关键图片
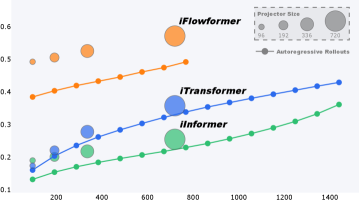

📊 实验亮点
实验结果表明,该方法在多个基准数据集上取得了显著的性能提升。与iTransformer和其他最新的强大基线相比,MSE降低了10%以上。更重要的是,该方法使得短程预测模型能够在超过7.5倍的更长范围内执行可靠的长期预测,这表明该方法能够有效地提高模型的长程预测能力。
🎯 应用场景
该研究成果可广泛应用于需要长期时间序列预测的领域,例如金融市场预测、供应链管理、能源需求预测、气候变化建模等。通过提高长程预测的准确性和可靠性,可以帮助决策者更好地制定策略,降低风险,提高效率。该方法还有潜力应用于其他序列预测任务,例如自然语言处理中的文本生成和语音识别。
📄 摘要(原文)
Current time-series forecasting models are primarily based on transformer-style neural networks. These models achieve long-term forecasting mainly by scaling up the model size rather than through genuinely autoregressive (AR) rollout. From the perspective of large language model training, the traditional training process for time-series forecasting models ignores temporal causality. In this paper, we propose a novel training method for time-series forecasting that enforces two key properties: (1) AR prediction errors should increase with the forecasting horizon. Any violation of this principle is considered random guessing and is explicitly penalized in the loss function, and (2) the method enables models to concatenate short-term AR predictions for forming flexible long-term forecasts. Empirical results demonstrate that our method establishes a new state-of-the-art across multiple benchmarks, achieving an MSE reduction of more than 10% compared to iTransformer and other recent strong baselines. Furthermore, it enables short-horizon forecasting models to perform reliable long-term predictions at horizons over 7.5 times longer. Code is available at https://github.com/LizhengMathAi/AROpt