Segment to Focus: Guiding Latent Action Models in the Presence of Distractors
作者: Hamza Adnan, Matthew T. Jackson, Alexey Zakharov
分类: cs.LG, cs.CV
发布日期: 2026-02-02
💡 一句话要点
MaskLAM:通过视觉分割引导潜在动作模型,解决背景干扰问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 潜在动作模型 强化学习 视觉分割 背景干扰 表征学习
📋 核心要点
- LAMs易受背景噪声干扰,导致学习次优的潜在动作空间,影响强化学习效果。
- MaskLAM利用预训练分割模型,通过掩码加权重建损失,聚焦于智能体,抑制背景干扰。
- 实验表明,MaskLAM在含噪声的MuJoCo环境中,奖励提升4倍,潜在动作质量提升3倍。
📝 摘要(中文)
潜在动作模型(LAMs)旨在仅从原始观测中提取与动作相关的表征,从而实现从无标签视频中进行强化学习,并显著扩展可用的训练数据。然而,LAMs面临着一个关键挑战,即如何将动作相关特征与动作相关的噪声(例如,背景运动)分离。未能过滤这些干扰因素会导致LAMs捕获虚假相关性并构建次优的潜在动作空间。本文提出MaskLAM,这是一种对LAM训练的轻量级修改,通过结合视觉智能体分割来缓解此问题。MaskLAM利用预训练基础模型提供的分割掩码来加权LAM重建损失,从而优先考虑显著信息而非背景元素,而无需修改架构。我们在连续控制的MuJoCo任务上验证了该方法的有效性,这些任务被修改为包含与动作相关的背景噪声。与标准基线相比,我们的方法使累积奖励提高了4倍,潜在动作质量提高了3倍,这可以通过线性探针评估来证明。
🔬 方法详解
问题定义:论文旨在解决潜在动作模型(LAMs)在存在动作相关背景干扰时,难以有效提取动作相关特征的问题。现有LAMs容易受到背景噪声的影响,导致学习到的潜在动作空间质量不高,进而影响强化学习的性能。痛点在于如何区分动作相关的关键信息和背景干扰,避免模型学习到虚假的相关性。
核心思路:论文的核心思路是利用视觉分割信息来引导LAMs的学习过程,使其更加关注智能体本身,而忽略背景干扰。通过对重建损失进行加权,使得模型在重建智能体区域时更加重视,从而提高学习到的潜在动作空间的质量。
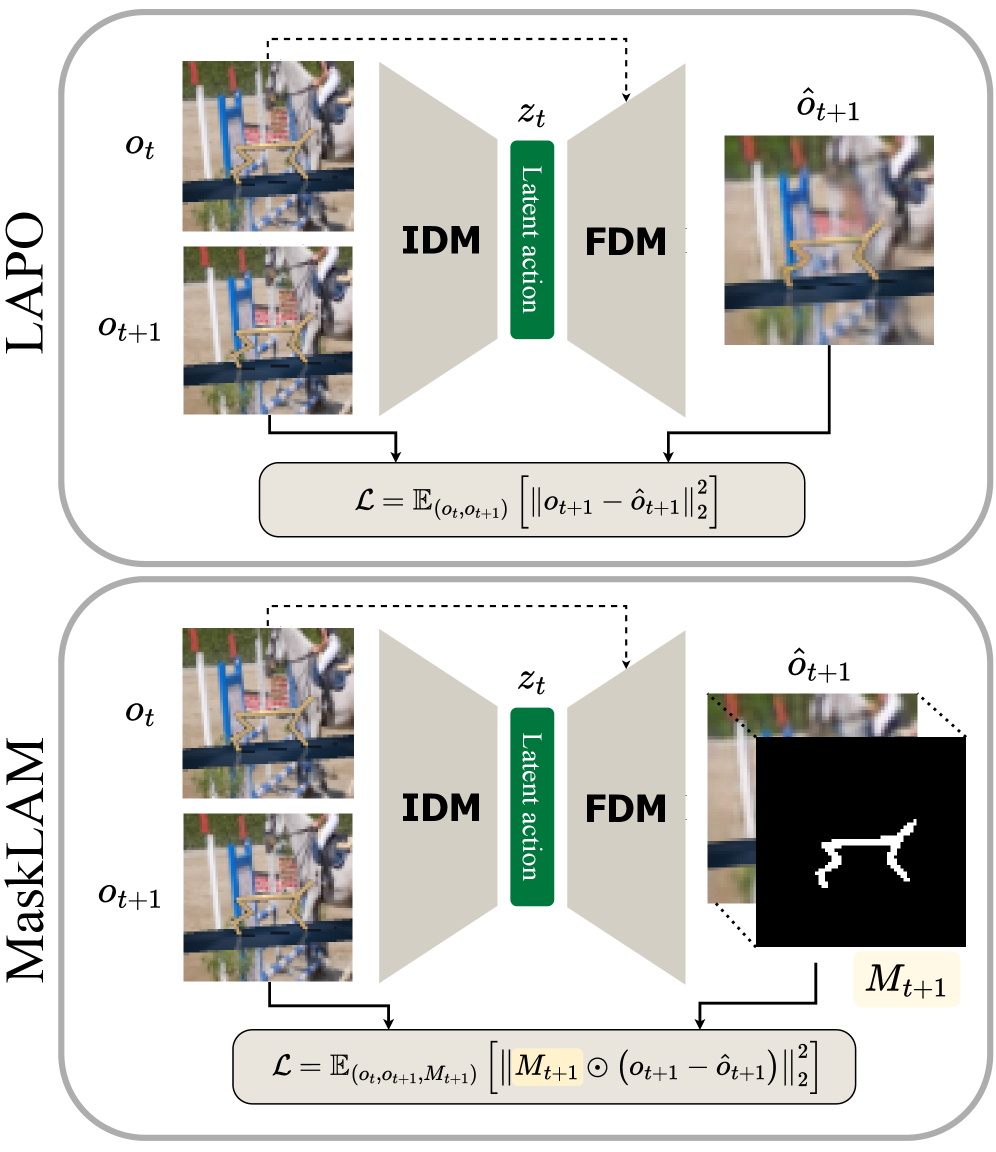
技术框架:MaskLAM的整体框架是在标准的LAM训练流程中加入一个分割模块。首先,使用预训练的分割模型生成智能体的分割掩码。然后,将该掩码用于加权LAM的重建损失,使得模型更加关注智能体区域的重建。整个流程不需要修改LAM的架构,只需要在损失函数上进行修改。
关键创新:MaskLAM的关键创新在于利用预训练的视觉分割模型来指导LAM的学习。与传统的LAM方法相比,MaskLAM能够有效地过滤掉背景干扰,从而学习到更加鲁棒和高质量的潜在动作空间。这种方法不需要手动设计特征,而是通过数据驱动的方式学习到与动作相关的表征。
关键设计:MaskLAM的关键设计在于如何利用分割掩码来加权重建损失。具体来说,论文使用分割掩码对重建损失进行逐像素的加权,使得智能体区域的像素具有更高的权重,而背景区域的像素具有较低的权重。这种加权方式可以有效地引导模型关注智能体区域,从而提高学习到的潜在动作空间的质量。损失函数的具体形式未知,但核心思想是分割掩码与重建误差相乘。
🖼️ 关键图片


📊 实验亮点
实验结果表明,MaskLAM在包含动作相关背景噪声的MuJoCo任务中,相比标准基线方法,累积奖励提高了4倍,潜在动作质量提高了3倍(通过线性探针评估)。这些结果表明,MaskLAM能够有效地过滤掉背景干扰,并学习到更加鲁棒和高质量的潜在动作空间,从而显著提高强化学习的性能。
🎯 应用场景
MaskLAM具有广泛的应用前景,例如在自动驾驶、机器人控制等领域,可以帮助智能体在复杂的环境中更好地理解和执行动作。通过过滤掉背景干扰,MaskLAM可以提高智能体的鲁棒性和泛化能力,使其能够在不同的场景下稳定工作。此外,该方法还可以应用于视频游戏等领域,帮助智能体更好地理解游戏环境并做出决策。
📄 摘要(原文)
Latent Action Models (LAMs) learn to extract action-relevant representations solely from raw observations, enabling reinforcement learning from unlabelled videos and significantly scaling available training data. However, LAMs face a critical challenge in disentangling action-relevant features from action-correlated noise (e.g., background motion). Failing to filter these distractors causes LAMs to capture spurious correlations and build sub-optimal latent action spaces. In this paper, we introduce MaskLAM -- a lightweight modification to LAM training to mitigate this issue by incorporating visual agent segmentation. MaskLAM utilises segmentation masks from pretrained foundation models to weight the LAM reconstruction loss, thereby prioritising salient information over background elements while requiring no architectural modifications. We demonstrate the effectiveness of our method on continuous-control MuJoCo tasks, modified with action-correlated background noise. Our approach yields up to a 4x increase in accrued rewards compared to standard baselines and a 3x improvement in the latent action quality, as evidenced by linear probe evaluation.