Learning While Staying Curious: Entropy-Preserving Supervised Fine-Tuning via Adaptive Self-Distillation for Large Reasoning Models
作者: Hao Wang, Hao Gu, Hongming Piao, Kaixiong Gong, Yuxiao Ye, Xiangyu Yue, Sirui Han, Yike Guo, Dapeng Wu
分类: cs.LG, cs.CL
发布日期: 2026-02-02
💡 一句话要点
CurioSFT:通过自适应自蒸馏保持熵的监督微调,提升大型推理模型的探索能力
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 大型语言模型 监督微调 强化学习 自蒸馏 熵正则化 探索能力 数学推理
📋 核心要点
- 现有SFT方法导致模型过度自信和生成多样性降低,限制了后续RL阶段的探索空间。
- CurioSFT通过自探索蒸馏和熵引导的温度选择,在SFT阶段保持模型的探索能力。
- 实验表明,CurioSFT在SFT和RL阶段均优于传统方法,提升了数学推理任务的性能。
📝 摘要(中文)
针对大型推理模型,监督微调(SFT)后进行强化学习(RL)的标准流程可能限制RL阶段的收益。SFT模仿专家示范,但常导致过度自信和生成多样性降低,缩小了RL的探索空间。在SFT中加入熵正则化并非万能之策,它倾向于将token分布扁平化,增加熵但未提升有意义的探索能力。本文提出CurioSFT,一种保持熵的SFT方法,旨在通过内在好奇心增强探索能力。它包含:(a) 自探索蒸馏,将模型蒸馏到自生成的、温度缩放的教师模型,鼓励在其能力范围内进行探索;(b) 熵引导的温度选择,自适应调整蒸馏强度,通过放大推理token的探索并稳定事实token来缓解知识遗忘。在数学推理任务上的实验表明,在SFT阶段,CurioSFT在同分布任务上优于vanilla SFT 2.5个点,在异分布任务上优于2.9个点。同时验证了SFT阶段保留的探索能力成功转化为RL阶段的实际收益,平均提升5.0个点。
🔬 方法详解
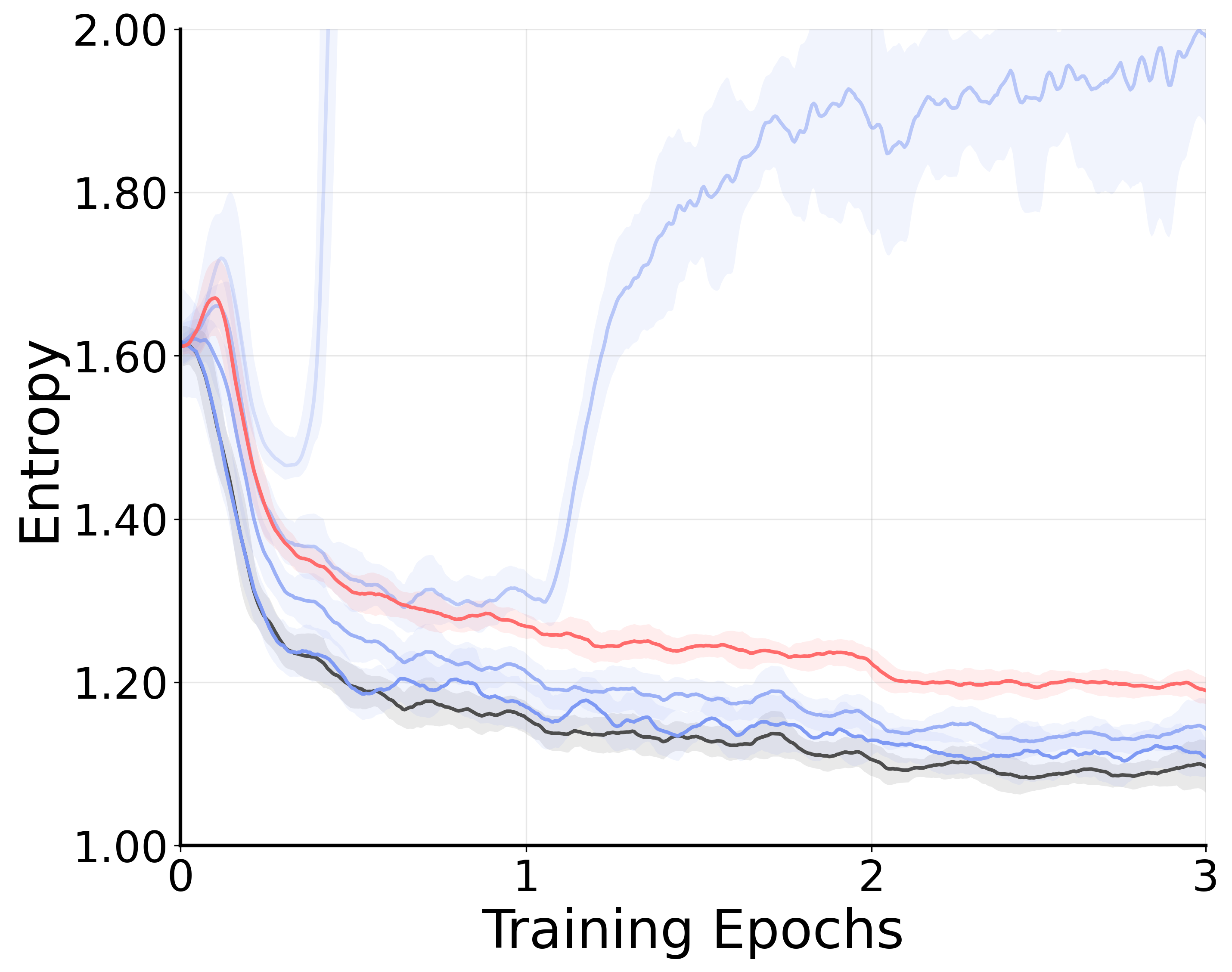
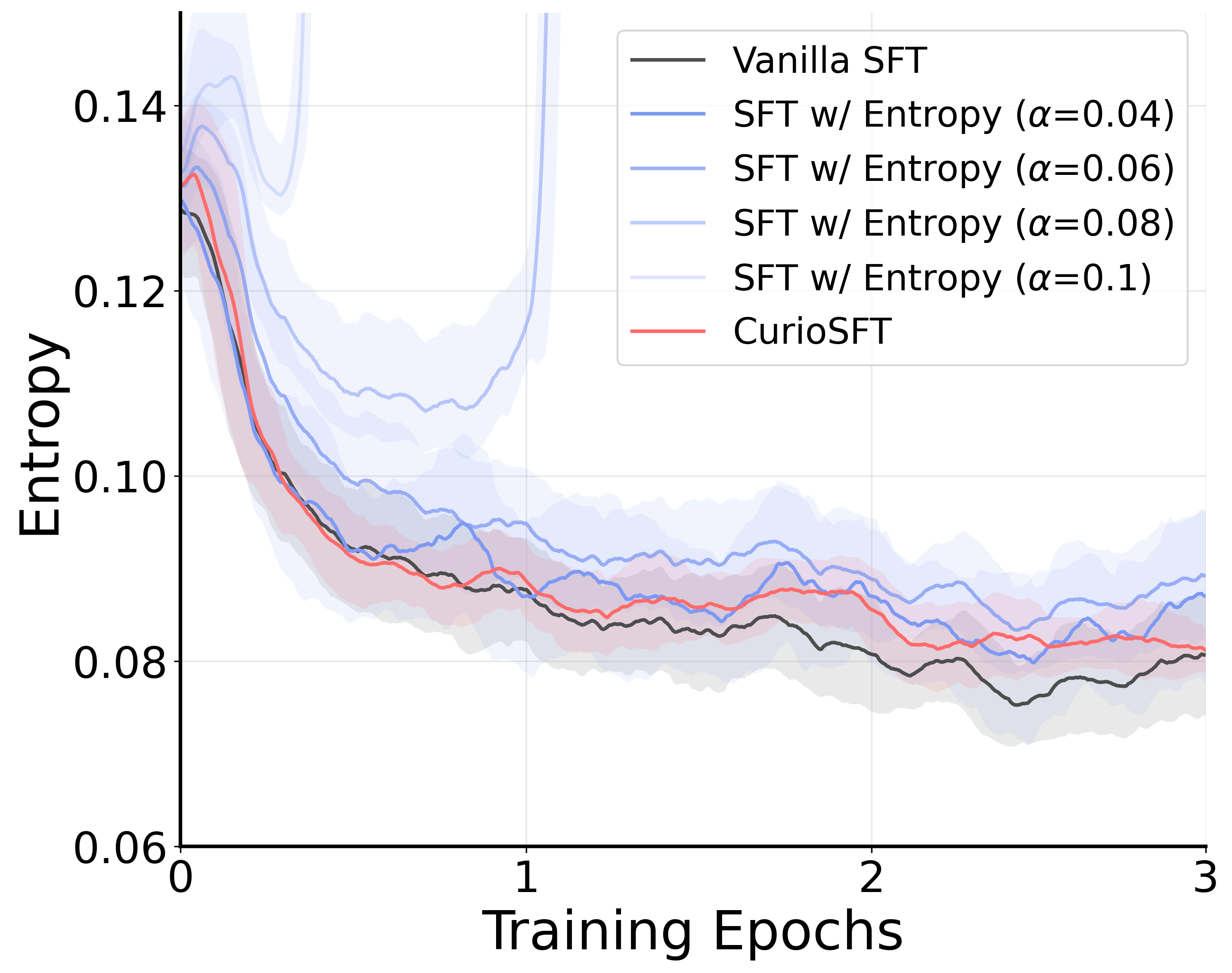
问题定义:论文旨在解决大型推理模型在经过监督微调(SFT)后,过度自信和生成多样性降低的问题。传统的SFT方法虽然能够模仿专家示范,但会缩小后续强化学习(RL)阶段的探索空间。简单地在SFT中加入熵正则化并不能有效解决问题,反而可能导致token分布过于平均,增加熵的同时并未提升模型的探索能力。
核心思路:CurioSFT的核心思路是在SFT阶段保持模型的探索能力,使其在后续的RL阶段能够更好地探索解空间。具体而言,CurioSFT通过自探索蒸馏鼓励模型在其能力范围内进行探索,并通过熵引导的温度选择来平衡探索和知识保留。
技术框架:CurioSFT包含两个主要模块:自探索蒸馏(Self-Exploratory Distillation)和熵引导的温度选择(Entropy-Guided Temperature Selection)。自探索蒸馏通过将模型蒸馏到自身生成的、经过温度缩放的教师模型,鼓励模型进行探索。熵引导的温度选择则根据token的类型(推理token或事实token)自适应地调整蒸馏强度,以平衡探索和知识保留。
关键创新:CurioSFT的关键创新在于其自适应的自蒸馏框架,该框架能够有效地保持模型在SFT阶段的探索能力。与传统的熵正则化方法不同,CurioSFT能够更有针对性地进行探索,避免了token分布的过度平均。此外,熵引导的温度选择机制能够根据token的类型自适应地调整蒸馏强度,进一步提升了模型的性能。
关键设计:自探索蒸馏使用温度缩放的softmax输出作为教师模型的分布,温度参数控制了探索的强度。熵引导的温度选择使用token的熵值作为指标,判断token是推理token还是事实token,并根据token的类型调整蒸馏损失的权重。具体来说,对于熵值较高的推理token,增加蒸馏损失的权重,鼓励模型进行探索;对于熵值较低的事实token,降低蒸馏损失的权重,防止知识遗忘。
🖼️ 关键图片

📊 实验亮点
实验结果表明,CurioSFT在数学推理任务上显著优于传统的SFT方法。在SFT阶段,CurioSFT在同分布任务上提升了2.5个点,在异分布任务上提升了2.9个点。更重要的是,CurioSFT在RL阶段也取得了显著的提升,平均提升了5.0个点,验证了其在SFT阶段保留的探索能力能够有效地转化为RL阶段的收益。
🎯 应用场景
CurioSFT可应用于各种需要大型语言模型进行推理和决策的场景,例如数学问题求解、代码生成、对话系统等。通过提升模型的探索能力,CurioSFT可以帮助模型找到更优的解决方案,并生成更多样化的结果。该方法在教育、科研和工业领域都具有潜在的应用价值。
📄 摘要(原文)
The standard post-training recipe for large reasoning models, supervised fine-tuning followed by reinforcement learning (SFT-then-RL), may limit the benefits of the RL stage: while SFT imitates expert demonstrations, it often causes overconfidence and reduces generation diversity, leaving RL with a narrowed solution space to explore. Adding entropy regularization during SFT is not a cure-all; it tends to flatten token distributions toward uniformity, increasing entropy without improving meaningful exploration capability. In this paper, we propose CurioSFT, an entropy-preserving SFT method designed to enhance exploration capabilities through intrinsic curiosity. It consists of (a) Self-Exploratory Distillation, which distills the model toward a self-generated, temperature-scaled teacher to encourage exploration within its capability; and (b) Entropy-Guided Temperature Selection, which adaptively adjusts distillation strength to mitigate knowledge forgetting by amplifying exploration at reasoning tokens while stabilizing factual tokens. Extensive experiments on mathematical reasoning tasks demonstrate that, in SFT stage, CurioSFT outperforms the vanilla SFT by 2.5 points on in-distribution tasks and 2.9 points on out-of-distribution tasks. We also verify that exploration capabilities preserved during SFT successfully translate into concrete gains in RL stage, yielding an average improvement of 5.0 points.