Hierarchical Adaptive Eviction for KV Cache Management in Multimodal Language Models
作者: Xindian Ma, Yidi Lu, Peng Zhang, Jing Zhang
分类: cs.LG, cs.AI
发布日期: 2026-02-02
备注: 10 oages, 3 figures
💡 一句话要点
提出HAE框架,通过分层自适应淘汰策略优化多模态大语言模型KV缓存管理。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态大语言模型 KV缓存管理 注意力剪枝 动态解码 资源优化
📋 核心要点
- 多模态大语言模型面临Transformer架构带来的二次方内存和计算成本瓶颈,现有KV缓存淘汰策略未能有效处理视觉和文本token间异构的注意力分布。
- HAE框架通过双重注意力剪枝和动态解码淘汰策略,优化视觉和文本token的交互,从而最小化KV缓存使用并降低计算开销。
- 实验表明,HAE在图像理解任务中显著降低了KV缓存内存占用,并在故事生成任务中提高了推理速度,同时保持了输出质量。
📝 摘要(中文)
本文提出了一种名为分层自适应淘汰(HAE)的KV缓存淘汰框架,旨在优化多模态大语言模型(MLLM)中视觉和文本token之间的交互。HAE通过在预填充阶段实施双重注意力剪枝(利用视觉token的稀疏性和注意力方差)以及在解码阶段采用动态解码淘汰策略(灵感来源于操作系统回收站)来实现这一目标。HAE最小化了跨层的KV缓存使用,通过索引广播减少了计算开销,并且在理论上确保了相比贪婪策略更优的信息完整性和更低的误差界限,从而提高了理解和生成任务的效率。实验结果表明,在Phi3.5-Vision-Instruct模型上,HAE在图像理解任务中以极小的精度损失(0.3%的下降)减少了41%的KV-Cache内存,并在保持输出质量的同时,将故事生成推理速度提高了1.5倍。
🔬 方法详解
问题定义:多模态大语言模型(MLLM)由于Transformer架构的特性,其KV缓存大小随序列长度呈平方增长,导致内存和计算成本高昂。现有的KV缓存淘汰策略通常没有区分视觉和文本token,忽略了它们之间注意力分布的差异,导致缓存效率低下或性能下降。因此,如何有效地管理MLLM的KV缓存,在保证性能的同时降低资源消耗,是一个亟待解决的问题。
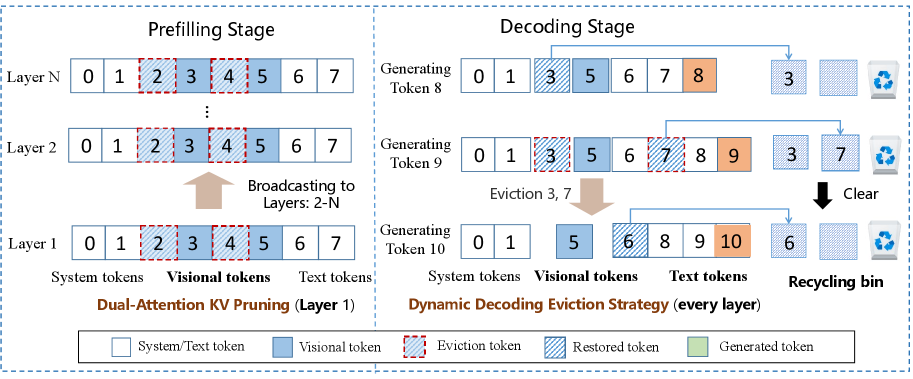
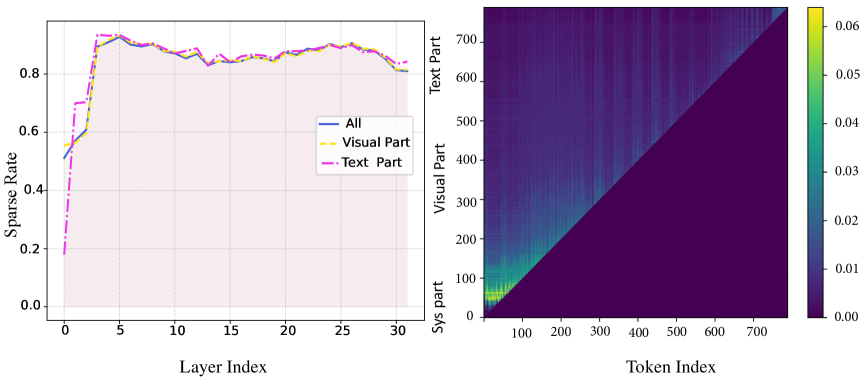
核心思路:HAE的核心思路是根据视觉和文本token的不同特性,采用分层自适应的淘汰策略。具体来说,在预填充阶段,利用视觉token的稀疏性和注意力方差进行剪枝,减少不重要的视觉token的KV缓存。在解码阶段,借鉴操作系统回收站的思想,动态地淘汰不常用的token,并在需要时恢复,从而提高缓存利用率。这种分层自适应的方法能够更精细地管理KV缓存,从而在保证性能的同时降低资源消耗。
技术框架:HAE框架主要包含两个阶段:预填充阶段和解码阶段。在预填充阶段,HAE采用双重注意力剪枝策略,根据视觉token的稀疏性和注意力方差,对不重要的视觉token进行剪枝,减少KV缓存的初始大小。在解码阶段,HAE采用动态解码淘汰策略,维护一个类似回收站的缓存区域,用于存放被淘汰的token。当需要使用这些token时,可以从回收站中恢复,从而避免重复计算。此外,HAE还利用索引广播技术,减少计算开销。
关键创新:HAE的关键创新在于其分层自适应的淘汰策略。与传统的KV缓存淘汰策略相比,HAE能够根据视觉和文本token的不同特性,采用不同的淘汰策略,从而更有效地管理KV缓存。此外,HAE借鉴操作系统回收站的思想,动态地淘汰不常用的token,并在需要时恢复,从而提高了缓存利用率。
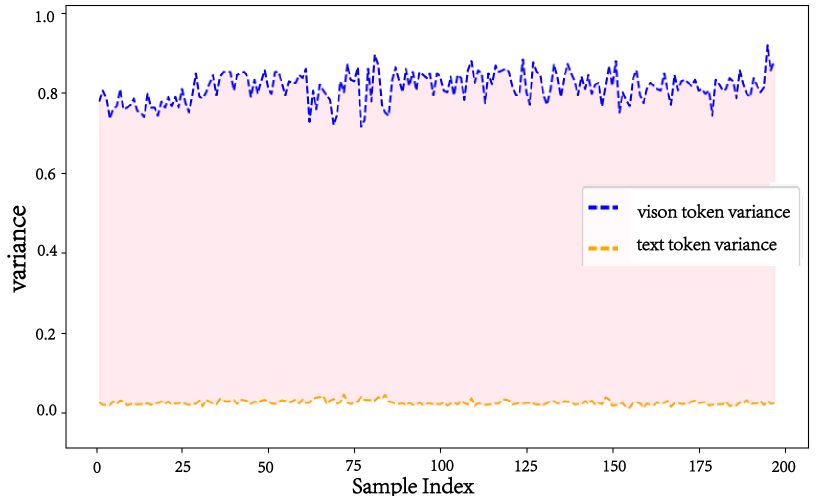
关键设计:在预填充阶段,HAE使用注意力方差作为剪枝的依据,选择注意力方差较低的视觉token进行剪枝。在解码阶段,HAE维护一个固定大小的回收站,用于存放被淘汰的token。淘汰策略基于token的使用频率和重要性,优先淘汰不常用的token。此外,HAE还使用索引广播技术,减少计算开销。具体的参数设置(如回收站大小、剪枝比例等)需要根据具体的模型和任务进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,HAE在Phi3.5-Vision-Instruct模型上,在图像理解任务中以仅0.3%的精度损失,减少了41%的KV-Cache内存占用。在故事生成任务中,HAE在保持输出质量的同时,将推理速度提高了1.5倍。这些结果表明,HAE能够有效地管理MLLM的KV缓存,并在保证性能的同时降低资源消耗。
🎯 应用场景
HAE框架可广泛应用于各种多模态大语言模型,尤其是在资源受限的场景下,如移动设备或边缘计算平台。通过降低KV缓存的内存占用,HAE能够使这些模型在更小的设备上运行,并提高推理速度。此外,HAE还可以应用于需要处理大量视觉信息的应用,如图像描述、视觉问答等,提高这些应用的效率和性能。
📄 摘要(原文)
The integration of visual information into Large Language Models (LLMs) has enabled Multimodal LLMs (MLLMs), but the quadratic memory and computational costs of Transformer architectures remain a bottleneck. Existing KV cache eviction strategies fail to address the heterogeneous attention distributions between visual and text tokens, leading to suboptimal efficiency or degraded performance. In this paper, we propose Hierarchical Adaptive Eviction (HAE), a KV cache eviction framework that optimizes text-visual token interaction in MLLMs by implementing Dual-Attention Pruning during pre-filling (leveraging visual token sparsity and attention variance) and a Dynamic Decoding Eviction Strategy (inspired by OS Recycle Bins) during decoding. HAE minimizes KV cache usage across layers, reduces computational overhead via index broadcasting, and theoretically ensures superior information integrity and lower error bounds compared to greedy strategies, enhancing efficiency in both comprehension and generation tasks. Empirically, HAE reduces KV-Cache memory by 41\% with minimal accuracy loss (0.3\% drop) in image understanding tasks and accelerates story generation inference by 1.5x while maintaining output quality on Phi3.5-Vision-Instruct model.