State Rank Dynamics in Linear Attention LLMs
作者: Ao Sun, Hongtao Zhang, Heng Zhou, Yixuan Ma, Yiran Qin, Tongrui Su, Yan Liu, Zhanyu Ma, Jun Xu, Jiuchong Gao, Jinghua Hao, Renqing He
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
揭示线性注意力LLM状态秩动态特性,提出联合秩-范数剪枝优化KV缓存。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 线性注意力 大语言模型 状态秩动态 模型剪枝 KV缓存优化
📋 核心要点
- 线性注意力LLM将上下文压缩为固定大小的状态矩阵,实现常数时间推理,但其内部状态动态尚不明确。
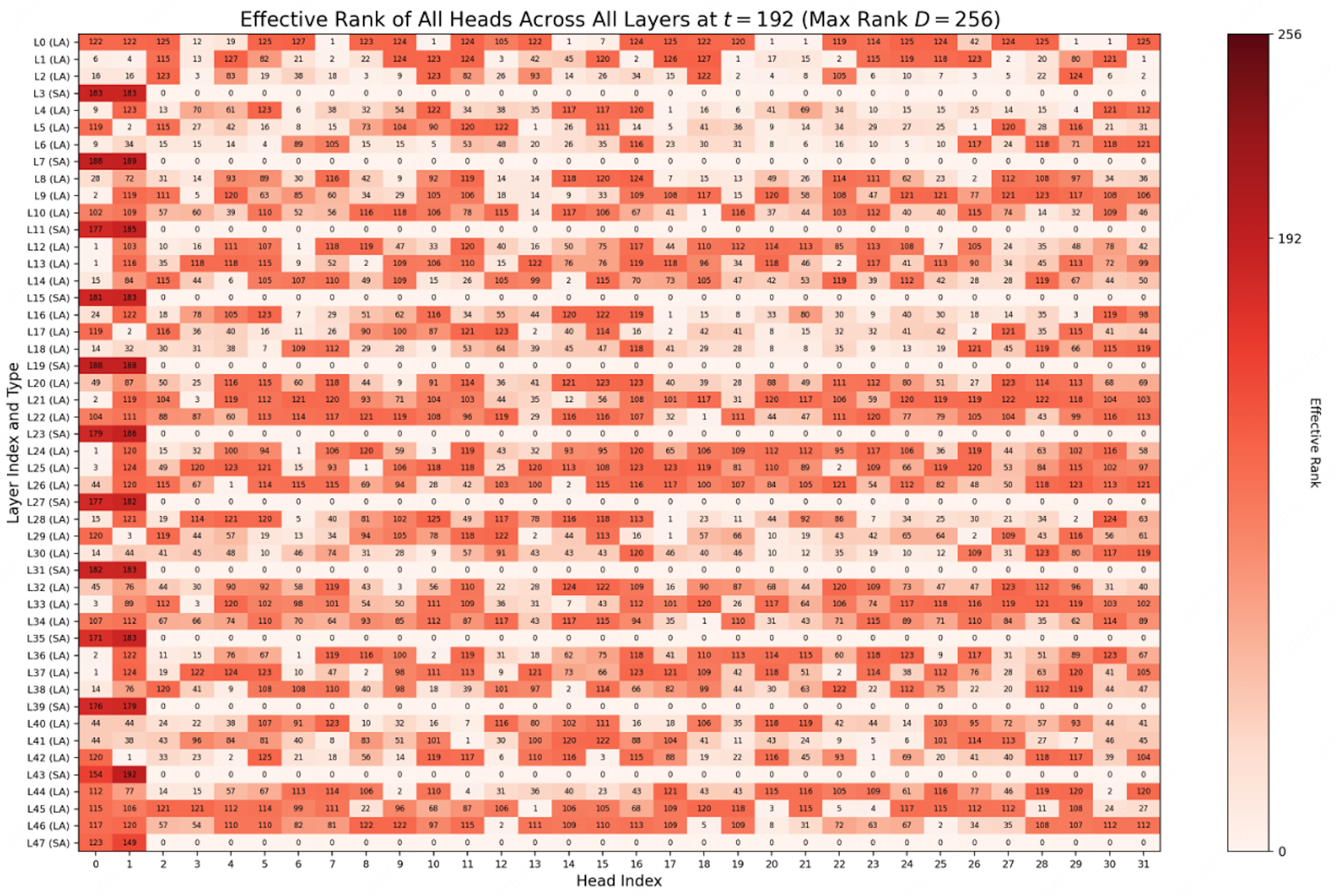
- 论文揭示了线性注意力头中“状态秩分层”现象,即部分头保持低秩,另一部分头秩快速增长,且此特性在预训练中已确定。
- 基于此,论文提出联合秩-范数剪枝策略,在保持模型精度前提下,显著降低KV缓存开销。
📝 摘要(中文)
本文深入研究了当前先进线性注意力大语言模型(LLMs)的运行时状态动态。研究发现了一种称为“状态秩分层”的现象,其特征在于线性注意力头之间存在明显的频谱分叉:一组头的有效秩在零附近振荡,而另一组头的秩则快速增长并收敛到上限。在各种推理上下文中进行的大量实验表明,这些动态特性惊人地一致,表明一个头是低秩还是高秩,是在预训练期间获得的内在结构属性,而不是依赖于输入数据的瞬态状态。此外,诊断探针揭示了一个令人惊讶的功能差异:低秩头对于模型推理是不可或缺的,而高秩头则表现出显著的冗余。利用这一洞察力,我们提出了一种联合秩-范数剪枝的零样本策略,在很大程度上保持模型精度的同时,实现了 KV 缓存开销 38.9% 的降低。
🔬 方法详解
问题定义:线性注意力大语言模型虽然具有高效的推理速度,但其内部状态的动态变化机制尚不清楚。现有方法缺乏对线性注意力头在运行时状态秩的深入理解,无法有效利用这些信息进行模型优化,例如降低 KV 缓存的开销。
核心思路:论文的核心思路是通过分析线性注意力头的状态矩阵的秩,揭示不同注意力头在功能上的差异。通过观察发现,一部分头保持低秩状态,而另一部分头则呈现高秩状态,并且这种状态在预训练后就已确定。基于此,认为高秩头可能存在冗余,可以通过剪枝来降低计算开销。
技术框架:论文主要通过实验分析线性注意力模型的状态矩阵的秩,并基于分析结果提出剪枝策略。整体流程包括:1) 运行线性注意力模型,收集各个注意力头的状态矩阵;2) 计算状态矩阵的秩,观察其动态变化;3) 根据秩的大小,将注意力头分为低秩头和高秩头;4) 设计联合秩-范数剪枝策略,对高秩头进行剪枝;5) 评估剪枝后的模型性能。
关键创新:论文最重要的技术创新点在于发现了线性注意力头中“状态秩分层”的现象,并将其与注意力头的功能联系起来。这种发现为理解线性注意力模型的内部机制提供了新的视角,并为模型优化提供了新的思路。
关键设计:论文提出的联合秩-范数剪枝策略是关键设计之一。该策略同时考虑了注意力头的秩和范数,以更精确地识别冗余的注意力头。具体来说,该策略首先根据秩的大小对注意力头进行排序,然后根据范数的大小对高秩头进行排序,最后选择范数较小的高秩头进行剪枝。这种联合考虑秩和范数的方法可以更有效地保留重要的注意力头,从而在降低计算开销的同时,保持模型性能。
🖼️ 关键图片

📊 实验亮点
实验结果表明,论文提出的联合秩-范数剪枝策略能够在保持模型精度基本不变的情况下,将 KV 缓存开销降低 38.9%。这一结果验证了高秩注意力头的冗余性,并证明了该剪枝策略的有效性。
🎯 应用场景
该研究成果可应用于优化线性注意力大语言模型的推理效率,降低 KV 缓存开销,从而在资源受限的设备上部署更大规模的模型。此外,对状态秩动态的理解有助于设计更高效的注意力机制和模型架构,提升模型性能。
📄 摘要(原文)
Linear Attention Large Language Models (LLMs) offer a compelling recurrent formulation that compresses context into a fixed-size state matrix, enabling constant-time inference. However, the internal dynamics of this compressed state remain largely opaque. In this work, we present a comprehensive study on the runtime state dynamics of state-of-the-art Linear Attention models. We uncover a fundamental phenomenon termed State Rank Stratification, characterized by a distinct spectral bifurcation among linear attention heads: while one group maintains an effective rank oscillating near zero, the other exhibits rapid growth that converges to an upper bound. Extensive experiments across diverse inference contexts reveal that these dynamics remain strikingly consistent, indicating that the identity of a head,whether low-rank or high-rank,is an intrinsic structural property acquired during pre-training, rather than a transient state dependent on the input data. Furthermore, our diagnostic probes reveal a surprising functional divergence: low-rank heads are indispensable for model reasoning, whereas high-rank heads exhibit significant redundancy. Leveraging this insight, we propose Joint Rank-Norm Pruning, a zero-shot strategy that achieves a 38.9\% reduction in KV-cache overhead while largely maintaining model accuracy.