ECHO-2: A Large Scale Distributed Rollout Framework for Cost-efficient Reinforcement Learning
作者: Jie Xiao, Meng Chen, Qingnan Ren, Song Jingwei, Jiaqi Huang, Yangshen Deng, Chris Tong, Wanyi Chen, Suli Wang, Ziqian Bi, Shuo Lu, Yiqun Duan, Lynn Ai, Eric Yang, Bill Shi
分类: cs.LG, cs.DC
发布日期: 2026-02-02
备注: 23 pages, 7 figures
💡 一句话要点
ECHO-2:一种大规模分布式Rollout框架,用于高性价比的强化学习
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 分布式训练 大型语言模型 后训练 Rollout 策略传播 成本优化
📋 核心要点
- 现有强化学习方法在LLM后训练中,难以有效利用分布式推理资源,面临广域协调和策略传播延迟的挑战。
- ECHO-2通过集中式学习与分布式rollout结合,将策略陈旧性作为可控参数,实现rollout生成、传播和训练的重叠。
- 实验表明,ECHO-2在保持RL奖励的同时,显著提高了成本效率,尤其是在广域带宽受限的情况下。
📝 摘要(中文)
强化学习(RL)是大型语言模型(LLM)后训练的关键阶段,涉及rollout生成、奖励评估和集中式学习之间的重复交互。分布式rollout执行提供了利用更具成本效益的推理资源的机会,但也带来了广域协调和策略传播方面的挑战。我们提出了ECHO-2,一个用于后训练的分布式RL框架,具有远程推理工作节点和不可忽略的传播延迟。ECHO-2结合了集中式学习与分布式rollout,并将有界的策略陈旧性视为用户可控的参数,从而使rollout生成、传播和训练能够重叠。我们引入了一个基于重叠的容量模型,该模型将训练时间、传播延迟和rollout吞吐量联系起来,从而产生一个用于维持学习器利用率的实用配置规则。为了缓解传播瓶颈并降低成本,ECHO-2采用了对等辅助的流水线广播和成本感知的异构工作节点激活。在实际广域带宽条件下对4B和8B模型进行GRPO后训练的实验表明,ECHO-2在保持与强基线相当的RL奖励的同时,显著提高了成本效率。
🔬 方法详解
问题定义:论文旨在解决大型语言模型后训练中,如何高效利用分布式计算资源进行强化学习的问题。现有方法在分布式rollout执行时,面临着广域网络环境下的策略传播延迟和资源协调的挑战,导致训练效率低下和成本增加。
核心思路:ECHO-2的核心思路是将集中式学习与分布式rollout相结合,并允许策略存在一定的陈旧性。通过控制策略陈旧性的上界,使得rollout生成、策略传播和模型训练可以并行进行,从而提高整体的训练效率和资源利用率。
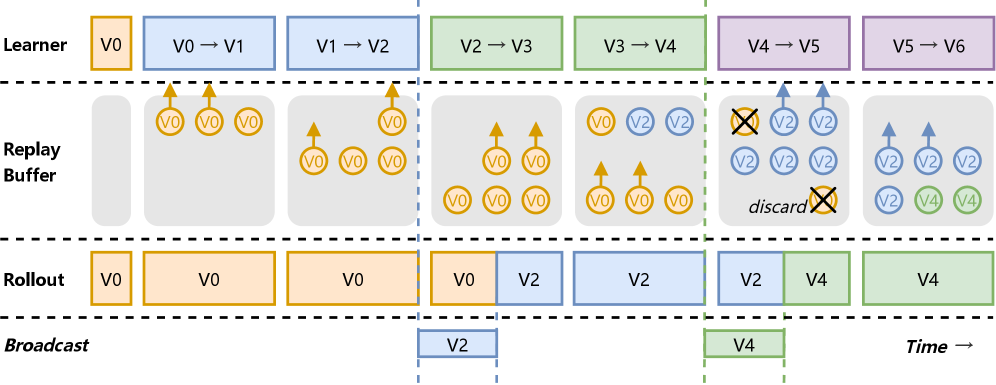
技术框架:ECHO-2的整体框架包括以下几个主要模块:1) 分布式Rollout执行器:负责在远程推理节点上生成rollout数据。2) 集中式学习器:负责接收rollout数据并更新模型参数。3) 策略传播机制:采用对等辅助的流水线广播,将最新的策略分发到各个Rollout执行器。4) 容量模型:用于根据训练时间、传播延迟和rollout吞吐量,动态调整资源分配,保证学习器的充分利用。
关键创新:ECHO-2的关键创新在于:1) 提出了一个基于重叠的容量模型,能够量化训练时间、传播延迟和rollout吞吐量之间的关系,并指导资源配置。2) 采用了对等辅助的流水线广播机制,有效缓解了策略传播的瓶颈。3) 实现了成本感知的异构工作节点激活,能够根据不同节点的成本和性能,动态选择合适的节点参与rollout生成。
关键设计:ECHO-2的关键设计包括:1) 用户可控的策略陈旧性参数,用于平衡rollout数据的质量和训练的并行度。2) 基于成本和性能的异构节点选择策略,例如,可以优先选择成本较低的节点,或者根据节点的计算能力动态调整rollout任务的分配。3) 损失函数的设计需要考虑策略陈旧性的影响,例如,可以采用重要性采样等技术来校正陈旧策略带来的偏差。
🖼️ 关键图片

📊 实验亮点
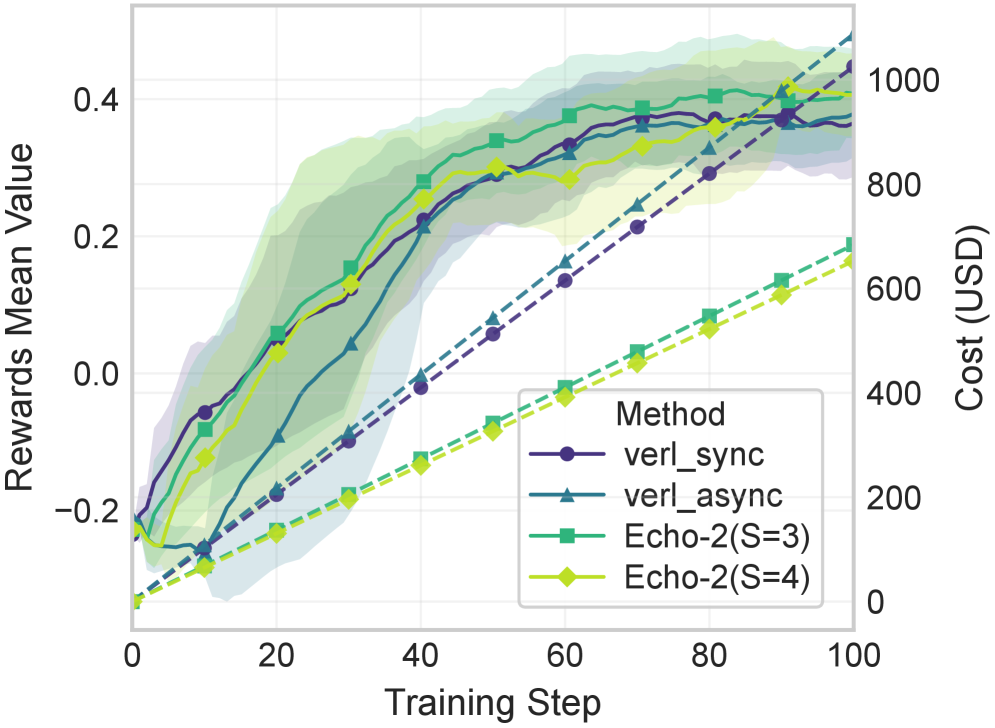
ECHO-2在4B和8B模型的GRPO后训练实验中,在实际广域带宽条件下,显著提高了成本效率,同时保持了与强基线相当的RL奖励。这表明ECHO-2能够有效应对分布式环境下的策略传播延迟和资源协调问题,为大规模强化学习提供了一种可行的解决方案。
🎯 应用场景
ECHO-2框架可广泛应用于大型语言模型的后训练,例如指令微调、奖励模型优化等。通过高效利用分布式计算资源,降低训练成本,加速模型迭代。该框架也适用于其他需要大规模rollout数据的强化学习任务,例如机器人控制、游戏AI等,具有重要的实际应用价值和未来发展潜力。
📄 摘要(原文)
Reinforcement learning (RL) is a critical stage in post-training large language models (LLMs), involving repeated interaction between rollout generation, reward evaluation, and centralized learning. Distributing rollout execution offers opportunities to leverage more cost-efficient inference resources, but introduces challenges in wide-area coordination and policy dissemination. We present ECHO-2, a distributed RL framework for post-training with remote inference workers and non-negligible dissemination latency. ECHO-2 combines centralized learning with distributed rollouts and treats bounded policy staleness as a user-controlled parameter, enabling rollout generation, dissemination, and training to overlap. We introduce an overlap-based capacity model that relates training time, dissemination latency, and rollout throughput, yielding a practical provisioning rule for sustaining learner utilization. To mitigate dissemination bottlenecks and lower cost, ECHO-2 employs peer-assisted pipelined broadcast and cost-aware activation of heterogeneous workers. Experiments on GRPO post-training of 4B and 8B models under real wide-area bandwidth regimes show that ECHO-2 significantly improves cost efficiency while preserving RL reward comparable to strong baselines.