STILL: Selecting Tokens for Intra-Layer Hybrid Attention to Linearize LLMs
作者: Weikang Meng, Liangyu Huo, Yadan Luo, Jiawen Guan, Jingyi Zhang, Yingjian Li, Zheng Zhang
分类: cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出STILL框架以高效线性化大型语言模型
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 线性化模型 混合注意力 自显著性评分 长上下文处理 特征保持
📋 核心要点
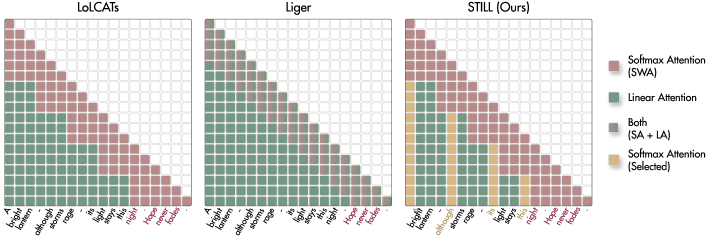
- 现有方法在令牌选择上依赖位置,无法有效捕捉令牌的全局重要性,导致性能下降。
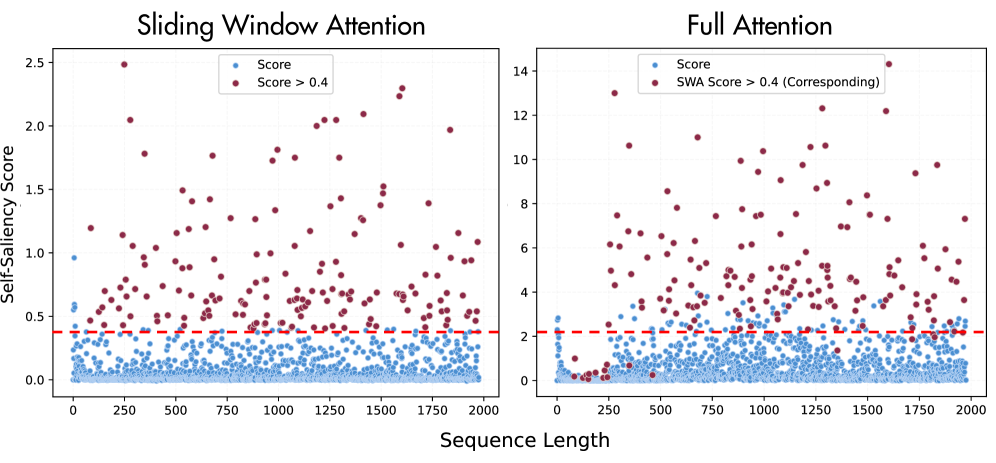
- STILL框架通过自显著性评分实现准确的令牌选择,并设计了规范保持特征图以保留预训练表示。
- 实验结果显示,STILL在常识和推理任务上表现优异,相较于传统方法在长上下文上提升了86.2%。
📝 摘要(中文)
线性化预训练的大型语言模型(LLMs)主要依赖于层内混合注意力机制,以缓解标准softmax注意力的平方复杂度。现有方法基于滑动窗口分区进行令牌路由,导致基于位置的选择,无法捕捉令牌特定的全局重要性。同时,线性注意力还受到可学习特征图造成的分布偏移的影响,扭曲了预训练特征的幅度。为了解决这些问题,我们提出了STILL,一个高效的层内混合线性化框架。STILL引入了具有强局部-全局一致性的自显著性评分,利用滑动窗口计算实现准确的令牌选择,并在保留显著令牌的同时,通过线性注意力总结其余上下文。为了保留预训练表示,我们设计了一个规范保持特征图(NP-Map),将特征方向与幅度解耦,并重新注入预训练的规范。实验表明,STILL在常识和一般推理任务上与原始预训练模型相匹配或超越,并在长上下文基准上相较于先前的线性化注意力方法实现了高达86.2%的相对提升。
🔬 方法详解
问题定义:本论文旨在解决现有线性化大型语言模型(LLMs)方法在令牌选择和特征保持上的不足,尤其是基于位置的选择无法捕捉令牌的全局重要性,导致性能下降。
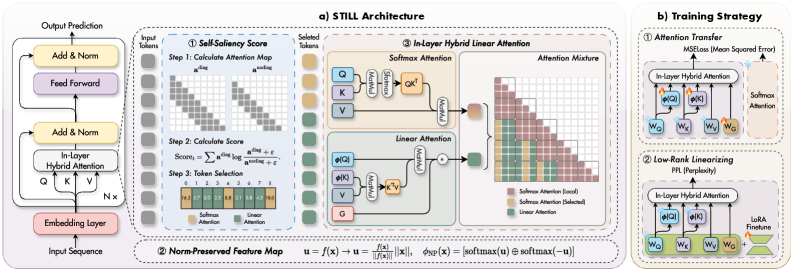
核心思路:提出STILL框架,通过引入自显著性评分实现准确的令牌选择,同时设计规范保持特征图以保留预训练模型的特征幅度,避免分布偏移。
技术框架:STILL框架包括自显著性评分计算模块、规范保持特征图模块和滑动窗口计算模块,整体流程为:首先计算自显著性评分,然后选择显著令牌,最后通过线性注意力总结上下文。
关键创新:STILL的主要创新在于自显著性评分的引入和规范保持特征图的设计,这使得模型能够在保持性能的同时实现高效的线性化,与现有方法相比具有本质区别。
关键设计:在参数设置上,STILL采用了滑动窗口计算以提高效率,损失函数设计上注重保持预训练特征的幅度,网络结构上则通过模块化设计实现灵活性和可扩展性。
🖼️ 关键图片
📊 实验亮点
实验结果表明,STILL在常识和一般推理任务上与原始预训练模型表现相当或更优,并在长上下文基准上相较于先前的线性化注意力方法实现了高达86.2%的相对提升,展示了其在实际应用中的有效性和优势。
🎯 应用场景
STILL框架具有广泛的应用潜力,特别是在需要处理长上下文的自然语言处理任务中,如文本生成、对话系统和信息检索等。其高效的线性化特性能够显著提升模型在实际应用中的响应速度和处理能力,未来可能推动更复杂的语言理解和生成任务的发展。
📄 摘要(原文)
Linearizing pretrained large language models (LLMs) primarily relies on intra-layer hybrid attention mechanisms to alleviate the quadratic complexity of standard softmax attention. Existing methods perform token routing based on sliding-window partitions, resulting in position-based selection and fails to capture token-specific global importance. Meanwhile, linear attention further suffers from distribution shift caused by learnable feature maps that distort pretrained feature magnitudes. Motivated by these limitations, we propose STILL, an intra-layer hybrid linearization framework for efficiently linearizing LLMs. STILL introduces a Self-Saliency Score with strong local-global consistency, enabling accurate token selection using sliding-window computation, and retains salient tokens for sparse softmax attention while summarizing the remaining context via linear attention. To preserve pretrained representations, we design a Norm-Preserved Feature Map (NP-Map) that decouples feature direction from magnitude and reinjects pretrained norms. We further adopt a unified training-inference architecture with chunk-wise parallelization and delayed selection to improve hardware efficiency. Experiments show that STILL matches or surpasses the original pretrained model on commonsense and general reasoning tasks, and achieves up to a 86.2% relative improvement over prior linearized attention methods on long-context benchmarks.