Interpretable Tabular Foundation Models via In-Context Kernel Regression
作者: Ratmir Miftachov, Bruno Charron, Simon Valentin
分类: cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出KernelICL,通过可解释的核回归增强表格数据的In-Context Learning。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 表格数据 预训练模型 上下文学习 核回归 可解释性 KernelICL TALENT基准 权重分析
📋 核心要点
- 现有的表格数据预训练模型架构复杂,缺乏可解释性,难以理解其预测机制。
- KernelICL将上下文学习显式地建模为核回归,通过核函数实现透明的加权平均预测。
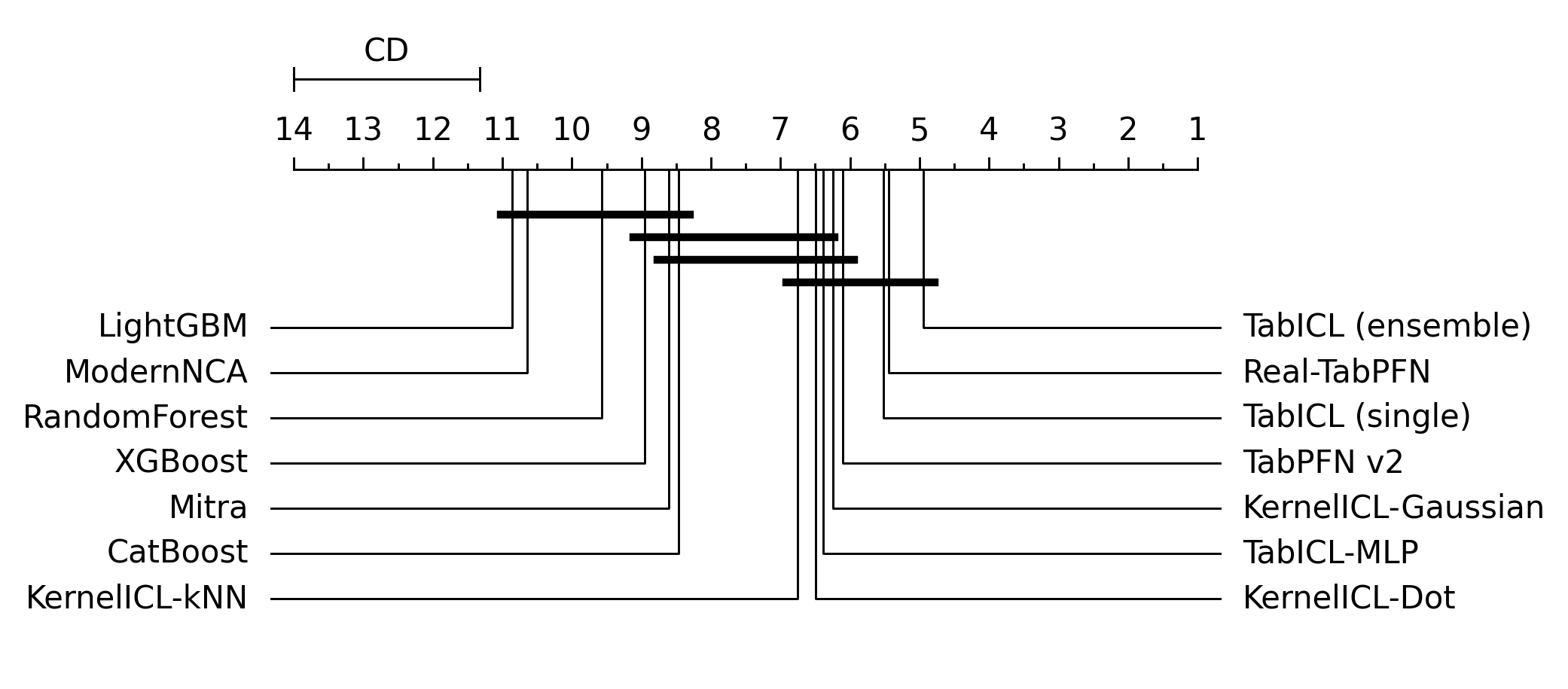
- 实验表明,KernelICL在保持性能的同时,显著提升了模型的可解释性,并在TALENT基准数据集上取得了与现有模型相当的结果。
📝 摘要(中文)
表格数据上的预训练模型,如TabPFN和TabICL,通过上下文学习实现了最先进的性能,但其架构本质上是不透明的。本文提出了KernelICL框架,旨在通过可量化的基于样本的可解释性来增强表格数据的预训练模型。基于上下文学习类似于核回归的洞察,本文通过用核函数(高斯核、点积核、kNN核)替换最终预测层,显式地表达这种机制,从而使每个预测都是训练标签的透明加权平均。本文引入了一个二维分类法,将标准核方法、现代基于邻居的方法和注意力机制统一在一个框架下,并通过训练样本上权重分布的困惑度来量化可检查性。在55个TALENT基准数据集上,KernelICL实现了与现有表格数据预训练模型相当的性能,表明最终层上的显式核约束能够在不牺牲性能的情况下实现可检查的预测。
🔬 方法详解
问题定义:表格数据预训练模型(如TabPFN和TabICL)虽然性能优异,但其内部机制复杂,缺乏可解释性。用户难以理解模型做出特定预测的原因,这限制了其在需要高透明度的场景中的应用。现有方法难以在性能和可解释性之间取得平衡。
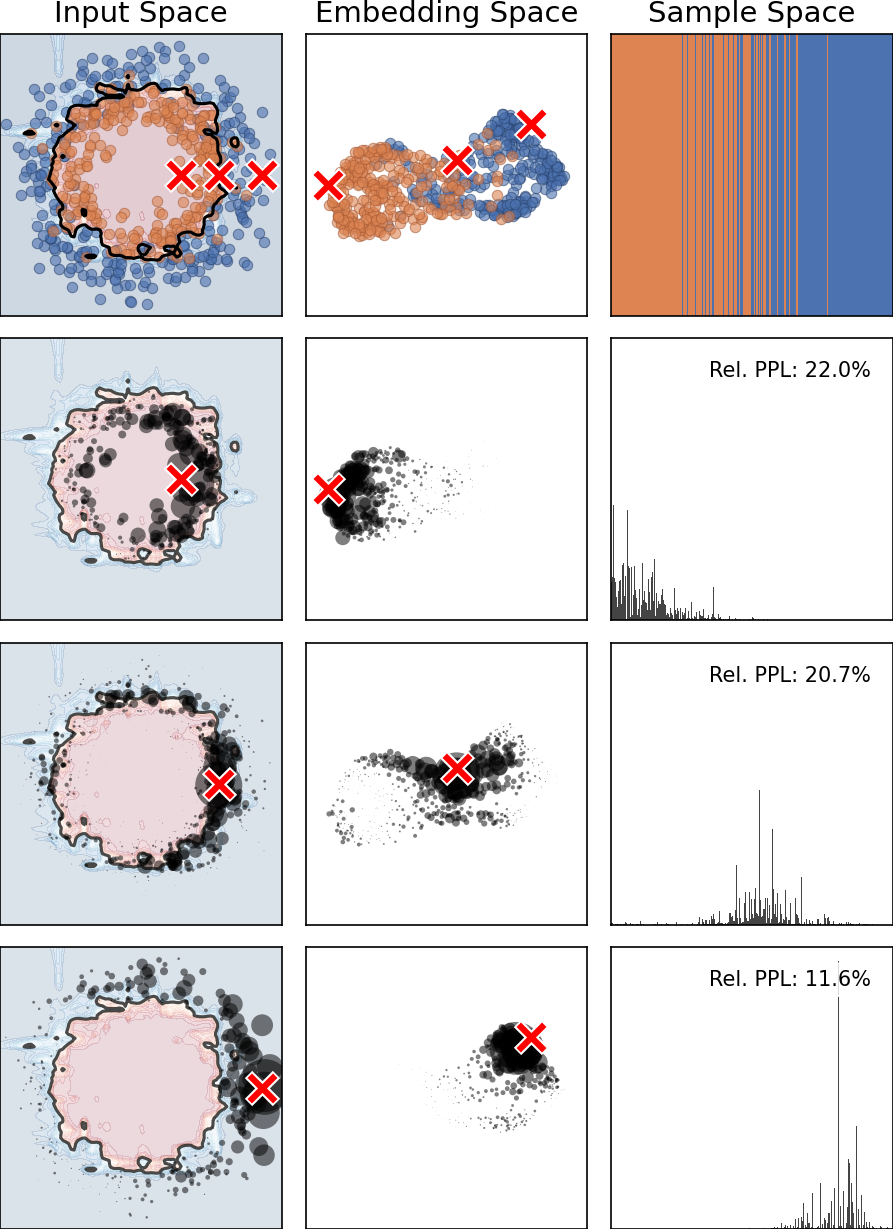
核心思路:论文的核心思想是将上下文学习过程显式地建模为核回归。作者观察到,上下文学习本质上是利用训练样本的信息来预测新样本,这与核回归的思想一致。通过将模型的最终预测层替换为核函数,可以使每个预测都成为训练样本标签的加权平均,从而实现透明的预测过程。
技术框架:KernelICL框架主要包含以下几个部分:1) 特征提取:使用预训练的表格数据模型提取输入数据的特征表示。2) 核函数选择:选择合适的核函数(如高斯核、点积核、kNN核)来计算样本之间的相似度。3) 权重计算:基于核函数计算训练样本的权重,权重反映了训练样本对预测结果的影响程度。4) 加权平均预测:使用计算得到的权重对训练样本的标签进行加权平均,得到最终的预测结果。
关键创新:KernelICL最重要的创新在于将上下文学习与核回归显式地联系起来,并通过核函数实现了可解释的预测。与传统的黑盒模型相比,KernelICL的预测过程更加透明,用户可以清晰地了解每个训练样本对预测结果的贡献。此外,论文还提出了一个二维分类法,统一了标准核方法、现代基于邻居的方法和注意力机制。
关键设计:KernelICL的关键设计包括:1) 核函数的选择:不同的核函数适用于不同的数据分布和任务。论文实验了多种核函数,并分析了它们对性能和可解释性的影响。2) 权重归一化:为了保证权重的合理性,需要对权重进行归一化处理。3) 可解释性度量:论文使用困惑度来量化权重分布的可解释性。困惑度越低,表示权重分布越集中,模型的可解释性越高。
🖼️ 关键图片
📊 实验亮点
KernelICL在55个TALENT基准数据集上取得了与现有表格数据预训练模型相当的性能,证明了在最终层施加显式核约束可以在不牺牲性能的情况下实现可检查的预测。实验结果表明,KernelICL在保持竞争力的同时,显著提升了模型的可解释性,为表格数据预训练模型的可解释性研究提供了一个新的方向。
🎯 应用场景
KernelICL可应用于需要高透明度和可解释性的表格数据分析场景,例如金融风控、医疗诊断、信用评估等。它可以帮助用户理解模型的预测依据,从而增强用户对模型的信任,并促进模型的部署和应用。此外,KernelICL还可以用于模型调试和优化,通过分析权重分布来发现潜在的问题。
📄 摘要(原文)
Tabular foundation models like TabPFN and TabICL achieve state-of-the-art performance through in-context learning, yet their architectures remain fundamentally opaque. We introduce KernelICL, a framework to enhance tabular foundation models with quantifiable sample-based interpretability. Building on the insight that in-context learning is akin to kernel regression, we make this mechanism explicit by replacing the final prediction layer with kernel functions (Gaussian, dot-product, kNN) so that every prediction is a transparent weighted average of training labels. We introduce a two-dimensional taxonomy that formally unifies standard kernel methods, modern neighbor-based approaches, and attention mechanisms under a single framework, and quantify inspectability via the perplexity of the weight distribution over training samples. On 55 TALENT benchmark datasets, KernelICL achieves performance on par with existing tabular foundation models, demonstrating that explicit kernel constraints on the final layer enable inspectable predictions without sacrificing performance.