Revisiting Adaptive Rounding with Vectorized Reparameterization for LLM Quantization
作者: Yuli Zhou, Qingxuan Chen, Luca Benini, Guolei Sun, Yawei Li
分类: cs.LG, cs.CL
发布日期: 2026-02-02
备注: 17 pages, 6 figures, 14 tables
🔗 代码/项目: GITHUB
💡 一句话要点
提出VQRound以提高大语言模型量化效率
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 自适应舍入 量化 大语言模型 参数优化 深度学习
📋 核心要点
- 现有的后训练量化方法在处理亿参数大语言模型时,密集的逐元素舍入矩阵代价过高,限制了其应用。
- 本文提出VQRound,通过将舍入矩阵重新参数化为紧凑的代码本,优化了自适应舍入的效率,特别是在处理重尾权重分布时。
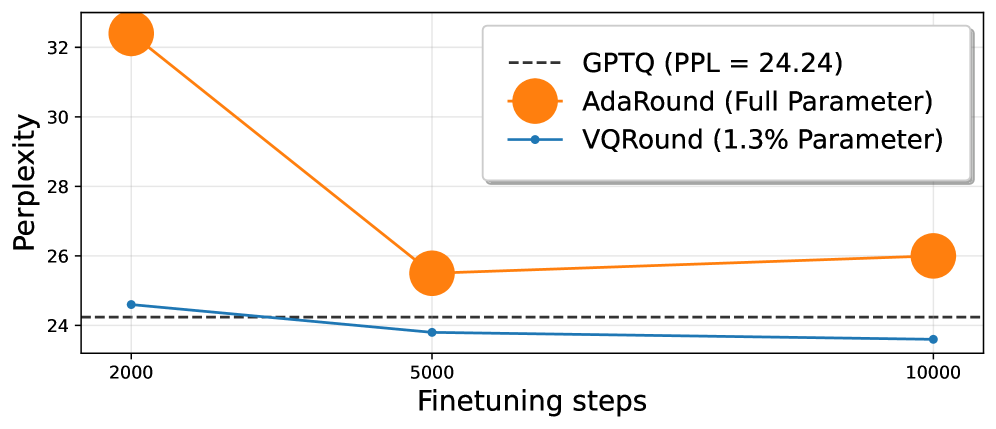
- 实验结果显示,VQRound在相同训练步数下收敛性优于传统方法,并且显著减少了可训练参数的使用,提升了模型的量化性能。
📝 摘要(中文)
自适应舍入作为后训练量化的一种替代方案,通过实现跨元素误差抵消,克服了传统的最近舍入方法的局限性。然而,对于亿参数的大语言模型而言,密集且逐元素的舍入矩阵代价过高。本文从效率角度重新审视自适应舍入,提出了一种名为VQRound的参数高效优化框架,将舍入矩阵重新参数化为紧凑的代码本。与低秩替代方案不同,VQRound在L∞范数下最小化逐元素的最坏情况误差,这对于处理大语言模型中的重尾权重分布至关重要。我们还发现舍入初始化是一个决定性因素,并开发了一种轻量级的端到端微调流程,仅使用128个样本优化所有层的代码本。对OPT、LLaMA、LLaMA2和Qwen3模型的广泛实验表明,VQRound在相同步数下比传统自适应舍入实现了更好的收敛,同时仅使用0.2%的可训练参数。我们的结果表明,自适应舍入可以实现可扩展和快速拟合。
🔬 方法详解
问题定义:本文旨在解决亿参数大语言模型在后训练量化中面临的高成本问题,尤其是密集逐元素舍入矩阵的使用带来的效率瓶颈。
核心思路:VQRound通过将舍入矩阵重新参数化为紧凑的代码本,优化了自适应舍入的效率,特别是在处理重尾权重分布时,采用L∞范数最小化逐元素的最坏情况误差。
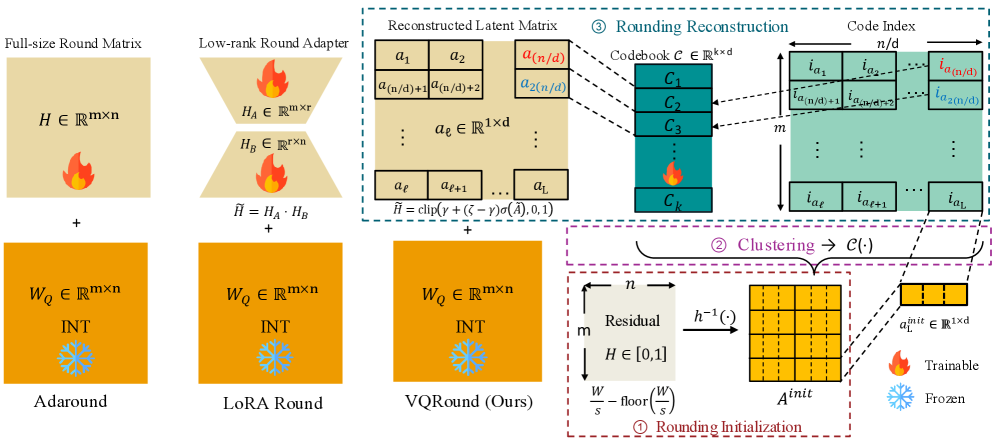
技术框架:VQRound的整体架构包括舍入矩阵的重新参数化、舍入初始化的优化以及轻量级的端到端微调流程,能够在所有层中优化代码本。
关键创新:最重要的技术创新在于将舍入矩阵重新参数化为代码本,并通过优化舍入初始化来提升模型的收敛性,这与传统的自适应舍入方法有本质区别。
关键设计:在设计中,VQRound使用了128个样本进行代码本的优化,采用了L∞范数作为损失函数,显著减少了可训练参数的数量,仅使用0.2%的参数进行训练。
🖼️ 关键图片
📊 实验亮点
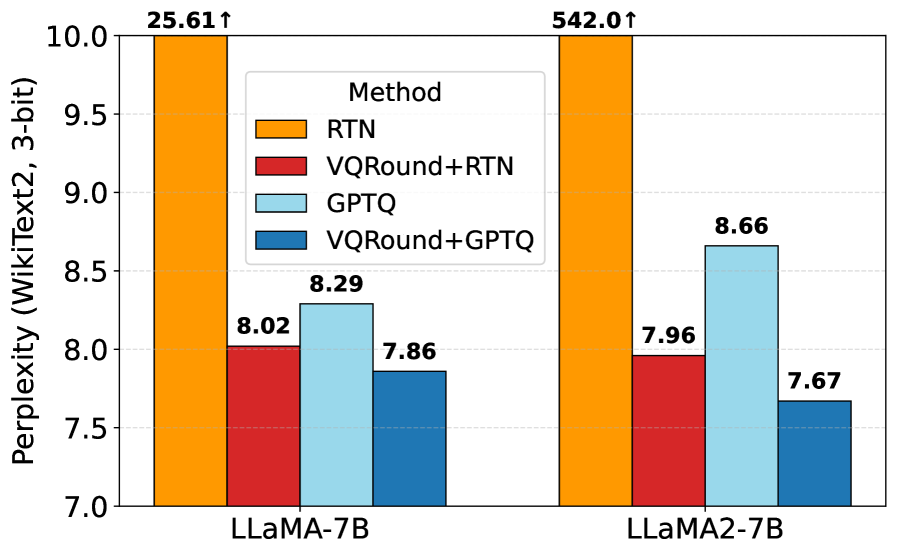
实验结果表明,VQRound在OPT、LLaMA、LLaMA2和Qwen3模型上实现了更好的收敛性,使用的可训练参数仅为0.2%,在相同训练步数下显著优于传统自适应舍入方法,展示了其在量化效率上的显著提升。
🎯 应用场景
该研究的潜在应用领域包括大语言模型的高效量化,尤其是在资源受限的环境中,如移动设备和边缘计算。通过提高量化效率,VQRound能够在保持模型性能的同时,降低计算和存储成本,具有重要的实际价值和未来影响。
📄 摘要(原文)
Adaptive Rounding has emerged as an alternative to round-to-nearest (RTN) for post-training quantization by enabling cross-element error cancellation. Yet, dense and element-wise rounding matrices are prohibitively expensive for billion-parameter large language models (LLMs). We revisit adaptive rounding from an efficiency perspective and propose VQRound, a parameter-efficient optimization framework that reparameterizes the rounding matrix into a compact codebook. Unlike low-rank alternatives, VQRound minimizes the element-wise worst-case error under $L_\infty$ norm, which is critical for handling heavy-tailed weight distributions in LLMs. Beyond reparameterization, we identify rounding initialization as a decisive factor and develop a lightweight end-to-end finetuning pipeline that optimizes codebooks across all layers using only 128 samples. Extensive experiments on OPT, LLaMA, LLaMA2, and Qwen3 models demonstrate that VQRound achieves better convergence than traditional adaptive rounding at the same number of steps while using as little as 0.2% of the trainable parameters. Our results show that adaptive rounding can be made both scalable and fast-fitting. The code is available at https://github.com/zhoustan/VQRound.