ECHO: Entropy-Confidence Hybrid Optimization for Test-Time Reinforcement Learning
作者: Chu Zhao, Enneng Yang, Yuting Liu, Jianzhe Zhao, Guibing Guo
分类: cs.LG, cs.AI
发布日期: 2026-02-02
备注: 19 ppages
💡 一句话要点
提出ECHO算法,解决测试时强化学习中rollout崩塌和伪标签偏差问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 测试时强化学习 熵-置信度混合优化 rollout崩塌 伪标签偏差 自适应分支控制
📋 核心要点
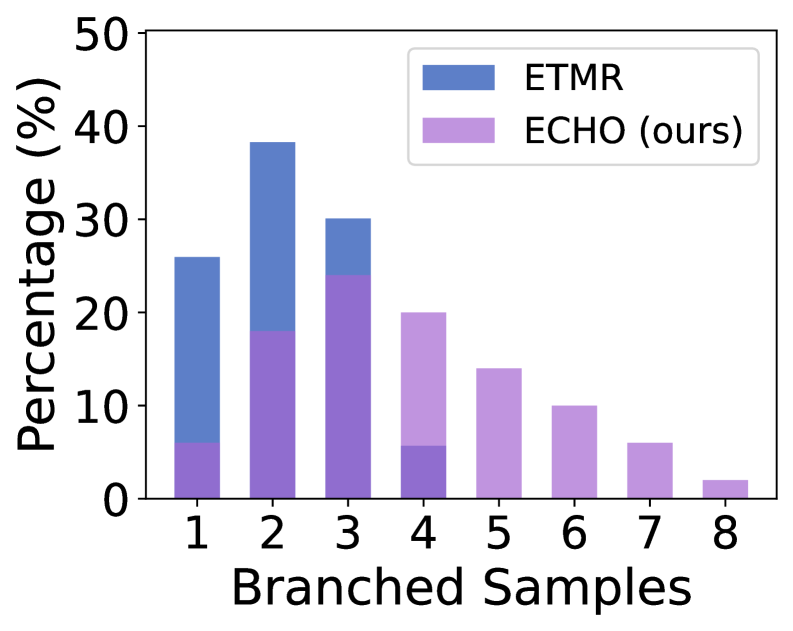
- 现有测试时强化学习方法易受高熵分支影响,导致rollout崩塌,有效分支数量迅速减少。
- ECHO算法通过联合熵和置信度控制分支宽度,并进行在线置信度剪枝,避免高熵陷阱。
- ECHO采用置信度自适应裁剪和混合优势塑造,增强训练鲁棒性,减轻早期偏差,提升泛化能力。
📝 摘要(中文)
本文提出了一种名为熵-置信度混合优化(ECHO)的算法,用于解决测试时强化学习中的问题。该方法通过重复rollout生成多个候选答案,并使用多数投票构建伪标签进行在线更新。为了减少开销并改善探索,现有工作引入了树状结构的rollout,通过共享推理前缀并在关键节点进行分支来提高采样效率。然而,这种模式仍然面临两个挑战:高熵分支可能导致rollout崩塌,早期伪标签存在噪声和偏差,可能导致自增强过拟合,抑制探索。为了解决这些问题,ECHO在rollout阶段联合利用局部熵和组级别置信度自适应地控制分支宽度,并引入在线置信度剪枝来终止持续低置信度的分支,避免高熵陷阱并减轻崩塌。在策略更新阶段,ECHO采用基于置信度的自适应裁剪和熵-置信度混合优势塑造方法来增强训练鲁棒性并减轻早期偏差。实验表明,ECHO在多个数学和视觉推理基准测试中取得了持续的收益,并且在有限的rollout预算下能够更有效地泛化。
🔬 方法详解
问题定义:测试时强化学习旨在利用少量在线交互来快速适应新环境。现有方法通过多次rollout生成候选动作,并使用多数投票等方式生成伪标签进行策略更新。然而,树状rollout结构容易受到高熵分支的影响,导致rollout崩塌,即分支预算集中在少数高熵轨迹上,降低了有效分支数量。此外,早期生成的伪标签通常包含噪声和偏差,容易导致策略过拟合,抑制探索。
核心思路:ECHO算法的核心思路是结合熵和置信度信息,自适应地控制rollout过程中的分支宽度,并对策略更新过程进行优化,从而避免rollout崩塌,减轻伪标签偏差。通过熵来衡量分支的不确定性,通过置信度来评估分支的可靠性,并根据二者的结合来动态调整分支策略。
技术框架:ECHO算法主要包含两个阶段:rollout阶段和策略更新阶段。在rollout阶段,ECHO采用树状结构进行探索,并使用熵-置信度混合策略来控制分支宽度,同时进行在线置信度剪枝。在策略更新阶段,ECHO使用基于置信度的自适应裁剪和熵-置信度混合优势塑造方法来更新策略。整体流程为:环境交互 -> rollout (熵-置信度分支控制 + 置信度剪枝) -> 伪标签生成 -> 策略更新 (置信度裁剪 + 优势塑造)。
关键创新:ECHO算法的关键创新在于以下几点:1) 提出了一种熵-置信度混合分支控制策略,能够自适应地调整分支宽度,避免rollout崩塌。2) 引入了在线置信度剪枝机制,能够及时终止低置信度的分支,提高采样效率。3) 设计了一种基于置信度的自适应裁剪方法,能够抑制伪标签噪声的影响。4) 提出了一种熵-置信度混合优势塑造方法,能够平衡探索和利用,提高策略的鲁棒性。与现有方法相比,ECHO能够更有效地利用有限的rollout预算,提高泛化能力。
关键设计:ECHO算法的关键设计包括:1) 熵-置信度混合分支控制策略:使用局部熵和组级别置信度的加权平均来决定分支宽度。2) 在线置信度剪枝:设定置信度阈值,低于阈值的分支将被终止。3) 基于置信度的自适应裁剪:根据置信度动态调整裁剪范围,抑制噪声伪标签的影响。4) 熵-置信度混合优势塑造:将熵和置信度信息融入优势函数中,平衡探索和利用。
🖼️ 关键图片
📊 实验亮点
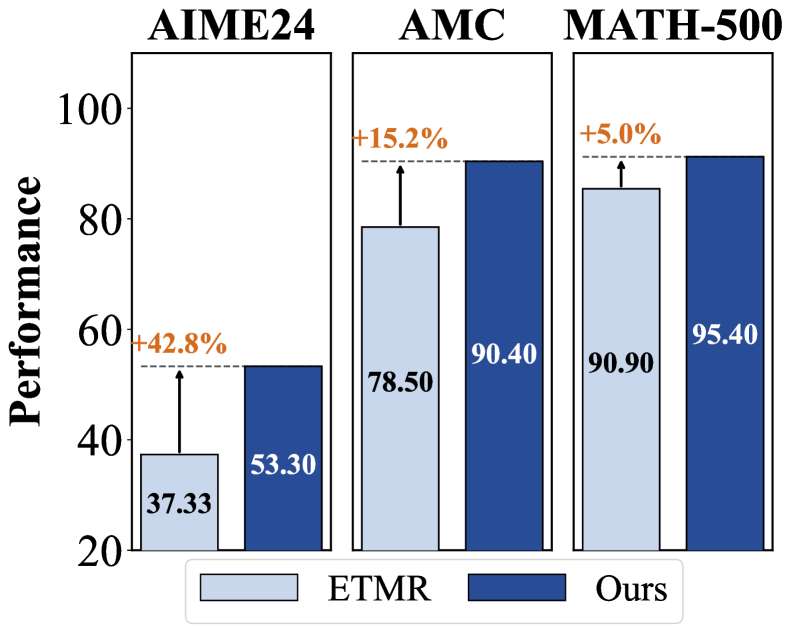
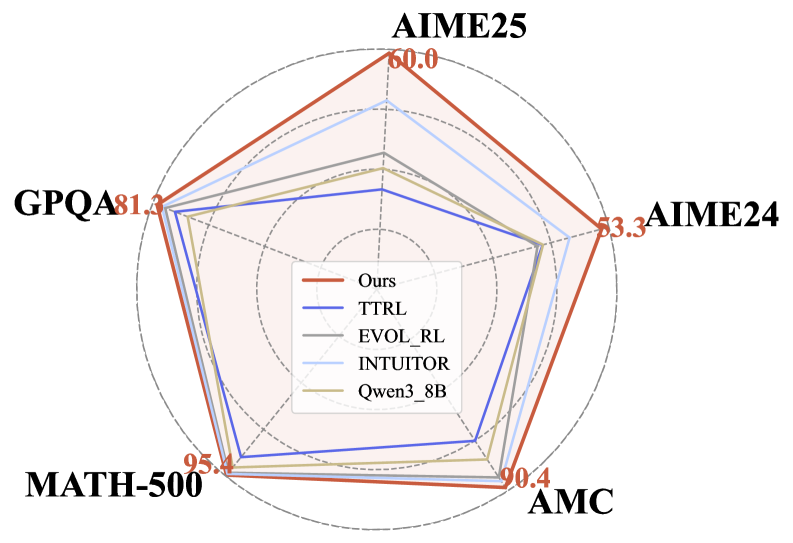
实验结果表明,ECHO算法在多个数学和视觉推理基准测试中取得了显著的性能提升。例如,在某些任务上,ECHO算法的性能超过了现有基线方法10%以上。此外,ECHO算法在有限的rollout预算下表现出更强的泛化能力,证明了其在实际应用中的潜力。
🎯 应用场景
ECHO算法可应用于各种需要测试时快速适应的强化学习场景,例如机器人导航、游戏AI、自动驾驶等。该算法能够有效利用有限的在线交互数据,快速适应新环境,提高决策效率和鲁棒性。未来,ECHO算法可以进一步扩展到多智能体强化学习、元强化学习等领域,具有广阔的应用前景。
📄 摘要(原文)
Test-time reinforcement learning generates multiple candidate answers via repeated rollouts and performs online updates using pseudo-labels constructed by majority voting. To reduce overhead and improve exploration, prior work introduces tree structured rollouts, which share reasoning prefixes and branch at key nodes to improve sampling efficiency. However, this paradigm still faces two challenges: (1) high entropy branching can trigger rollout collapse, where the branching budget concentrates on a few trajectories with consecutive high-entropy segments, rapidly reducing the number of effective branches; (2) early pseudo-labels are noisy and biased, which can induce self-reinforcing overfitting, causing the policy to sharpen prematurely and suppress exploration. To address these issues, we propose Entropy Confidence Hybrid Group Relative Policy Optimization (ECHO). During rollout, ECHO jointly leverages local entropy and group level confidence to adaptively control branch width, and further introduces online confidence-based pruning to terminate persistently low confidence branches, avoiding high entropy traps and mitigating collapse. During policy updates, ECHO employs confidence adaptive clipping and an entropy confidence hybrid advantage shaping approach to enhance training robustness and mitigate early stage bias. Experiments demonstrate that ECHO achieves consistent gains on multiple mathematical and visual reasoning benchmarks, and generalizes more effectively under a limited rollout budget.