DCoPilot: Generative AI-Empowered Policy Adaptation for Dynamic Data Center Operations
作者: Minghao Li, Ruihang Wang, Rui Tan, Yonggang Wen
分类: cs.LG, cs.AI, eess.SY
发布日期: 2026-02-02
💡 一句话要点
DCoPilot:利用生成式AI进行动态数据中心运营的策略自适应
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 数据中心运营 策略自适应 生成式AI 大型语言模型 超网络 深度强化学习 动态环境
📋 核心要点
- 现有数据中心面临工作负载快速变化和SLA变更,手动设计的DRL策略难以适应,导致控制策略滞后和服务中断。
- DCoPilot利用LLM进行奖励函数生成,并使用超网络进行策略权重生成,实现对动态数据中心运营的策略快速自适应。
- 实验表明,DCoPilot在多种控制任务中实现了接近零的约束违反,并在规范变化方面优于其他基线方法。
📝 摘要(中文)
现代数据中心(DC)托管着人工智能(AI)专用设备,以高功率密度运行,且工作负载快速变化,因此需要分钟级的策略调整以确保安全和节能运行。然而,手动设计分段式深度强化学习(DRL)智能体无法跟上不断演变的数据中心频繁的动态变化和服务水平协议(SLA)变更。这种规范到策略的滞后导致缺乏及时有效的控制策略,可能导致服务中断。为了弥合这一差距,我们提出了DCoPilot,一个用于动态数据中心运营中生成控制策略的混合框架。DCoPilot协同了两种不同的生成范式,即执行结构化奖励形式的符号生成的大型语言模型(LLM)和执行策略权重的参数生成的超网络。DCoPilot通过三个协调阶段运行:(i)模拟扩展,在各种可用于仿真的(SimReady)场景中对奖励候选进行压力测试;(ii)元策略蒸馏,其中训练超网络以输出以SLA和场景嵌入为条件的策略权重;(iii)在线自适应,能够响应更新的规范进行零样本策略生成。在涵盖各种数据中心组件的五个控制任务系列中进行评估,DCoPilot实现了接近零的约束违反,并且在规范变化方面优于所有基线。消融研究验证了基于LLM的统一奖励生成在实现稳定的超网络收敛方面的有效性。
🔬 方法详解
问题定义:论文旨在解决动态数据中心运营中,由于工作负载和SLA频繁变化,传统深度强化学习(DRL)方法难以快速适应,导致控制策略滞后和服务中断的问题。现有方法依赖于手动设计分段式DRL智能体,无法有效应对数据中心动态变化的需求。
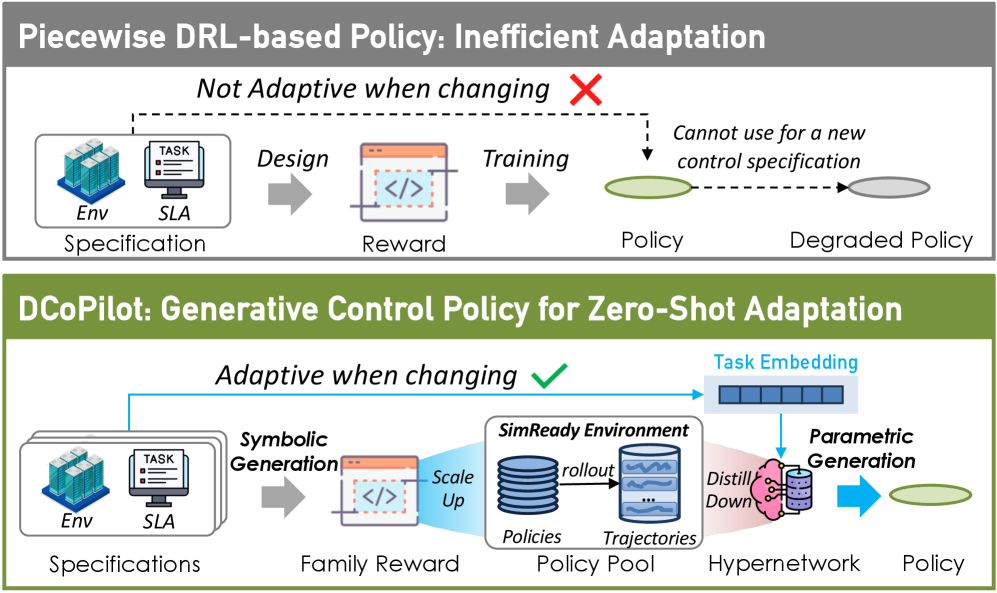
核心思路:论文的核心思路是利用生成式AI,包括大型语言模型(LLM)和超网络,自动生成适应动态环境的控制策略。LLM负责生成结构化的奖励函数,超网络负责生成策略权重。通过这种方式,可以快速响应数据中心的变化,生成有效的控制策略。
技术框架:DCoPilot框架包含三个主要阶段:(1)模拟扩展(Simulation Scale-up):利用多样化的仿真环境对LLM生成的奖励函数进行压力测试,筛选出合适的奖励函数。(2)元策略蒸馏(Meta Policy Distillation):训练超网络,使其能够根据SLA和场景嵌入生成相应的策略权重。超网络学习一个从环境描述到策略参数的映射。(3)在线自适应(Online Adaptation):在实际数据中心环境中,根据新的SLA和环境状态,利用训练好的超网络生成控制策略,实现零样本策略生成。
关键创新:DCoPilot的关键创新在于将LLM和超网络结合起来,实现控制策略的自动生成和快速自适应。LLM负责奖励函数的符号生成,超网络负责策略权重的参数生成。这种混合方法能够有效地应对数据中心动态变化的需求,避免了手动设计策略的局限性。此外,利用仿真环境进行奖励函数的压力测试,可以提高策略的鲁棒性和可靠性。
关键设计:LLM被用于生成结构化的奖励函数,奖励函数的设计需要考虑数据中心的各种约束条件和优化目标。超网络的设计需要能够有效地学习从环境描述到策略参数的映射关系。论文中使用了SLA和场景嵌入作为超网络的输入,以便能够根据不同的SLA和环境状态生成不同的策略。损失函数的设计需要能够保证策略的稳定性和性能。具体的网络结构和参数设置在论文中进行了详细描述,但具体数值未知。
🖼️ 关键图片

📊 实验亮点
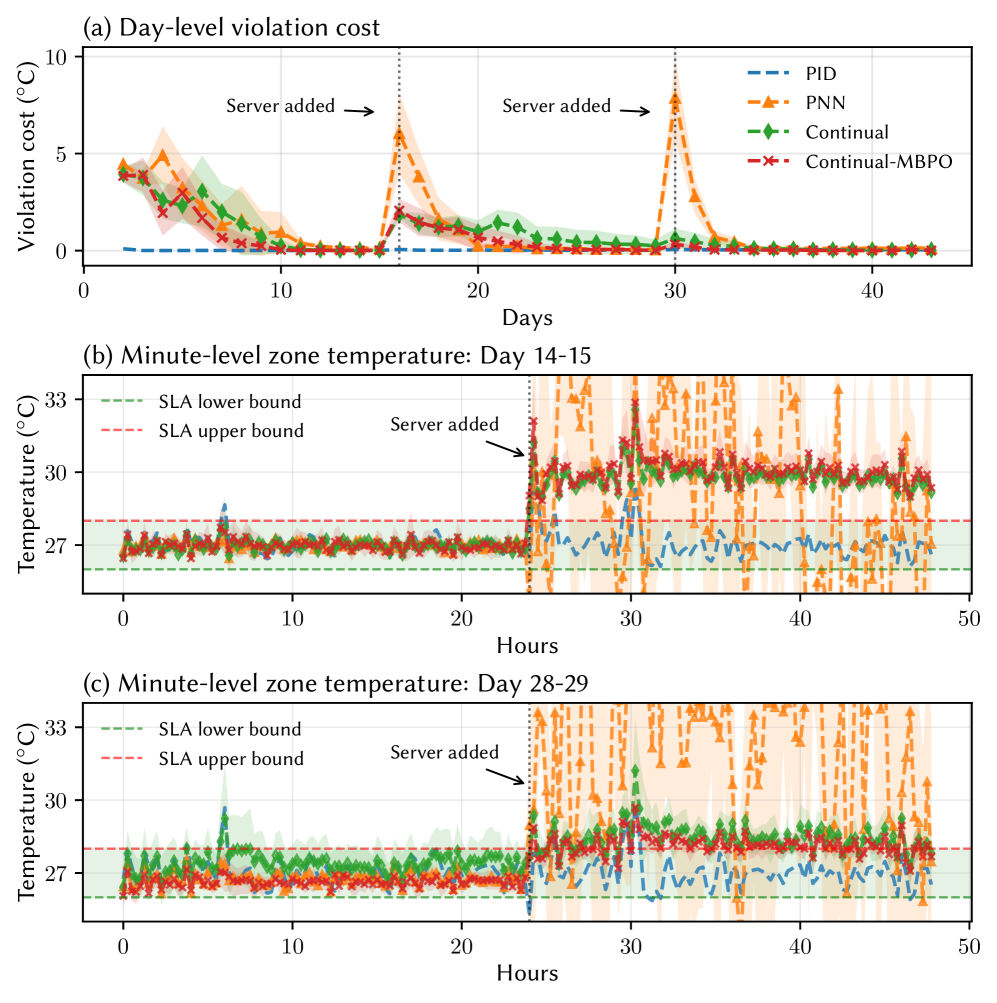
DCoPilot在五个不同的数据中心控制任务中进行了评估,结果表明,该方法能够实现接近零的约束违反,并且在面对规范变化时,性能优于所有基线方法。消融研究验证了LLM生成的统一奖励函数在实现超网络稳定收敛方面的有效性。这些实验结果表明,DCoPilot是一种有效的动态数据中心控制策略自适应方法。
🎯 应用场景
DCoPilot可应用于各种动态数据中心环境,实现自动化、智能化的资源管理和控制。通过快速适应工作负载变化和服务水平协议,提高数据中心的能源效率、稳定性和可靠性,降低运营成本,并减少服务中断的风险。该技术还可扩展到其他需要快速策略自适应的复杂系统,如云计算、边缘计算和智能制造等。
📄 摘要(原文)
Modern data centers (DCs) hosting artificial intelligence (AI)-dedicated devices operate at high power densities with rapidly varying workloads, making minute-level adaptation essential for safe and energy-efficient operation. However, manually designing piecewise deep reinforcement learning (DRL) agents cannot keep pace with frequent dynamics shifts and service-level agreement (SLA) changes of an evolving DC. This specification-to-policy lag causes a lack of timely, effective control policies, which may lead to service outages. To bridge the gap, we present DCoPilot, a hybrid framework for generative control policies in dynamic DC operation. DCoPilot synergizes two distinct generative paradigms, i.e., a large language model (LLM) that performs symbolic generation of structured reward forms, and a hypernetwork that conducts parametric generation of policy weights. DCoPilot operates through three coordinated phases: (i) simulation scale-up, which stress-tests reward candidates across diverse simulation-ready (SimReady) scenes; (ii) meta policy distillation, where a hypernetwork is trained to output policy weights conditioned on SLA and scene embeddings; and (iii) online adaptation, enabling zero-shot policy generation in response to updated specifications. Evaluated across five control task families spanning diverse DC components, DCoPilot achieves near-zero constraint violations and outperforms all baselines across specification variations. Ablation studies validate the effectiveness of LLM-based unified reward generation in enabling stable hypernetwork convergence.