An Empirical Study of World Model Quantization
作者: Zhongqian Fu, Tianyi Zhao, Kai Han, Hang Zhou, Xinghao Chen, Yunhe Wang
分类: cs.LG, cs.CV
发布日期: 2026-02-02
🔗 代码/项目: GITHUB
💡 一句话要点
针对DINO-WM世界模型,系统性研究了后训练量化对视觉规划任务的影响。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 世界模型 后训练量化 模型压缩 视觉规划 DINO-WM
📋 核心要点
- 世界模型计算成本高昂,模型量化是高效部署的关键,但后训练量化(PTQ)对世界模型的影响研究不足。
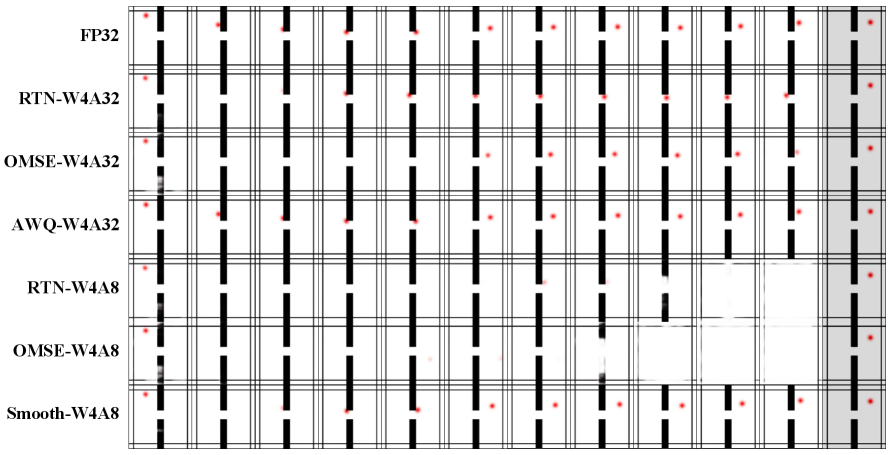
- 本文针对DINO-WM世界模型,系统研究了不同PTQ方法在视觉规划任务中的性能表现。
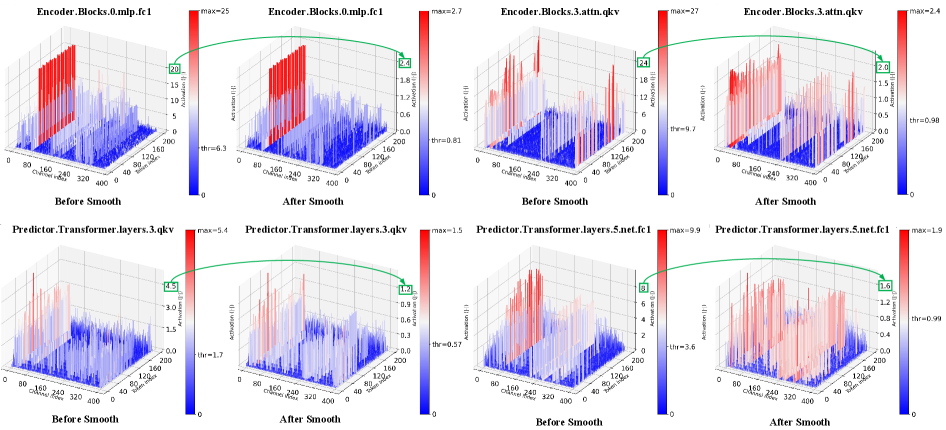
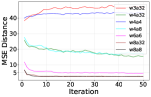
- 实验表明,世界模型量化效应复杂,分组量化可稳定低比特rollout,且编码器和预测器模块的量化敏感性不对称。
📝 摘要(中文)
世界模型学习环境动态的内部表示,使智能体能够在紧凑的潜在空间中模拟和推理未来状态,以进行规划、预测和推理等任务。然而,运行世界模型依赖于巨大的计算成本和内存占用,使得模型量化对于高效部署至关重要。目前,后训练量化(PTQ)对世界模型的影响在很大程度上仍未得到研究。本文以DINO-WM为代表,对世界模型量化进行了系统的实证研究,评估了各种权重和联合权重-激活PTQ方法。我们在不同的视觉规划任务中,针对各种位宽、量化粒度和长达50次迭代的规划范围进行了广泛的实验。结果表明,世界模型中的量化效应超出了标准的精度和位宽权衡:分组权重量化可以稳定低比特rollout,激活量化粒度产生不一致的收益,并且量化敏感性在编码器和预测器模块之间高度不对称。此外,激进的低比特量化会显著降低规划目标与任务成功之间的对齐,导致额外的优化无法补救的失败。这些发现揭示了基于世界模型的规划中由量化引起的独特失效模式,并为在严格的计算约束下部署量化的世界模型提供了实践指导。
🔬 方法详解
问题定义:论文旨在解决世界模型在资源受限设备上部署的问题。现有世界模型计算量大,内存占用高,难以直接部署。后训练量化(PTQ)是一种有效的模型压缩方法,但其对世界模型的影响尚不明确,尤其是在视觉规划任务中,量化可能导致规划目标与实际任务成功之间的偏差。
核心思路:论文的核心思路是通过系统性的实验,研究不同PTQ策略(包括权重和激活量化、不同的量化粒度、不同的位宽等)对世界模型性能的影响,并分析量化引起的失效模式。通过实验结果,为量化世界模型提供实践指导。
技术框架:论文以DINO-WM世界模型为研究对象,评估了多种PTQ方法。DINO-WM通常包含编码器(Encoder)和预测器(Predictor)两个主要模块。编码器将观测数据映射到潜在空间,预测器则在潜在空间中预测未来的状态。论文在不同的视觉规划任务中,评估了不同量化策略对这两个模块的影响。
关键创新:论文的创新点在于:1) 系统性地研究了PTQ对世界模型的影响,填补了该领域的空白;2) 揭示了世界模型中独特的量化效应,如分组权重量化对低比特rollout的稳定作用,以及编码器和预测器模块量化敏感性的不对称性;3) 指出了激进的低比特量化可能导致规划目标与任务成功之间的偏差,并分析了其原因。
关键设计:论文实验中,考虑了不同的量化粒度(例如,逐层量化和分组量化)、不同的位宽(例如,4比特和8比特),以及不同的激活量化策略。此外,论文还分析了量化对规划目标与任务成功之间对齐的影响,并探讨了如何缓解量化带来的负面影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,分组权重量化可以稳定低比特rollout,激活量化粒度收益不一致,且编码器和预测器模块的量化敏感性不对称。激进的低比特量化会显著降低规划目标与任务成功之间的对齐,导致额外的优化无法补救的失败。例如,在某些任务中,4比特量化会导致性能显著下降,即使增加训练迭代次数也无法恢复。
🎯 应用场景
该研究成果可应用于机器人、自动驾驶等领域,在这些领域中,智能体需要根据环境信息进行规划和决策。通过量化世界模型,可以在资源受限的平台上部署复杂的规划算法,提高智能体的自主性和适应性。此外,该研究也为其他基于世界模型的应用提供了量化部署的参考。
📄 摘要(原文)
World models learn an internal representation of environment dynamics, enabling agents to simulate and reason about future states within a compact latent space for tasks such as planning, prediction, and inference. However, running world models rely on hevay computational cost and memory footprint, making model quantization essential for efficient deployment. To date, the effects of post-training quantization (PTQ) on world models remain largely unexamined. In this work, we present a systematic empirical study of world model quantization using DINO-WM as a representative case, evaluating diverse PTQ methods under both weight-only and joint weight-activation settings. We conduct extensive experiments on different visual planning tasks across a wide range of bit-widths, quantization granularities, and planning horizons up to 50 iterations. Our results show that quantization effects in world models extend beyond standard accuracy and bit-width trade-offs: group-wise weight quantization can stabilize low-bit rollouts, activation quantization granularity yields inconsistent benefits, and quantization sensitivity is highly asymmetric between encoder and predictor modules. Moreover, aggressive low-bit quantization significantly degrades the alignment between the planning objective and task success, leading to failures that cannot be remedied by additional optimization. These findings reveal distinct quantization-induced failure modes in world model-based planning and provide practical guidance for deploying quantized world models under strict computational constraints. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/QuantWM.