Probabilistic Performance Guarantees for Multi-Task Reinforcement Learning
作者: Yannik Schnitzer, Mathias Jackermeier, Alessandro Abate, David Parker
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
提出多任务强化学习性能保证方法,为安全关键应用提供高置信度保障。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 多任务强化学习 性能保证 泛化界限 安全关键系统 概率保证
📋 核心要点
- 现有方法在多任务强化学习中缺乏对策略性能的正式保证,限制了其在安全关键领域的应用。
- 该论文提出一种新的泛化界限,结合单任务置信下界和任务级泛化,为新任务提供高置信度的性能保证。
- 实验表明,该方法提供的性能保证在理论上是合理的,且在实际样本量下具有参考价值。
📝 摘要(中文)
本文提出了一种为多任务强化学习策略在训练未见任务上的性能提供高置信度保证的方法。多任务强化学习旨在训练能够执行多个任务的通用策略。尽管近年来取得了显著进展,但现有方法很少提供正式的性能保证,这对于在安全关键环境中部署策略至关重要。本文提出了一种新的泛化界限,它将(i)来自有限次rollout的每个任务的置信下界与(ii)来自有限个采样任务的任务级泛化相结合,从而为来自相同任意和未知分布的新任务产生高置信度保证。在最先进的多任务强化学习方法中,我们证明了这些保证在理论上是合理的,并且在实际样本量下是有信息量的。
🔬 方法详解
问题定义:多任务强化学习旨在训练一个能够处理多个不同任务的通用策略。然而,现有的多任务强化学习方法通常缺乏对策略性能的严格保证,尤其是在面对训练过程中未曾遇到的新任务时。这种不确定性使得这些方法难以应用于安全攸关的场景,例如自动驾驶、机器人控制等,因为在这些场景中,策略的可靠性和性能必须得到充分的验证。现有方法的痛点在于难以量化策略在新任务上的性能,以及缺乏有效的泛化能力评估手段。
核心思路:本文的核心思路是通过构建一个泛化界限,为多任务强化学习策略在未见任务上的性能提供概率性的保证。该界限结合了两个关键要素:一是基于有限次rollout的每个任务的置信下界,用于评估策略在已知任务上的性能;二是任务级别的泛化能力,用于衡量策略从已知任务到未知任务的推广能力。通过将这两个要素结合起来,可以得到一个高置信度的性能保证,确保策略在面对新任务时能够达到预期的性能水平。
技术框架:该方法的技术框架主要包含以下几个阶段: 1. 任务采样:从任务分布中采样有限数量的任务用于训练和评估。 2. 策略训练:使用现有的多任务强化学习算法训练一个通用策略。 3. 单任务性能评估:对于每个采样到的任务,通过有限次rollout估计策略的性能,并计算置信下界。 4. 任务级泛化:基于采样到的任务和对应的性能评估结果,估计策略的任务级泛化能力。 5. 性能保证计算:将单任务性能评估和任务级泛化能力结合起来,计算策略在未见任务上的性能保证。
关键创新:该论文最重要的技术创新点在于提出了一个新的泛化界限,该界限能够为多任务强化学习策略在未见任务上的性能提供概率性的保证。与现有方法相比,该方法不仅能够评估策略在已知任务上的性能,还能够量化策略的泛化能力,从而为策略的可靠性和安全性提供更强的保障。此外,该方法具有通用性,可以应用于各种不同的多任务强化学习算法。
关键设计:论文的关键设计包括: 1. 置信下界的计算方法:采用基于Hoeffding不等式或Bernstein不等式等统计学方法,根据有限次rollout的结果计算每个任务的置信下界。 2. 任务级泛化能力的估计方法:采用基于VC维理论或Rademacher复杂度等理论工具,根据采样到的任务和对应的性能评估结果估计策略的任务级泛化能力。 3. 泛化界限的构建方法:将单任务性能评估和任务级泛化能力结合起来,构建一个高置信度的性能保证。具体的数学形式取决于所采用的置信下界和泛化能力估计方法。
🖼️ 关键图片

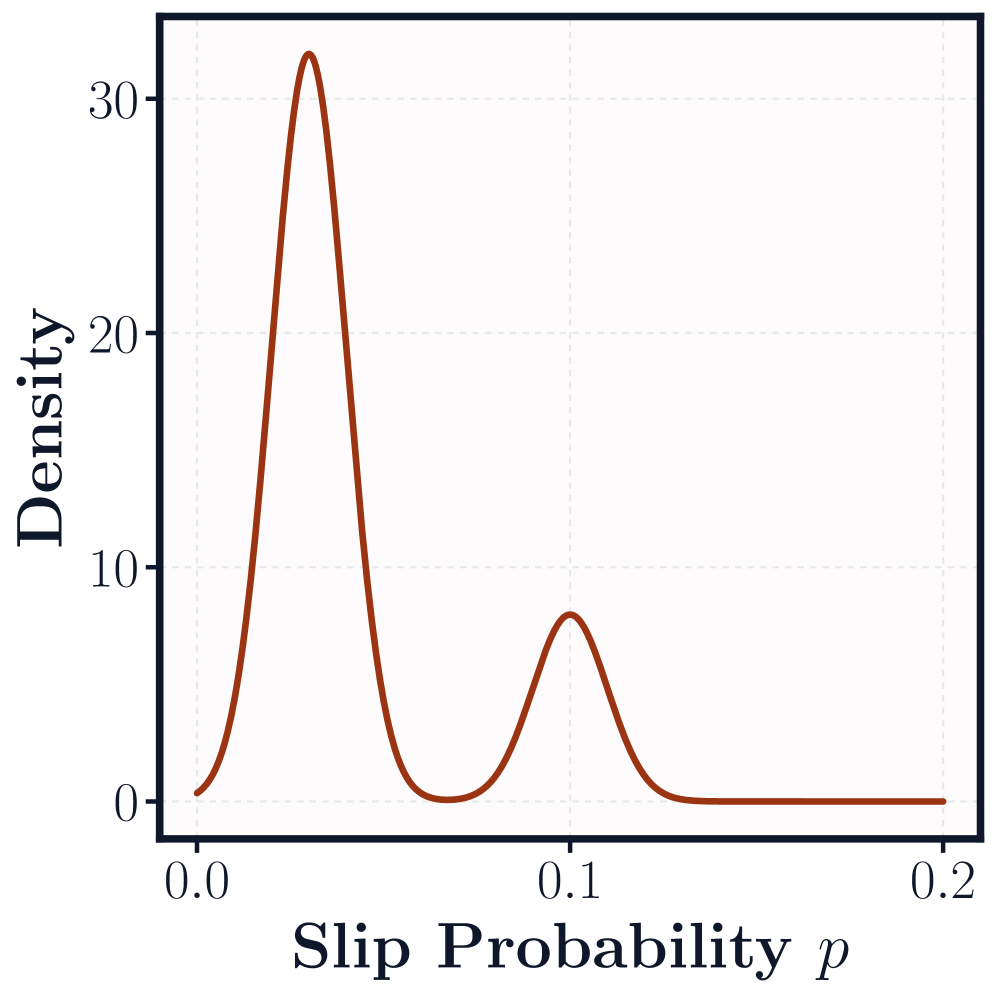
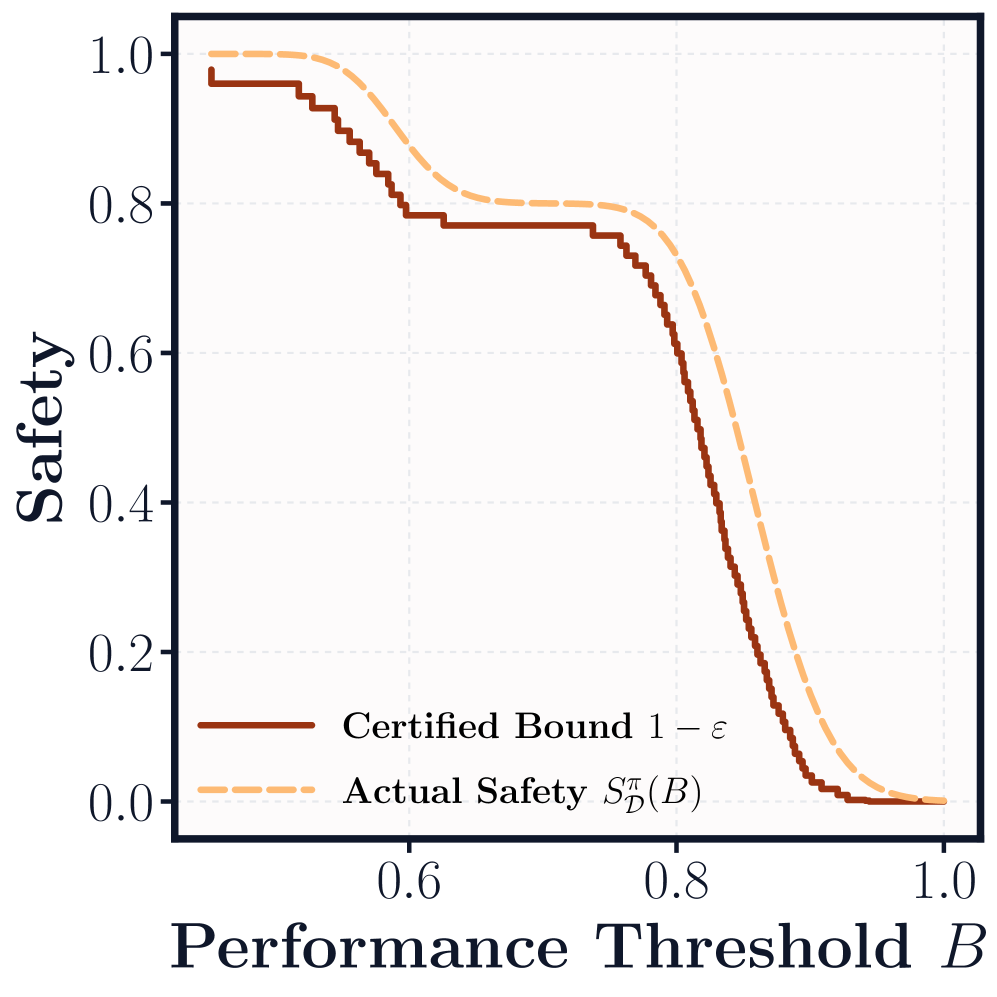
📊 实验亮点
论文通过实验验证了所提出的性能保证方法在实际应用中的有效性。实验结果表明,该方法能够为最先进的多任务强化学习方法提供理论上合理的、且在实际样本量下具有参考价值的性能保证。具体的性能数据和对比基线在论文中进行了详细的展示和分析,证明了该方法相较于现有方法的优势。
🎯 应用场景
该研究成果可广泛应用于安全关键型多任务强化学习场景,如自动驾驶、机器人控制、医疗诊断等。通过提供策略性能的概率性保证,可以提高系统在复杂和不确定环境中的可靠性和安全性,降低潜在风险。未来,该方法有望促进多任务强化学习在实际应用中的部署和推广。
📄 摘要(原文)
Multi-task reinforcement learning trains generalist policies that can execute multiple tasks. While recent years have seen significant progress, existing approaches rarely provide formal performance guarantees, which are indispensable when deploying policies in safety-critical settings. We present an approach for computing high-confidence guarantees on the performance of a multi-task policy on tasks not seen during training. Concretely, we introduce a new generalisation bound that composes (i) per-task lower confidence bounds from finitely many rollouts with (ii) task-level generalisation from finitely many sampled tasks, yielding a high-confidence guarantee for new tasks drawn from the same arbitrary and unknown distribution. Across state-of-the-art multi-task RL methods, we show that the guarantees are theoretically sound and informative at realistic sample sizes.