AICD Bench: A Challenging Benchmark for AI-Generated Code Detection
作者: Daniil Orel, Dilshod Azizov, Indraneil Paul, Yuxia Wang, Iryna Gurevych, Preslav Nakov
分类: cs.LG, cs.SE
发布日期: 2026-02-02
🔗 代码/项目: HUGGINGFACE
💡 一句话要点
提出AICD Bench,一个用于评估AI生成代码检测的全面且具有挑战性的基准。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: AI生成代码检测 基准测试 分布偏移 模型归属 人机分类 对抗性代码 大型语言模型 代码安全
📋 核心要点
- 现有AI生成代码检测数据集和基准测试范围狭窄,无法有效应对实际应用中的复杂场景。
- AICD Bench通过构建大规模、多模型、多语言的代码数据集,并设计更具挑战性的检测任务,来解决现有基准的局限性。
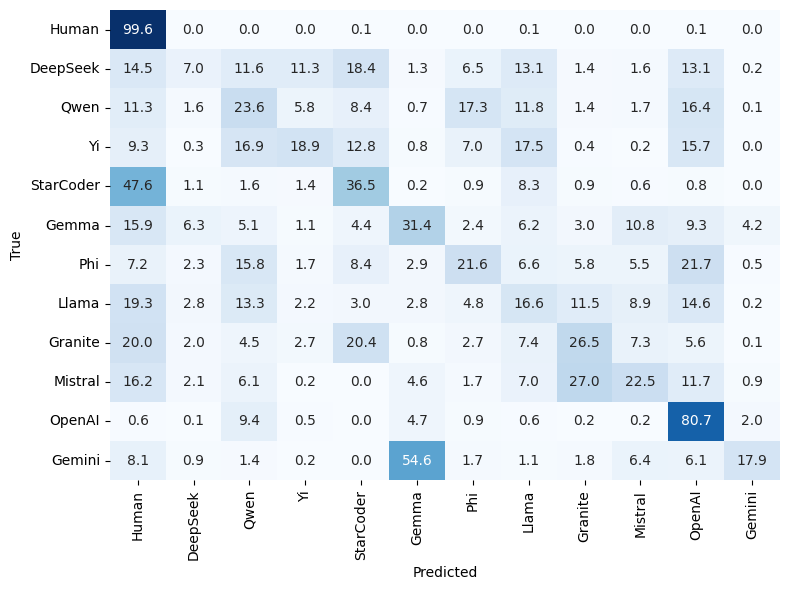
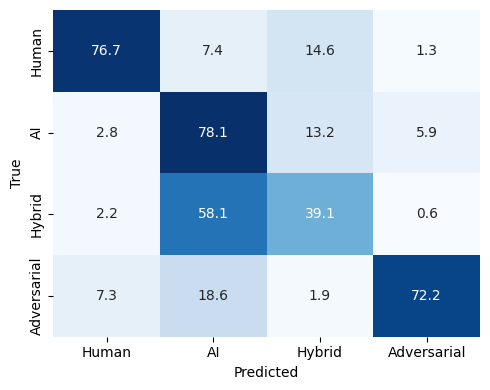
- 实验表明,现有检测器在AICD Bench上表现不佳,尤其是在分布偏移和对抗性代码的情况下,突显了该基准的挑战性。
📝 摘要(中文)
大型语言模型(LLMs)生成功能性源代码的能力日益增强,引发了关于作者身份、责任和安全性的担忧。检测AI生成的代码至关重要,但现有的数据集和基准测试范围狭窄,通常仅限于分布内设置下的二元人机分类。为了弥合这一差距,我们推出了AICD Bench,这是用于AI生成代码检测的最全面的基准。它跨越200万个示例,涵盖11个系列的77个模型和9种编程语言,包括最新的推理模型。除了规模之外,AICD Bench还引入了三个实际的检测任务:(i)语言和领域分布偏移下的鲁棒二元分类,(ii)按架构谱系对生成器进行分组的模型家族归属,以及(iii)跨人类、机器、混合和对抗性代码的细粒度人机分类。对神经和经典检测器的广泛评估表明,性能远低于实际可用性,尤其是在分布偏移以及混合或对抗性代码的情况下。我们发布AICD Bench作为一个统一的、具有挑战性的评估套件,以推动下一代用于AI生成代码检测的鲁棒方法的发展。数据和代码可在https://huggingface.co/AICD-bench获得。
🔬 方法详解
问题定义:论文旨在解决AI生成代码检测领域缺乏全面、具有挑战性的基准的问题。现有方法主要集中在简单的二元分类任务上,并且通常在同分布数据上进行评估,无法很好地泛化到实际应用中可能遇到的分布偏移、混合代码和对抗性代码等复杂情况。
核心思路:论文的核心思路是构建一个大规模、多样化的数据集,并设计更具挑战性的检测任务,以全面评估现有AI生成代码检测方法的鲁棒性和泛化能力。通过引入分布偏移、模型家族归属和细粒度人机分类等任务,迫使研究人员开发更有效的检测方法。
技术框架:AICD Bench包含以下几个主要组成部分:1) 大规模代码数据集:包含200万个示例,涵盖77个模型(来自11个家族)和9种编程语言。2) 三个检测任务:鲁棒二元分类(处理分布偏移)、模型家族归属(识别生成代码的模型家族)和细粒度人机分类(区分人类、机器、混合和对抗性代码)。3) 评估指标:用于评估不同检测方法在各个任务上的性能。
关键创新:AICD Bench的关键创新在于其全面性和挑战性。它不仅规模庞大,而且涵盖了多种模型、语言和代码类型,并引入了更具挑战性的检测任务,例如分布偏移下的鲁棒性评估和对抗性代码的检测。这使得AICD Bench能够更真实地反映实际应用中可能遇到的情况,并推动AI生成代码检测领域的研究进展。
关键设计:数据集的构建过程中,作者精心选择了不同的模型家族和编程语言,以确保数据集的多样性。在设计检测任务时,作者考虑了实际应用中可能遇到的各种情况,例如分布偏移、混合代码和对抗性代码。此外,作者还提供了统一的评估脚本,方便研究人员进行实验和比较。
🖼️ 关键图片
📊 实验亮点
实验结果表明,现有神经和经典检测器在AICD Bench上的性能远低于实际可用水平,尤其是在分布偏移和混合/对抗性代码的情况下。例如,在鲁棒二元分类任务中,检测器的性能显著下降,表明现有方法对分布偏移的鲁棒性不足。这些结果突显了AICD Bench的挑战性,并为未来的研究指明了方向。
🎯 应用场景
该研究成果可应用于软件安全、知识产权保护、教育诚信等领域。通过提高AI生成代码的检测能力,可以有效防止恶意代码的传播、保护代码作者的权益,并维护学术诚信。未来,该基准可以促进更鲁棒、更可靠的AI生成代码检测技术的发展。
📄 摘要(原文)
Large language models (LLMs) are increasingly capable of generating functional source code, raising concerns about authorship, accountability, and security. While detecting AI-generated code is critical, existing datasets and benchmarks are narrow, typically limited to binary human-machine classification under in-distribution settings. To bridge this gap, we introduce $\emph{AICD Bench}$, the most comprehensive benchmark for AI-generated code detection. It spans $\emph{2M examples}$, $\emph{77 models}$ across $\emph{11 families}$, and $\emph{9 programming languages}$, including recent reasoning models. Beyond scale, AICD Bench introduces three realistic detection tasks: ($\emph{i}$)~$\emph{Robust Binary Classification}$ under distribution shifts in language and domain, ($\emph{ii}$)~$\emph{Model Family Attribution}$, grouping generators by architectural lineage, and ($\emph{iii}$)~$\emph{Fine-Grained Human-Machine Classification}$ across human, machine, hybrid, and adversarial code. Extensive evaluation on neural and classical detectors shows that performance remains far below practical usability, particularly under distribution shift and for hybrid or adversarial code. We release AICD Bench as a $\emph{unified, challenging evaluation suite}$ to drive the next generation of robust approaches for AI-generated code detection. The data and the code are available at https://huggingface.co/AICD-bench}.