FiLoRA: Focus-and-Ignore LoRA for Controllable Feature Reliance
作者: Hyunsuk Chung, Caren Han, Yerin Choi, Seungyeon Ji, Jinwoo Kim, Eun-Jung Holden, Kyungreem Han
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
FiLoRA:通过指令控制LoRA调节多模态模型内部特征依赖
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 特征依赖 指令控制 LoRA 鲁棒性
📋 核心要点
- 多模态模型依赖特定特征组进行预测,但对其依赖程度的控制尚不明确,现有方法缺乏在不改变任务语义下调节依赖性的能力。
- FiLoRA通过指令控制LoRA模块,实现对内部特征依赖的显式控制,自然语言指令作为计算级别的控制信号,而非任务重定义。
- 实验表明,FiLoRA能选择性地放大或抑制特征组,提高模型在虚假特征干预下的鲁棒性,提供了一种调节依赖性的机制。
📝 摘要(中文)
多模态基础模型集成了跨模态的异构信号,但我们对其预测如何依赖于特定的内部特征组,以及这种依赖是否可以被有意识地控制,仍然知之甚少。现有的关于捷径和虚假行为的研究主要依赖于事后分析或特征移除,对于是否可以在不改变任务语义的情况下调节依赖性,提供的见解有限。我们引入了FiLoRA(Focus-and-Ignore LoRA),这是一种指令条件下的、参数高效的适配框架,可以在保持预测目标不变的情况下,显式地控制内部特征依赖。FiLoRA将适配分解为特征组对齐的LoRA模块,并应用指令条件门控,允许自然语言指令作为计算级别的控制信号,而不是任务的重新定义。在文本-图像和音频-视觉基准测试中,我们表明指令条件门控可以诱导内部计算中一致且因果的转变,选择性地放大或抑制核心和虚假的特征组,而无需修改标签空间或训练目标。进一步的分析表明,FiLoRA在虚假特征干预下产生了改进的鲁棒性,揭示了一种超越相关性驱动学习的、调节依赖性的原则性机制。
🔬 方法详解
问题定义:多模态模型在进行预测时,往往会依赖于某些特定的特征组。然而,我们对于模型如何依赖这些特征组,以及是否能够人为地控制这种依赖关系,仍然缺乏深入的理解。现有的方法,例如事后分析或特征移除,虽然能够揭示模型对某些特征的依赖,但无法在不改变任务语义的前提下,灵活地调节这种依赖关系。这限制了我们对模型行为的控制,并可能导致模型在面对虚假相关性时表现不佳。
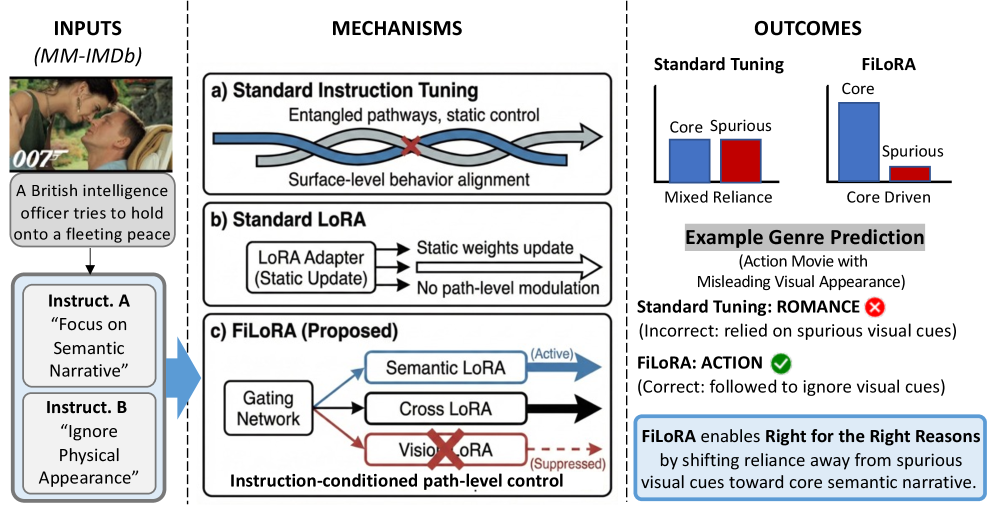
核心思路:FiLoRA的核心思路是利用指令条件下的LoRA模块,实现对模型内部特征依赖的显式控制。具体来说,FiLoRA将模型的适配过程分解为多个特征组对齐的LoRA模块,每个模块负责调整模型对特定特征组的依赖程度。通过自然语言指令,可以控制这些LoRA模块的激活程度,从而实现对特征依赖的精细化调节。这种方法允许我们以一种计算级别的方式来控制模型的行为,而无需改变任务的标签空间或训练目标。
技术框架:FiLoRA的整体框架包括以下几个主要模块:1) 特征组对齐的LoRA模块:针对不同的特征组,分别构建LoRA模块,用于调整模型对这些特征组的依赖程度。2) 指令编码器:将自然语言指令编码成向量表示,作为控制信号。3) 指令条件门控:利用指令编码向量,控制LoRA模块的激活程度,从而实现对特征依赖的调节。4) 多模态模型:作为FiLoRA的底层模型,负责接收输入数据,并根据调整后的特征依赖进行预测。整个流程是,输入数据和指令首先进入多模态模型和指令编码器,指令编码器的输出控制LoRA模块的门控,LoRA模块调整多模态模型的参数,最终模型输出预测结果。
关键创新:FiLoRA最重要的创新点在于其指令条件门控机制。该机制允许我们使用自然语言指令来控制模型对不同特征组的依赖程度,从而实现对模型行为的精细化调节。与现有的方法相比,FiLoRA无需改变任务的标签空间或训练目标,即可实现对特征依赖的控制,这使得FiLoRA更加灵活和通用。此外,FiLoRA的参数效率也很高,因为它只调整LoRA模块的参数,而无需修改整个模型的参数。
关键设计:FiLoRA的关键设计包括:1) 特征组的划分方式:如何将模型的内部特征划分为不同的特征组,直接影响到FiLoRA的控制效果。论文中可能使用了某种特定的特征划分方法,例如基于注意力机制或梯度信息的划分。2) 指令编码器的选择:指令编码器的性能直接影响到指令的表达能力和控制效果。论文中可能使用了某种预训练的语言模型作为指令编码器。3) 门控函数的选择:门控函数决定了指令编码向量如何控制LoRA模块的激活程度。论文中可能使用了某种sigmoid函数或softmax函数作为门控函数。4) LoRA模块的参数设置:LoRA模块的秩(rank)和缩放因子(scaling factor)等参数,会影响到LoRA模块的调整能力和稳定性。论文中可能对这些参数进行了仔细的调整。
🖼️ 关键图片
📊 实验亮点
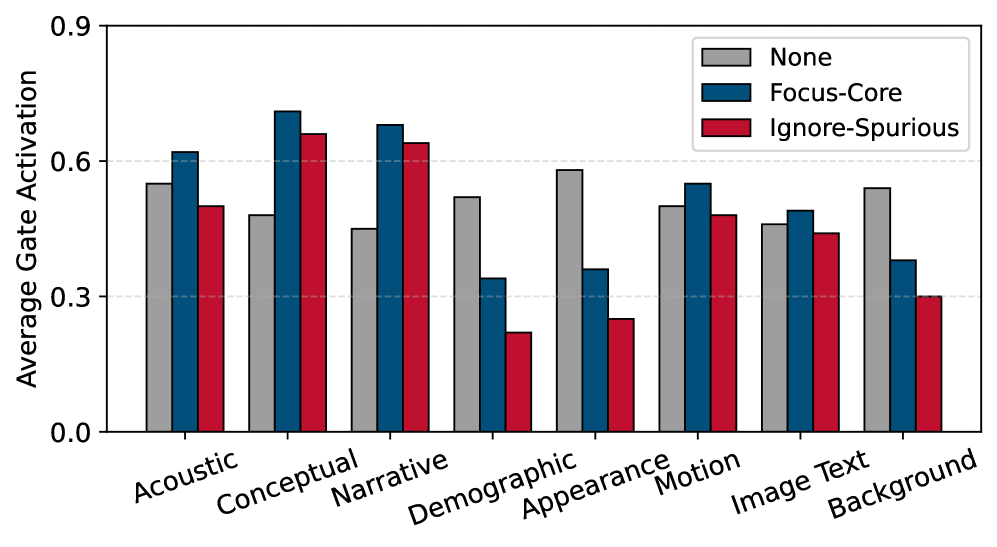
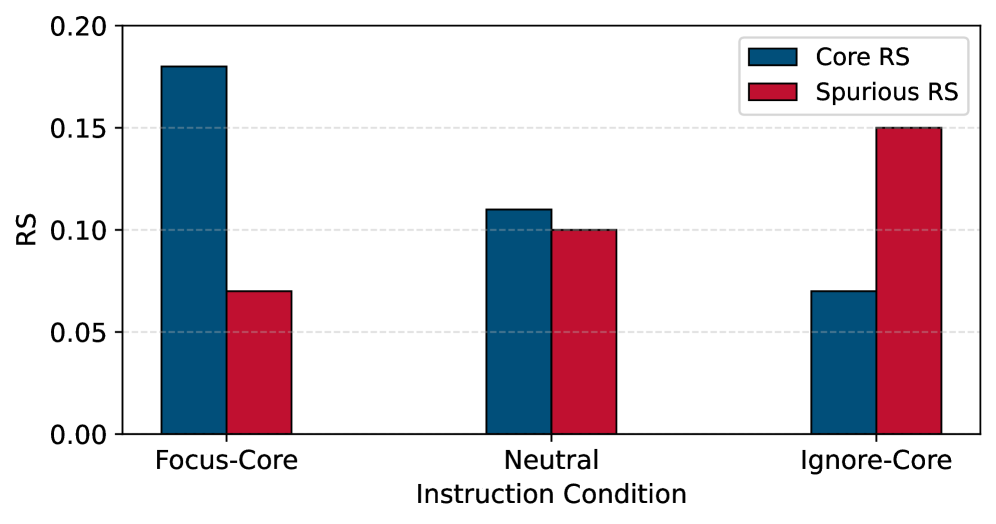
实验结果表明,FiLoRA能够在文本-图像和音频-视觉基准测试中,通过指令条件门控,一致且因果地改变内部计算,选择性地放大或抑制核心和虚假的特征组,而无需修改标签空间或训练目标。在虚假特征干预下,FiLoRA表现出更强的鲁棒性,验证了其调节依赖性的有效性。具体的性能提升数据需要在论文中查找。
🎯 应用场景
FiLoRA具有广泛的应用前景,例如:1) 提高多模态模型在噪声环境下的鲁棒性,通过抑制虚假特征的依赖,减少噪声的干扰。2) 实现对模型行为的个性化定制,根据用户的指令,调整模型对不同特征的依赖程度。3) 增强模型的可解释性,通过分析指令与特征依赖之间的关系,理解模型是如何进行预测的。未来,FiLoRA有望成为一种通用的多模态模型控制框架,应用于各种实际场景。
📄 摘要(原文)
Multimodal foundation models integrate heterogeneous signals across modalities, yet it remains poorly understood how their predictions depend on specific internal feature groups and whether such reliance can be deliberately controlled. Existing studies of shortcut and spurious behavior largely rely on post hoc analyses or feature removal, offering limited insight into whether reliance can be modulated without altering task semantics. We introduce FiLoRA (Focus-and-Ignore LoRA), an instruction-conditioned, parameter-efficient adaptation framework that enables explicit control over internal feature reliance while keeping the predictive objective fixed. FiLoRA decomposes adaptation into feature group-aligned LoRA modules and applies instruction-conditioned gating, allowing natural language instructions to act as computation-level control signals rather than task redefinitions. Across text--image and audio--visual benchmarks, we show that instruction-conditioned gating induces consistent and causal shifts in internal computation, selectively amplifying or suppressing core and spurious feature groups without modifying the label space or training objective. Further analyses demonstrate that FiLoRA yields improved robustness under spurious feature interventions, revealing a principled mechanism to regulate reliance beyond correlation-driven learning.