FORLER: Federated Offline Reinforcement Learning with Q-Ensemble and Actor Rectification
作者: Nan Qiao, Sheng Yue
分类: cs.LG, cs.AI
发布日期: 2026-02-02
备注: accetped by IEEE International Conference on Communications (ICC 2026)
💡 一句话要点
提出FORLER,解决低质量异构数据下的联邦离线强化学习策略污染问题
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: 联邦学习 离线强化学习 策略优化 Q-ensemble Actor修正
📋 核心要点
- 离线联邦强化学习在低质量异构数据下易受策略污染影响,导致模型性能下降。
- FORLER通过服务器端的Q-ensemble聚合和设备端的actor修正来解决策略污染问题。
- 实验结果表明,FORLER在不同数据质量和异构性下均优于现有基线方法。
📝 摘要(中文)
在物联网系统中,联邦学习通过并行策略训练且无需共享原始数据,推动了在线强化学习的发展。然而,与真实环境在线交互可能存在风险和成本,因此离线联邦强化学习(FRL)应运而生,它允许本地设备从固定的数据集学习。尽管前景广阔,但离线FRL可能在低质量、异构数据下失效。离线强化学习容易陷入局部最优,而在FRL中,一个设备次优的策略会降低聚合模型的性能,即策略污染。我们提出了FORLER,它结合了服务器端的Q-ensemble聚合和设备端的actor修正。服务器端稳健地合并设备Q函数,以抑制策略污染,并将大量计算转移到资源受限的硬件之外,同时不损害隐私。在本地,actor修正通过对高Q值的动作进行零阶搜索,并结合定制的正则化器来丰富策略梯度,从而引导策略向这些动作靠拢。一种$δ$-周期性策略进一步减少了本地计算。我们在理论上提供了安全策略改进的性能保证。大量的实验表明,在不同的数据质量和异构性下,FORLER始终优于强大的基线。
🔬 方法详解
问题定义:论文旨在解决离线联邦强化学习(FRL)中,由于各个设备上的数据质量和分布存在差异,导致训练出的策略容易受到“策略污染”的问题。具体来说,当某些设备上的数据质量较差,或者训练出的策略是次优的,这些策略会被聚合到全局模型中,从而降低全局模型的性能。现有的FRL方法难以有效地处理这种策略污染问题,导致模型无法收敛到最优策略。
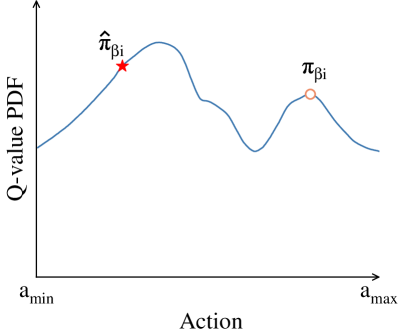
核心思路:FORLER的核心思路是结合服务器端的Q-ensemble聚合和设备端的actor修正,以减轻策略污染的影响。服务器端的Q-ensemble聚合通过对各个设备上传的Q函数进行集成,从而得到一个更鲁棒的Q函数估计,降低了单个设备上的次优策略对全局模型的影响。设备端的actor修正则通过零阶搜索和正则化,引导本地策略向高Q值的动作靠拢,从而提高本地策略的质量。
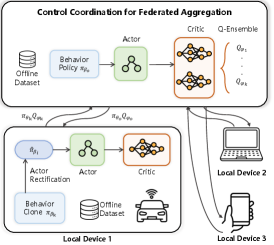
技术框架:FORLER的整体框架包含以下几个主要模块: 1. 本地训练:每个设备使用本地数据集进行离线强化学习训练,得到本地的Q函数和策略。 2. Actor修正:在本地训练的基础上,使用零阶搜索和正则化对actor进行修正,提高本地策略的质量。 3. Q函数上传:每个设备将训练好的Q函数上传到服务器。 4. Q-ensemble聚合:服务器对接收到的Q函数进行聚合,得到全局的Q函数。 5. 策略更新:服务器将全局Q函数广播给各个设备,设备使用全局Q函数更新本地策略。
关键创新:FORLER的关键创新在于以下两点: 1. Q-ensemble聚合:通过对各个设备上传的Q函数进行集成,降低了单个设备上的次优策略对全局模型的影响,提高了模型的鲁棒性。 2. Actor修正:通过零阶搜索和正则化,引导本地策略向高Q值的动作靠拢,提高了本地策略的质量。
关键设计: 1. Q-ensemble聚合:服务器使用加权平均的方式对各个设备上传的Q函数进行聚合,权重可以根据设备上的数据质量或者训练效果进行调整。 2. Actor修正:设备使用零阶搜索来寻找高Q值的动作,并使用正则化项来引导策略向这些动作靠拢。正则化项的形式为KL散度,用于限制策略的改变幅度。 3. δ-周期性策略:为了减少本地计算量,设备不是每次都进行actor修正,而是每隔δ个周期才进行一次。
🖼️ 关键图片
📊 实验亮点
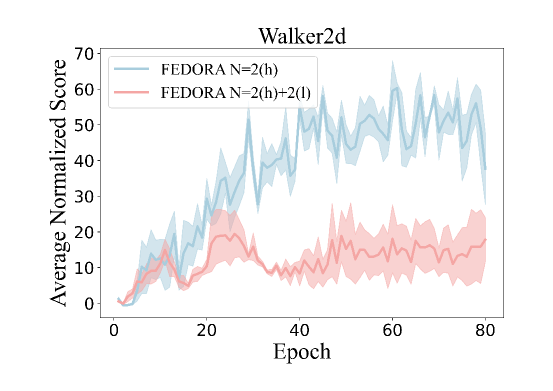
实验结果表明,FORLER在不同的数据质量和异构性下均优于现有的基线方法。例如,在数据质量较差的情况下,FORLER的性能比最好的基线方法提高了10%以上。此外,FORLER还能够有效地处理异构数据,即使各个设备上的数据分布存在较大差异,FORLER仍然能够收敛到较好的策略。
🎯 应用场景
FORLER可应用于各种物联网场景,例如智能交通、智能家居、工业自动化等。在这些场景中,设备需要在本地进行策略学习,同时需要保护用户隐私。FORLER通过联邦学习的方式,实现了在不共享原始数据的情况下进行策略学习,从而保护了用户隐私。此外,FORLER还能够有效地处理低质量和异构数据,提高了模型的鲁棒性。
📄 摘要(原文)
In Internet-of-Things systems, federated learning has advanced online reinforcement learning (RL) by enabling parallel policy training without sharing raw data. However, interacting with real environments online can be risky and costly, motivating offline federated RL (FRL), where local devices learn from fixed datasets. Despite its promise, offline FRL may break down under low-quality, heterogeneous data. Offline RL tends to get stuck in local optima, and in FRL, one device's suboptimal policy can degrade the aggregated model, i.e., policy pollution. We present FORLER, combining Q-ensemble aggregation on the server with actor rectification on devices. The server robustly merges device Q-functions to curb policy pollution and shift heavy computation off resource-constrained hardware without compromising privacy. Locally, actor rectification enriches policy gradients via a zeroth-order search for high-Q actions plus a bespoke regularizer that nudges the policy toward them. A $δ$-periodic strategy further reduces local computation. We theoretically provide safe policy improvement performance guarantees. Extensive experiments show FORLER consistently outperforms strong baselines under varying data quality and heterogeneity.