Dissecting Outlier Dynamics in LLM NVFP4 Pretraining
作者: Peijie Dong, Ruibo Fan, Yuechen Tao, Di Mou, Wenhu Hu, Zhenheng Tang, Yinghao Yu, Jiamang Wang, Wenbo Su, Guodong Yang, Liping Zhang, Xiaowen Chu, Baochun Li, Bo Li
分类: cs.LG, cs.CL
发布日期: 2026-02-02
备注: 39 pages, 32 figures
💡 一句话要点
针对LLM NVFP4预训练中的异常值问题,提出热通道补偿(HCP)和CHON训练方案。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 低精度量化 NVFP4 异常值检测 热通道补偿 模型训练 量化感知训练
📋 核心要点
- 现有基于4-bit算术的LLM训练对异常值敏感,NVFP4虽缓解了量化误差,但与BF16仍存在损失差距,需要深入理解异常值动态。
- 论文通过纵向分析,揭示了异常值在模型架构中的位置、产生原因和时间演变规律,并提出了热通道补偿(HCP)机制。
- 实验结果表明,提出的CHON训练方案能有效减小NVFP4训练与BF16训练之间的损失差距,同时保持下游任务的精度。
📝 摘要(中文)
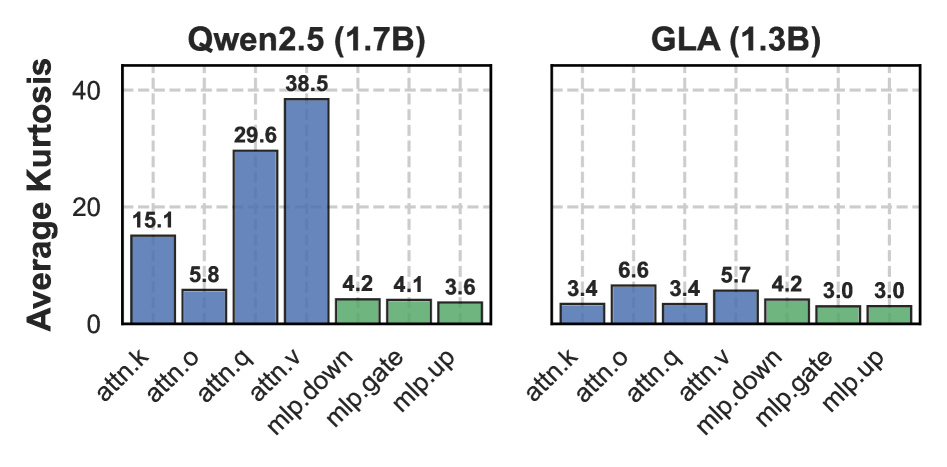
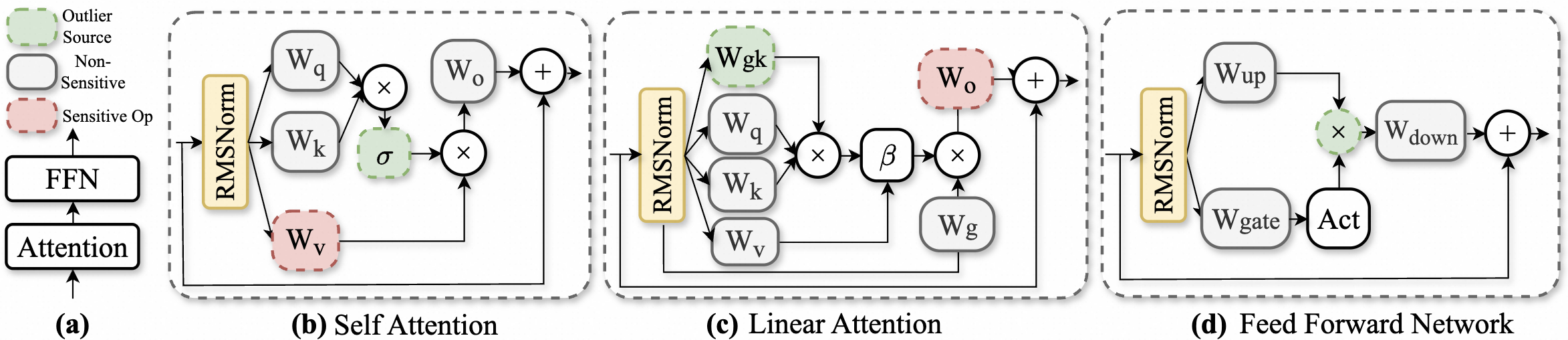
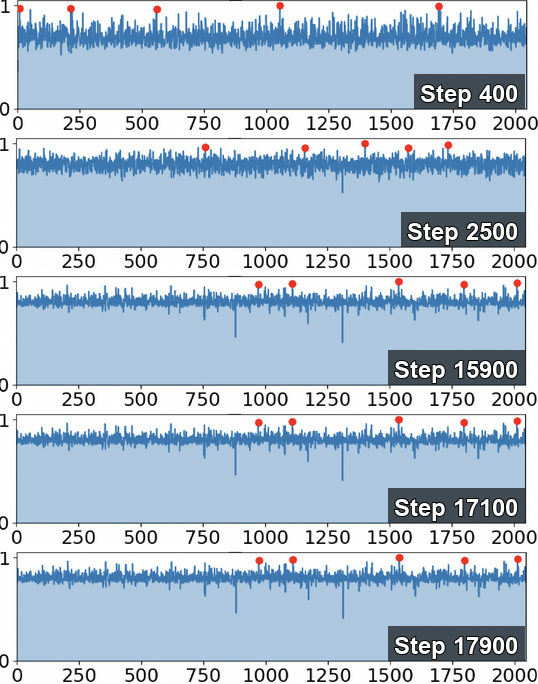
本研究深入剖析了LLM在NVFP4预训练过程中的异常值动态变化,着重分析了异常值在模型架构中的定位、产生原因以及随时间的演变规律。研究发现,相比于Softmax Attention (SA),Linear Attention (LA)虽然降低了每个张量的重尾分布,但在块量化下仍然存在持续的块级别尖峰。分析表明,SA中的Softmax、LA中的门控机制以及FFN中的SwiGLU是异常值的主要来源,且“post-QK”操作对量化更为敏感。值得注意的是,异常值从训练早期的瞬时尖峰演变为后期少量持续存在的热通道(即具有持续较大值的通道)。基于这些发现,我们提出了一种在线补偿机制——热通道补偿(HCP),它能够识别热通道并使用硬件高效的内核重新注入残差。进一步地,我们开发了CHON,一种集成了HCP和post-QK操作保护的NVFP4训练方案。在GLA-1.3B模型上进行了60B tokens的训练,CHON将损失差距相对于BF16从0.94%降低到0.58%,同时保持了下游精度。
🔬 方法详解
问题定义:论文旨在解决在使用NVFP4(4-bit浮点数变体)训练大型语言模型时,由于其有限的动态范围,模型对异常值(outliers)的敏感性增加,导致训练损失与使用BF16(Brain Floating Point 16)训练相比存在明显差距的问题。现有方法虽然尝试缓解量化误差,但未能完全消除这种损失差距,影响了模型的性能。
核心思路:论文的核心思路是通过深入分析异常值在训练过程中的动态变化,找出异常值的来源和演变规律,然后针对性地提出补偿机制。具体来说,通过识别并补偿“热通道”(hot channels),即那些在训练过程中持续具有较大值的通道,来减少量化带来的信息损失。
技术框架:论文的技术框架主要包括以下几个阶段:1) 异常值动态分析:对模型不同层和模块的激活值进行统计分析,识别异常值的来源和演变模式。2) 热通道识别:设计算法在线识别训练过程中的热通道。3) 热通道补偿(HCP):针对识别出的热通道,使用硬件高效的内核重新注入残差,以补偿量化带来的信息损失。4) CHON训练方案:将HCP与post-QK操作保护相结合,形成完整的NVFP4训练方案。
关键创新:论文最重要的技术创新点在于提出了热通道补偿(HCP)机制。HCP能够在线识别并补偿训练过程中的热通道,从而有效地减少了NVFP4量化带来的信息损失。此外,论文还发现“post-QK”操作对量化更为敏感,并针对性地进行了保护。
关键设计:HCP的关键设计包括:1) 热通道的识别标准:如何定义和识别热通道,例如基于通道激活值的统计量。2) 残差注入方式:如何高效地将残差重新注入到热通道中,例如使用硬件高效的内核。3) CHON训练方案:如何将HCP与post-QK操作保护相结合,形成完整的训练流程。具体的参数设置和损失函数细节在论文中可能有所描述,但摘要中未明确提及。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在GLA-1.3B模型上进行了60B tokens的训练后,提出的CHON训练方案将NVFP4训练与BF16训练之间的损失差距从0.94%降低到0.58%,同时保持了下游任务的精度。这表明该方法能够有效提升低精度量化训练的性能。
🎯 应用场景
该研究成果可应用于各种需要高效低精度训练的大型语言模型场景,例如资源受限的边缘设备、移动设备或对能耗敏感的数据中心。通过降低训练过程中的内存占用和计算复杂度,可以加速模型开发和部署,并降低运营成本。此外,该方法还可以推广到其他低精度量化方案中。
📄 摘要(原文)
Training large language models using 4-bit arithmetic enhances throughput and memory efficiency. Yet, the limited dynamic range of FP4 increases sensitivity to outliers. While NVFP4 mitigates quantization error via hierarchical microscaling, a persistent loss gap remains compared to BF16. This study conducts a longitudinal analysis of outlier dynamics across architecture during NVFP4 pretraining, focusing on where they localize, why they occur, and how they evolve temporally. We find that, compared with Softmax Attention (SA), Linear Attention (LA) reduces per-tensor heavy tails but still exhibits persistent block-level spikes under block quantization. Our analysis attributes outliers to specific architectural components: Softmax in SA, gating in LA, and SwiGLU in FFN, with "post-QK" operations exhibiting higher sensitivity to quantization. Notably, outliers evolve from transient spikes early in training to a small set of persistent hot channels (i.e., channels with persistently large magnitudes) in later stages. Based on these findings, we introduce Hot-Channel Patch (HCP), an online compensation mechanism that identifies hot channels and reinjects residuals using hardware-efficient kernels. We then develop CHON, an NVFP4 training recipe integrating HCP with post-QK operation protection. On GLA-1.3B model trained for 60B tokens, CHON reduces the loss gap to BF16 from 0.94% to 0.58% while maintaining downstream accuracy.