Hippasus: Effective and Efficient Automatic Feature Augmentation for Machine Learning Tasks on Relational Data
作者: Serafeim Papadias, Kostas Patroumpas, Dimitrios Skoutas
分类: cs.DB, cs.LG
发布日期: 2026-02-02
备注: 13 pages, 7 figures, 9 tables
💡 一句话要点
Hippasus:一种高效的关联数据机器学习任务自动特征增强框架。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 特征工程 自动特征增强 关系数据 大型语言模型 连接路径剪枝
📋 核心要点
- 现有特征增强方法在关系数据上进行机器学习时,面临着有效性和效率的权衡,即高精度需要探索大量连接路径,但计算成本过高。
- Hippasus 框架结合轻量级统计信号和大型语言模型的语义推理,在执行前剪枝不佳的连接路径,并采用优化算法减少执行时间。
- 实验结果表明,Hippasus 在特征增强精度上比现有方法提升高达 26.8%,同时保持了较高的运行时性能。
📝 摘要(中文)
机器学习模型严重依赖于特征质量,而有用的特征通常分散在多个关系表中。特征增强通过发现和整合来自相关表的特征来丰富基础表。然而,将此过程扩展到具有多个表和多跳路径的复杂模式仍然具有挑战性。特征增强必须解决三个核心任务:识别连接基础表到候选表的有希望的连接路径,执行这些连接以物化增强数据,以及从结果中选择信息量最大的特征。现有方法面临着有效性和效率之间的根本权衡:实现高精度需要探索许多候选路径,但穷举探索在计算上是禁止的。一些方法通过仅考虑直接邻居来妥协,限制了它们的有效性,而另一些方法则采用需要昂贵的训练数据并引入可扩展性限制的神经模型。我们提出了 Hippasus,一个模块化框架,通过三个关键贡献实现了这两个目标。首先,我们将轻量级统计信号与来自大型语言模型的语义推理相结合,以在执行之前修剪没有希望的连接路径,从而将计算资源集中在高质量的候选对象上。其次,我们采用优化的多路连接算法并整合来自多个路径的特征,从而大大减少了执行时间。第三,我们将基于LLM的语义理解与统计度量相结合,以选择在语义上有意义且在经验上具有预测性的特征。我们在公开数据集上的实验评估表明,Hippasus 在特征增强精度方面比最先进的基线提高了高达 26.8%,同时还提供了很高的运行时性能。
🔬 方法详解
问题定义:论文旨在解决关系数据上机器学习任务中特征工程的难题,具体来说,是如何高效地从多个关联表中自动发现和整合有用的特征。现有方法要么效率低下,需要耗费大量计算资源探索所有可能的连接路径;要么效果不佳,仅考虑相邻表或使用需要大量训练数据的复杂模型,导致特征质量不高。
核心思路:Hippasus 的核心思路是在特征增强过程中,利用轻量级的统计信号和大型语言模型的语义理解,对连接路径进行预先筛选,从而避免不必要的计算开销,并将资源集中在更有可能产生高质量特征的路径上。同时,通过优化的多路连接算法和特征整合策略,进一步提高效率。
技术框架:Hippasus 框架包含三个主要模块:1) 连接路径剪枝:利用统计信号和 LLM 的语义推理,评估连接路径的潜在价值,并剪除不佳路径。2) 特征物化:采用优化的多路连接算法,将选定的连接路径物化为增强的特征。3) 特征选择:结合 LLM 的语义理解和统计度量,选择既具有语义意义又具有预测能力的特征。
关键创新:Hippasus 的关键创新在于将大型语言模型的语义理解引入到特征增强过程中。通过 LLM,可以更好地理解表和列的含义,从而更准确地评估连接路径的潜在价值,并选择更具语义意义的特征。这与传统方法仅依赖于统计信号有本质区别。
关键设计:在连接路径剪枝阶段,Hippasus 使用 LLM 对表和列进行语义编码,并计算连接路径的语义相似度。同时,结合统计信号(如连接路径的长度、连接键的唯一性等)进行综合评估。在特征选择阶段,Hippasus 使用 LLM 对特征进行语义描述,并结合统计度量(如信息增益、相关性等)选择最终的特征子集。具体的 LLM 选择和参数设置在论文中有详细描述,但此处未提供。
🖼️ 关键图片

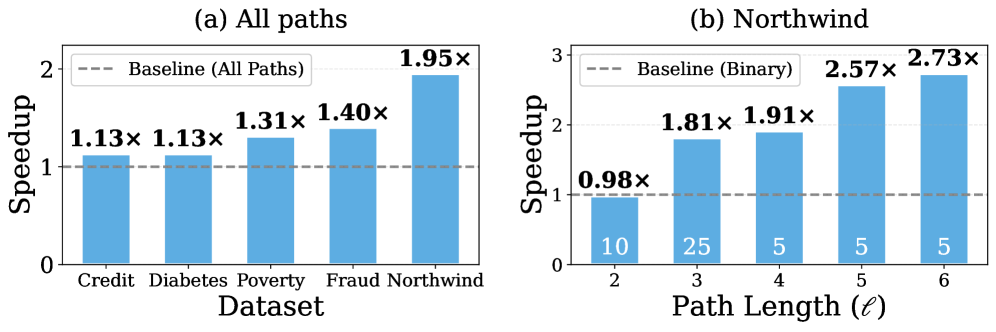
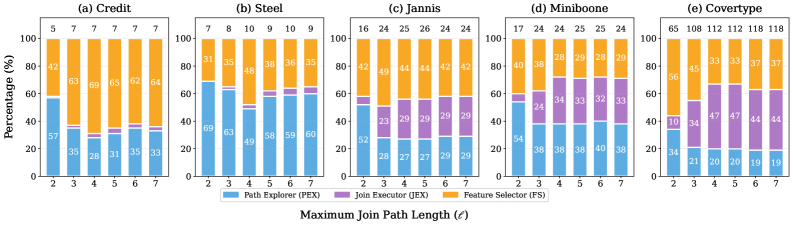
📊 实验亮点
实验结果表明,Hippasus 在公开数据集上显著优于现有的特征增强方法。例如,在某些数据集上,Hippasus 的特征增强精度比最先进的基线提高了高达 26.8%。此外,Hippasus 还具有较高的运行时性能,能够处理具有大量表和复杂连接关系的数据集。
🎯 应用场景
Hippasus 可应用于各种需要从关系数据中进行特征工程的机器学习任务,例如欺诈检测、客户流失预测、推荐系统等。该框架能够自动发现和整合来自多个表的有用特征,从而提高模型性能,并减少人工特征工程的工作量。未来,可以进一步扩展 Hippasus,支持更多类型的数据源和更复杂的特征工程操作。
📄 摘要(原文)
Machine learning models depend critically on feature quality, yet useful features are often scattered across multiple relational tables. Feature augmentation enriches a base table by discovering and integrating features from related tables through join operations. However, scaling this process to complex schemas with many tables and multi-hop paths remains challenging. Feature augmentation must address three core tasks: identify promising join paths that connect the base table to candidate tables, execute these joins to materialize augmented data, and select the most informative features from the results. Existing approaches face a fundamental tradeoff between effectiveness and efficiency: achieving high accuracy requires exploring many candidate paths, but exhaustive exploration is computationally prohibitive. Some methods compromise by considering only immediate neighbors, limiting their effectiveness, while others employ neural models that require expensive training data and introduce scalability limitations. We present Hippasus, a modular framework that achieves both goals through three key contributions. First, we combine lightweight statistical signals with semantic reasoning from Large Language Models to prune unpromising join paths before execution, focusing computational resources on high-quality candidates. Second, we employ optimized multi-way join algorithms and consolidate features from multiple paths, substantially reducing execution time. Third, we integrate LLM-based semantic understanding with statistical measures to select features that are both semantically meaningful and empirically predictive. Our experimental evaluation on publicly available datasets shows that Hippasus substantially improves feature augmentation accuracy by up to 26.8% over state-of-the-art baselines while also offering high runtime performance.