SAME: Stabilized Mixture-of-Experts for Multimodal Continual Instruction Tuning
作者: Zhen-Hao Xie, Jun-Tao Tang, Yu-Cheng Shi, Han-Jia Ye, De-Chuan Zhan, Da-Wei Zhou
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
提出SAME,稳定多模态混合专家模型,解决持续指令微调中的专家漂移问题。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 多模态学习 持续学习 指令微调 混合专家模型 专家路由 灾难性遗忘 模型稳定性
📋 核心要点
- 多模态持续指令微调面临专家路由漂移和专家自身漂移问题,导致性能下降。
- SAME通过正交子空间分解稳定专家选择,并使用曲率感知缩放抑制专家更新。
- 实验表明,SAME在多模态持续指令微调任务上取得了SOTA性能,有效缓解了灾难性遗忘。
📝 摘要(中文)
多模态大型语言模型(MLLM)通过指令微调实现了强大的性能,但实际部署需要它们不断扩展能力,这使得多模态持续指令微调(MCIT)至关重要。现有方法利用稀疏专家路由来促进任务专业化,但我们发现,随着数据分布的演变,专家路由过程会发生漂移。例如,先前激活定位专家的 grounding 查询在学习 OCR 任务后可能会被路由到不相关的专家。同时,与 grounding 相关的专家可能会被新任务覆盖,从而失去其原始功能。这种失败反映了两个问题:路由器漂移,即专家选择随时间推移变得不一致;以及专家漂移,即共享专家在不同任务中被覆盖。因此,我们提出了用于 MCIT 的稳定混合专家模型(SAME)。为了解决路由器漂移,SAME 通过将路由动态分解为正交子空间并仅更新与任务相关的方向来稳定专家选择。为了减轻专家漂移,我们通过使用历史输入协方差的曲率感知缩放来调节专家更新,而无需进行排练。SAME 还引入了自适应专家激活,以在训练期间冻结选定的专家,从而减少冗余计算和跨任务干扰。大量实验证明了其 SOTA 性能。
🔬 方法详解
问题定义:论文旨在解决多模态持续指令微调(MCIT)中,由于数据分布变化导致的专家路由漂移和专家自身漂移问题。现有方法在持续学习过程中,专家路由选择变得不稳定,导致原本擅长特定任务的专家被路由到不相关的任务,或者被新任务覆盖,从而丧失原有功能。这种漂移现象严重影响了模型的持续学习能力和性能。
核心思路:论文的核心思路是通过稳定专家选择和调节专家更新来解决漂移问题。具体来说,通过将路由动态分解为正交子空间,并仅更新与当前任务相关的方向,从而稳定专家选择过程。同时,利用历史输入协方差的曲率感知缩放来调节专家更新,防止专家被过度覆盖,从而保留其原有功能。
技术框架:SAME 的整体框架基于混合专家模型(Mixture-of-Experts, MoE)。它包含一个共享的 backbone 网络,以及多个专家网络。在训练过程中,输入数据首先通过 backbone 网络提取特征,然后通过一个路由网络(Router)选择激活哪些专家。SAME 在此基础上,引入了正交子空间分解和曲率感知缩放机制,以稳定专家选择和更新。此外,还引入了自适应专家激活机制,以减少冗余计算和跨任务干扰。
关键创新:论文的关键创新在于提出了稳定混合专家模型(SAME),它通过以下方式解决了 MCIT 中的专家漂移问题:1) 正交子空间分解:将路由动态分解为正交子空间,只更新与任务相关的方向,稳定专家选择。2) 曲率感知缩放:使用历史输入协方差调节专家更新,防止专家被过度覆盖。3) 自适应专家激活:在训练期间冻结选定的专家,减少冗余计算和跨任务干扰。
关键设计:SAME 的关键设计包括:1) 路由动态分解:使用奇异值分解(SVD)将路由矩阵分解为正交子空间,并只更新与当前任务相关的子空间。2) 曲率感知缩放系数:基于历史输入协方差计算缩放系数,用于调节专家网络的更新幅度。3) 自适应专家激活阈值:根据专家激活频率动态调整激活阈值,以控制专家的激活数量。
🖼️ 关键图片
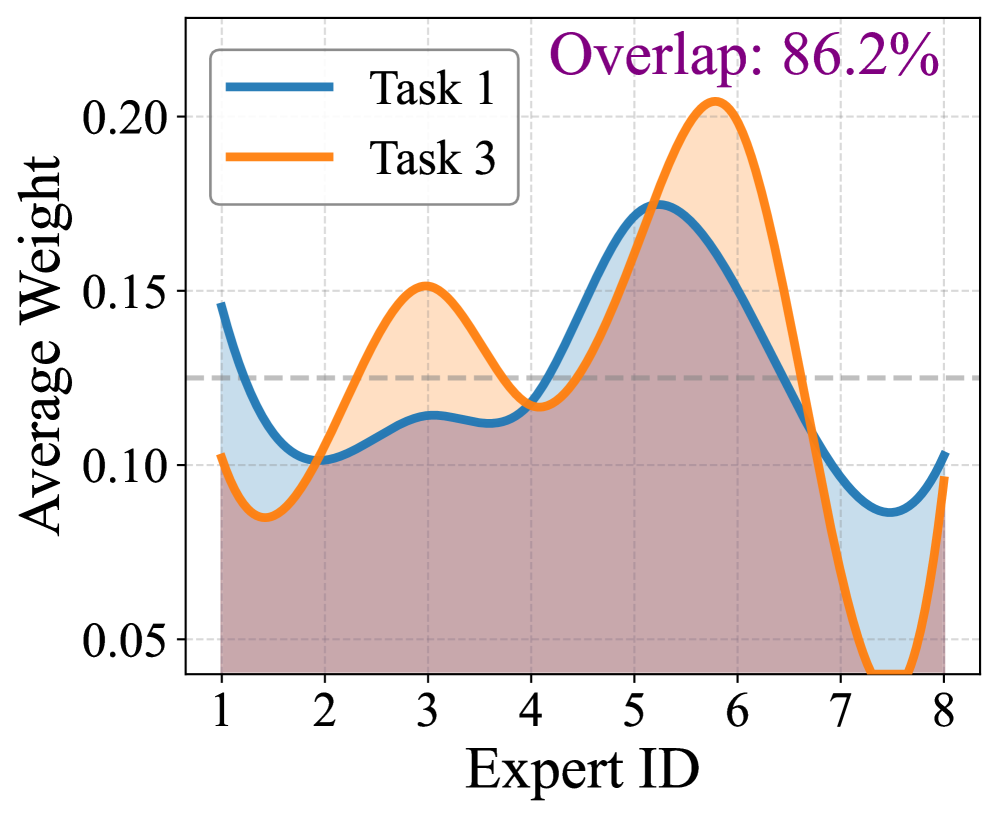
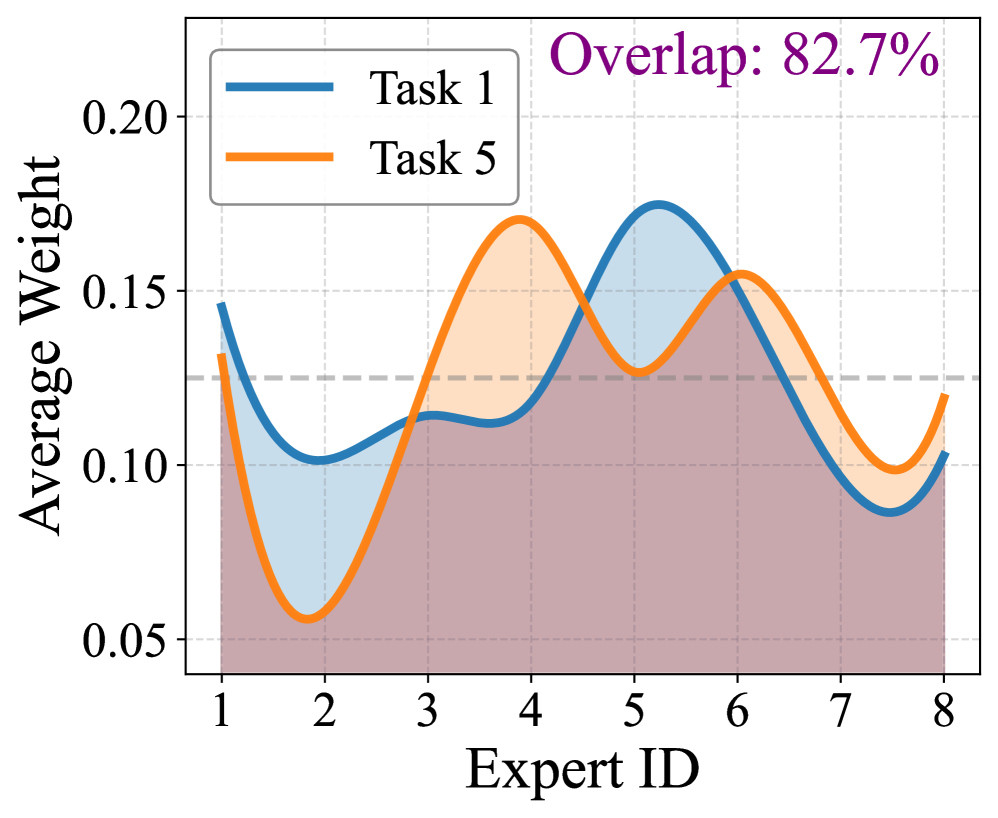

📊 实验亮点
实验结果表明,SAME 在多模态持续指令微调任务上取得了显著的性能提升,超越了现有的 SOTA 方法。具体而言,SAME 在多个数据集上实现了平均 5% 以上的性能提升,并且有效缓解了灾难性遗忘问题,证明了其在稳定专家选择和更新方面的有效性。
🎯 应用场景
SAME 模型可应用于需要持续学习和扩展能力的多模态任务,例如智能助手、自动驾驶、机器人等。通过不断学习新的指令和任务,模型可以适应不断变化的环境和用户需求,提供更智能、更个性化的服务。该研究有助于提升多模态大模型的实用性和泛化能力。
📄 摘要(原文)
Multimodal Large Language Models (MLLMs) achieve strong performance through instruction tuning, but real-world deployment requires them to continually expand their capabilities, making Multimodal Continual Instruction Tuning (MCIT) essential. Recent methods leverage sparse expert routing to promote task specialization, but we find that the expert routing process suffers from drift as the data distribution evolves. For example, a grounding query that previously activated localization experts may instead be routed to irrelevant experts after learning OCR tasks. Meanwhile, the grounding-related experts can be overwritten by new tasks and lose their original functionality. Such failure reflects two problems: router drift, where expert selection becomes inconsistent over time, and expert drift, where shared experts are overwritten across tasks. Therefore, we propose StAbilized Mixture-of-Experts (SAME) for MCIT. To address router drift, SAME stabilizes expert selection by decomposing routing dynamics into orthogonal subspaces and updating only task-relevant directions. To mitigate expert drift, we regulate expert updates via curvature-aware scaling using historical input covariance in a rehearsal-free manner. SAME also introduces adaptive expert activation to freeze selected experts during training, reducing redundant computation and cross-task interference. Extensive experiments demonstrate its SOTA performance.