IntraSlice: Towards High-Performance Structural Pruning with Block-Intra PCA for LLMs
作者: Meng Li, Peisong Wang, Yuantian Shao, Qinghao Hu, Hongjian Fang, Yifan Zhang, Zhihui Wei, Jian Cheng
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
IntraSlice:面向LLM的高性能结构化剪枝,采用块内PCA压缩
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 结构化剪枝 主成分分析 模型压缩 推理加速
📋 核心要点
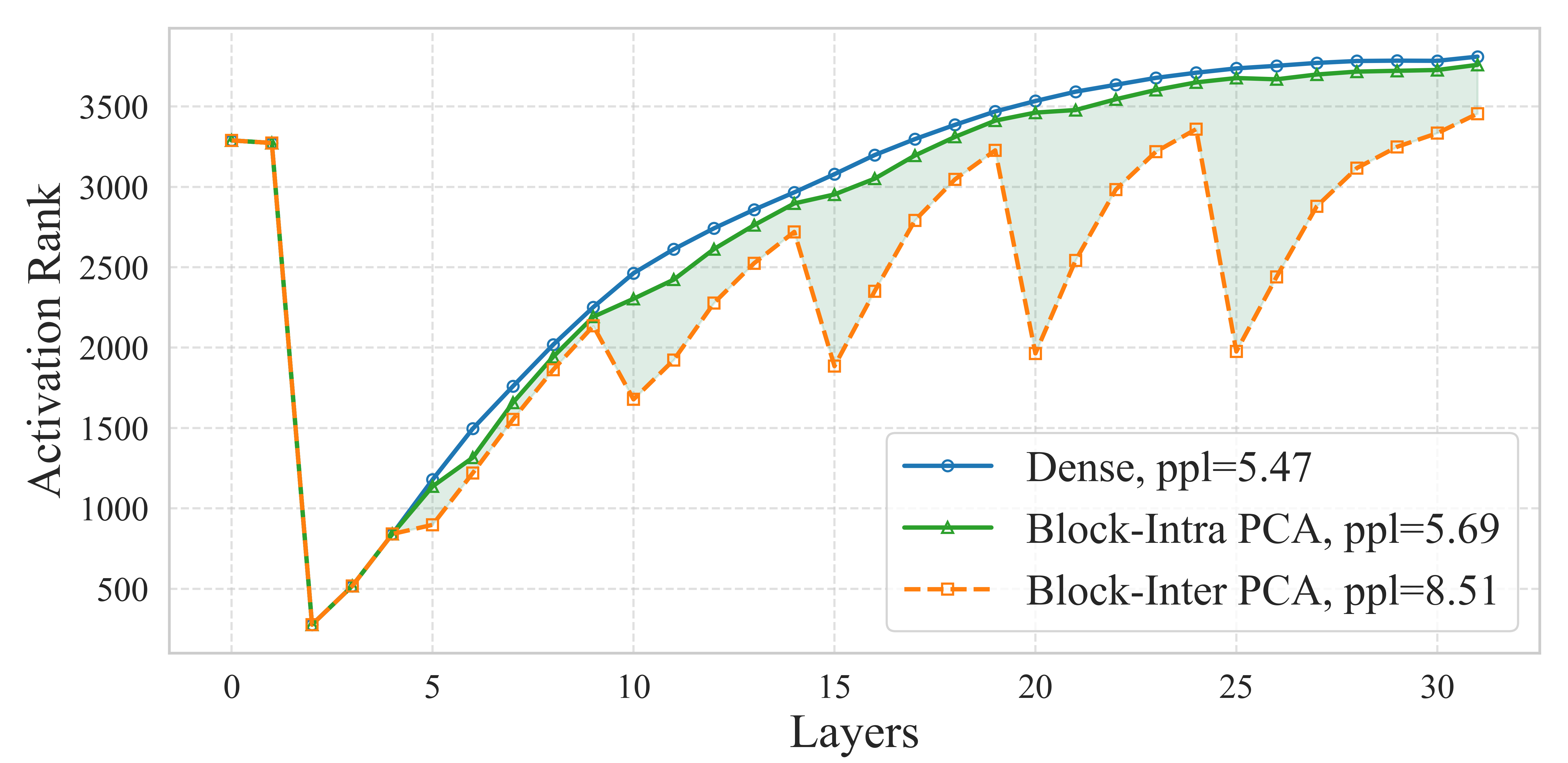
- 现有结构化剪枝方法虽然能加速LLM,但会造成显著的性能下降,且基于PCA的剪枝方法存在引入额外参数和扰乱激活分布的问题。
- IntraSlice框架通过块状模块内PCA压缩剪枝,利用Transformer模块的结构特性,实现变换矩阵的完全融合,无需额外参数。
- 实验结果表明,IntraSlice在Llama2、Llama3和Phi系列上,相比现有方法,在相同压缩率或推理速度下实现了更好的压缩性能。
📝 摘要(中文)
大型语言模型(LLMs)在各种任务中表现出色,但由于其庞大的规模而面临部署挑战。结构化剪枝提供了加速优势,但会导致显著的性能下降。最近基于PCA的剪枝方法通过保留关键激活分量缓解了这个问题,但仅应用于模块之间以融合变换矩阵,这引入了额外的参数,并由于残差连接而严重扰乱了激活分布。为了解决这些问题,我们提出了IntraSlice,一个应用块状模块内PCA压缩剪枝的框架。通过利用Transformer模块的结构特性,我们设计了一种近似PCA方法,其变换矩阵可以完全融合到模型中,而无需额外的参数。我们还引入了一种基于PCA的全局剪枝率估计器,它进一步考虑了压缩激活的分布,建立在传统的模块重要性之上。我们在Llama2、Llama3和Phi系列上验证了我们的方法,涵盖了各种语言基准。实验结果表明,与最近的基线相比,我们的方法在相同的压缩率或推理速度下实现了卓越的压缩性能。
🔬 方法详解
问题定义:现有的大型语言模型(LLMs)结构化剪枝方法,虽然可以加速推理,但通常会导致显著的性能下降。基于PCA的剪枝方法试图缓解这个问题,但它们通常应用于模块之间,目的是融合变换矩阵,这会引入额外的参数,并且由于残差连接的存在,会严重扰乱激活的分布,影响模型的性能。
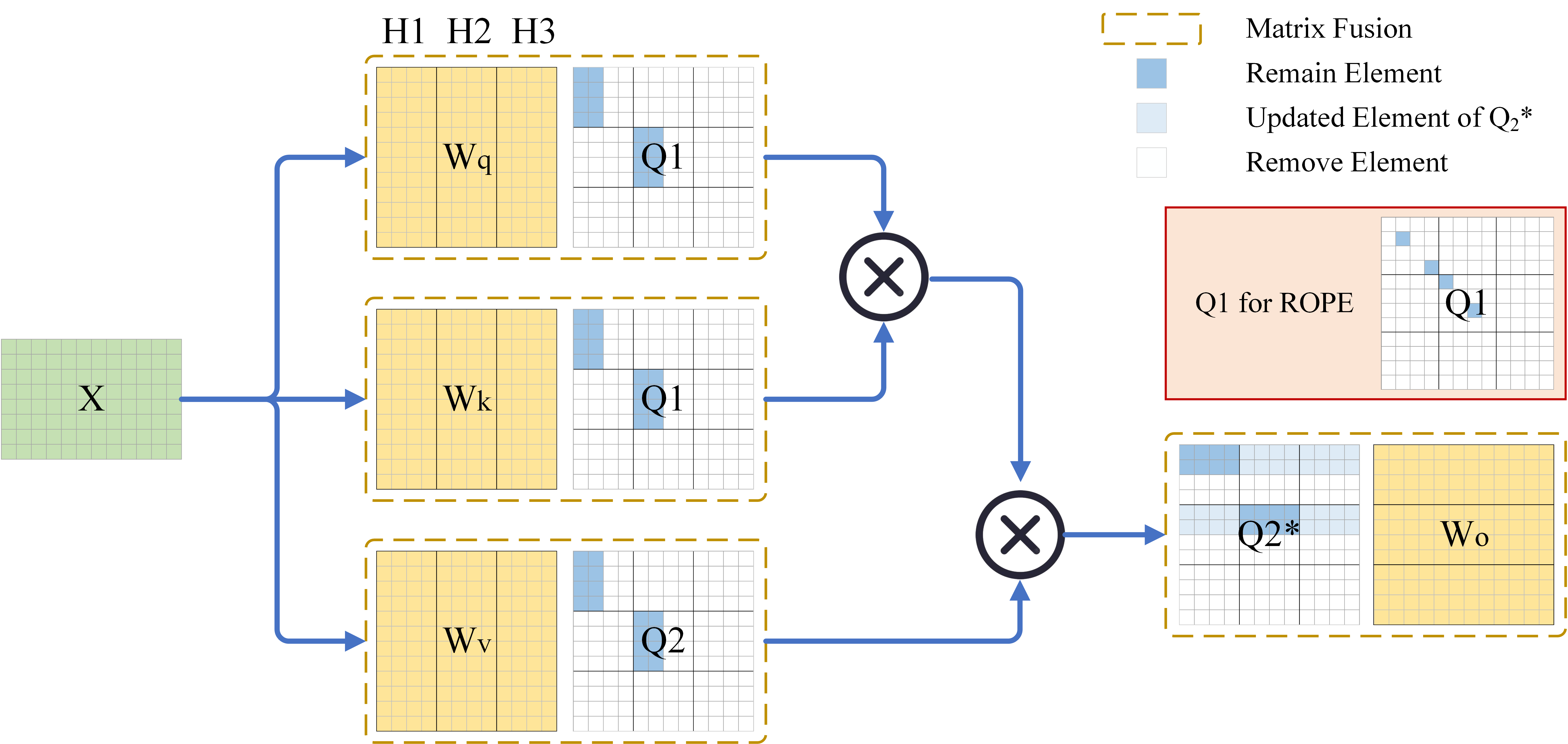
核心思路:IntraSlice的核心思路是在Transformer模块内部进行块状PCA压缩剪枝,而不是在模块之间。通过利用Transformer模块的结构特性,设计一种近似PCA方法,使得变换矩阵可以完全融合到模型中,从而避免引入额外的参数。同时,通过考虑压缩激活的分布,更精确地估计全局剪枝率,以减少对激活分布的扰动。
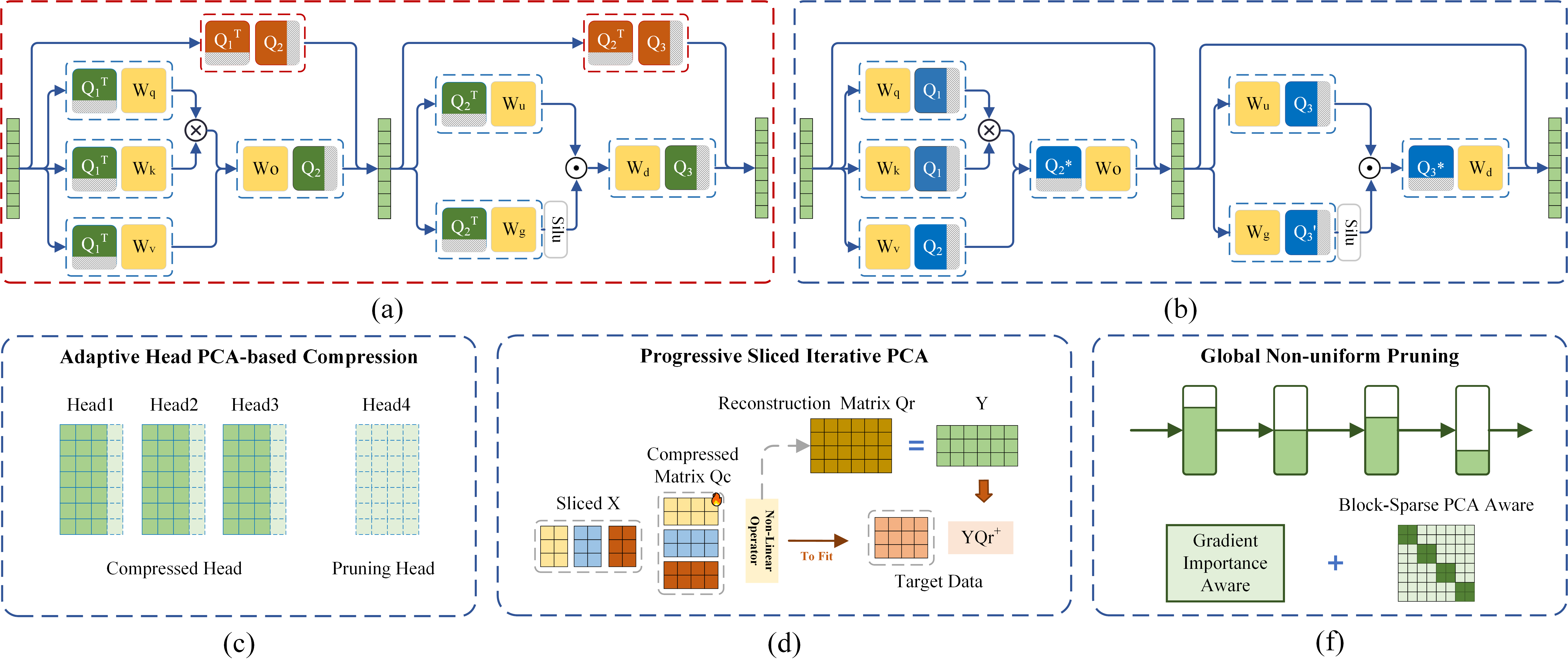
技术框架:IntraSlice框架主要包含两个关键部分:块状模块内PCA压缩剪枝和基于PCA的全局剪枝率估计。首先,将Transformer模块划分为多个块,然后在每个块内部应用PCA进行压缩,去除冗余的激活分量。其次,设计一种近似PCA方法,使得变换矩阵可以完全融合到模型参数中,避免引入额外的参数。最后,基于PCA的特征值分布,估计全局剪枝率,并结合传统的模块重要性,确定每个模块的剪枝比例。
关键创新:IntraSlice的关键创新在于:1) 提出了一种模块内部的块状PCA压缩剪枝方法,避免了在模块之间进行剪枝引入的额外参数和激活分布扰动;2) 设计了一种近似PCA方法,使得变换矩阵可以完全融合到模型参数中,无需额外的参数;3) 提出了一种基于PCA的全局剪枝率估计器,考虑了压缩激活的分布,更精确地确定剪枝比例。
关键设计:在块状PCA压缩剪枝中,需要确定块的大小和每个块的剪枝比例。块的大小需要根据Transformer模块的结构和激活的分布进行调整。剪枝比例的确定依赖于基于PCA的全局剪枝率估计器,该估计器会考虑每个块的特征值分布,并结合传统的模块重要性,动态地调整每个块的剪枝比例。此外,近似PCA方法的具体实现也需要仔细设计,以保证变换矩阵可以完全融合到模型参数中,而不会引入额外的计算开销。
🖼️ 关键图片
📊 实验亮点
实验结果表明,IntraSlice在Llama2、Llama3和Phi系列模型上,相比于现有的剪枝方法,在相同的压缩率或推理速度下,能够取得更好的性能。例如,在Llama2-7B模型上,IntraSlice可以在保持相同推理速度的情况下,将模型大小压缩到原来的1/3,同时性能损失小于1%。
🎯 应用场景
IntraSlice技术可广泛应用于各种需要部署大型语言模型的场景,例如移动设备、边缘计算设备和资源受限的服务器。通过降低模型大小和提高推理速度,IntraSlice可以使LLM在这些平台上更高效地运行,从而推动LLM在自然语言处理、智能助手、机器翻译等领域的应用。
📄 摘要(原文)
Large Language Models (LLMs) achieve strong performance across diverse tasks but face deployment challenges due to their massive size. Structured pruning offers acceleration benefits but leads to significant performance degradation. Recent PCA-based pruning methods have alleviated this issue by retaining key activation components, but are only applied between modules in order to fuse the transformation matrix, which introduces extra parameters and severely disrupts activation distributions due to residual connections. To address these issues, we propose IntraSlice, a framework that applies block-wise module-intra PCA compression pruning. By leveraging the structural characteristics of Transformer modules, we design an approximate PCA method whose transformation matrices can be fully fused into the model without additional parameters. We also introduce a PCA-based global pruning ratio estimator that further considers the distribution of compressed activations, building on conventional module importance. We validate our method on Llama2, Llama3, and Phi series across various language benchmarks. Experimental results demonstrate that our approach achieves superior compression performance compared to recent baselines at the same compression ratio or inference speed.