Self-Consolidation for Self-Evolving Agents
作者: Hongzhuo Yu, Fei Zhu, Guo-Sen Xie, Ling Shao
分类: cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出自演化框架,通过对比反思和自固化机制提升LLM智能体的终身学习能力
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: LLM智能体 自演化 对比反思 自固化 终身学习 知识蒸馏 经验学习
📋 核心要点
- 现有LLM智能体缺乏从失败经验中学习和长期演化的能力,且持续积累文本经验导致检索效率降低和噪声增加。
- 论文提出一种自演化框架,通过对比反思总结错误模式,并利用自固化机制将经验提炼成可学习参数。
- 实验结果表明,该方法能够有效提升LLM智能体的长期学习能力,使其更好地适应复杂环境。
📝 摘要(中文)
大型语言模型(LLM)智能体在解决问题方面表现出色,但通常作为静态系统运行,缺乏通过终身交互进行演化的能力。现有方法主要依赖于检索成功的历史轨迹作为演示,但存在两个关键限制。首先,仅关注成功案例忽略了失败尝试中蕴含的丰富教学价值,阻碍了智能体识别和避免重复出现的陷阱。其次,持续积累文本经验不仅增加了检索的时间消耗,而且不可避免地引入噪声并耗尽当前LLM的最大上下文窗口。为了解决这些挑战,我们提出了一种新颖的LLM智能体自演化框架,引入了一种互补的演化机制:首先,引入对比反思策略,显式地总结容易出错的模式并捕获可重用的见解。其次,我们提出了一种自固化机制,将非参数文本经验提炼成紧凑的可学习参数。这使得智能体能够将广泛的历史经验直接内化到其潜在空间中。大量实验证明了我们的方法在长期智能体演化中的优势。
🔬 方法详解
问题定义:现有的大型语言模型智能体通常是静态的,无法像人类一样通过终身学习不断进化。它们主要依赖于检索成功的历史轨迹进行学习,忽略了失败经验的价值。此外,随着交互次数的增加,存储的文本经验会迅速增长,导致检索效率降低,并可能超出LLM的上下文窗口限制。因此,如何让LLM智能体有效地从成功和失败的经验中学习,并将其内化为自身的知识,是一个亟待解决的问题。
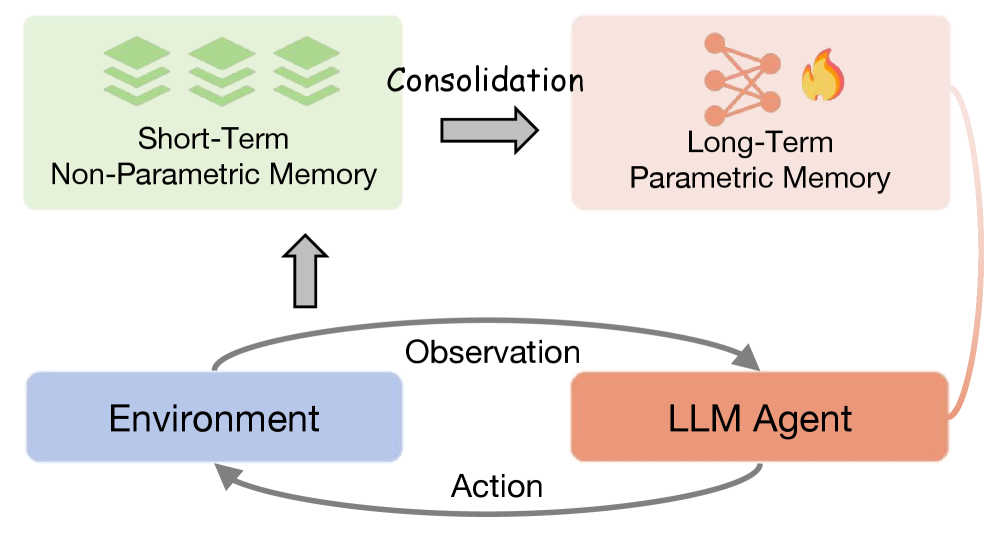
核心思路:论文的核心思路是让LLM智能体能够从自身的经验中进行“反思”和“固化”。通过对比成功和失败的经验,智能体可以识别出容易出错的模式,并总结出可重用的见解。然后,通过自固化机制,将这些非参数化的文本经验提炼成紧凑的可学习参数,从而将历史经验内化到智能体的潜在空间中。这样,智能体就可以在未来的决策中更好地利用这些知识,提高解决问题的能力。
技术框架:该自演化框架包含两个主要模块:对比反思和自固化。首先,智能体与环境进行交互,生成一系列的轨迹数据,包括成功和失败的案例。然后,对比反思模块分析这些轨迹数据,识别出容易出错的模式,并生成相应的反思文本。这些反思文本包含了智能体从失败经验中学习到的知识。接下来,自固化模块将这些反思文本提炼成紧凑的可学习参数,例如,通过训练一个小的神经网络来模拟反思文本的行为。最后,将这些可学习参数整合到LLM智能体的潜在空间中,使其能够更好地利用历史经验。
关键创新:该论文的关键创新在于提出了对比反思和自固化这两种互补的演化机制。对比反思使得智能体能够从失败经验中学习,避免重复犯错。自固化机制则将非参数化的文本经验提炼成紧凑的可学习参数,解决了存储和检索效率的问题。与现有方法相比,该方法更加注重从失败经验中学习,并且能够有效地将历史经验内化到智能体的潜在空间中。
关键设计:在对比反思模块中,可以使用不同的对比学习方法来识别容易出错的模式。例如,可以使用Triplet Loss来学习成功和失败案例之间的差异。在自固化模块中,可以使用不同的蒸馏技术来将反思文本提炼成可学习参数。例如,可以使用知识蒸馏来训练一个小的神经网络,使其能够模拟反思文本的行为。损失函数的设计需要考虑到反思文本的质量和可学习参数的表达能力。
🖼️ 关键图片
📊 实验亮点
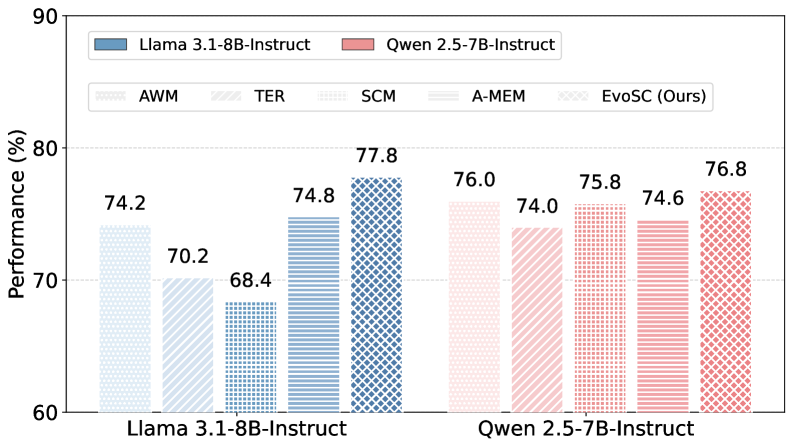
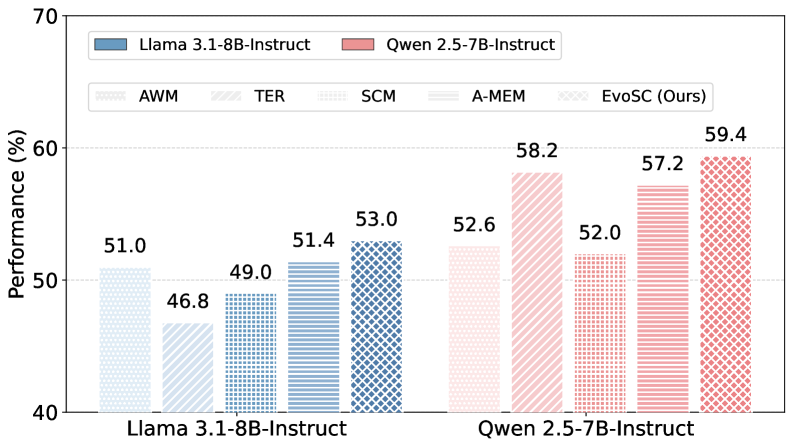
论文通过大量实验验证了所提出方法的有效性。实验结果表明,与现有方法相比,该方法能够显著提升LLM智能体的长期学习能力。具体的性能数据和对比基线在论文中进行了详细的展示,证明了该方法在长期智能体演化方面的优势。
🎯 应用场景
该研究成果可应用于各种需要长期自主学习的智能体系统,例如:机器人导航、游戏AI、自动驾驶等。通过不断从经验中学习和进化,智能体可以更好地适应复杂多变的环境,提高解决问题的能力和效率。该研究对于提升智能体的自主性和鲁棒性具有重要意义。
📄 摘要(原文)
While large language model (LLM) agents have demonstrated impressive problem-solving capabilities, they typically operate as static systems, lacking the ability to evolve through lifelong interaction. Existing attempts to bridge this gap primarily rely on retrieving successful past trajectories as demonstrations. However, this paradigm faces two critical limitations. First, by focusing solely on success, agents overlook the rich pedagogical value embedded in failed attempts, preventing them from identifying and avoiding recurrent pitfalls. Second, continually accumulating textual experiences not only increases the time consumption during retrieval but also inevitably introduces noise and exhausts the largest context window of current LLMs. To address these challenges, we propose a novel self-evolving framework for LLM agents that introduces a complementary evolution mechanism: First, a contrastive reflection strategy is introduced to explicitly summarize error-prone patterns and capture reusable insights. Second, we propose a self-consolidation mechanism that distills non-parametric textual experience into compact learnable parameters. This enables the agent to internalize extensive historical experience directly into its latent space. Extensive experiments demonstrate the advantages of our method in long-term agent evolution.