Grounding Generated Videos in Feasible Plans via World Models
作者: Christos Ziakas, Amir Bar, Alessandra Russo
分类: cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出GVP-WM以解决视频生成计划的可行性问题
🎯 匹配领域: 支柱一:机器人控制 (Robot Control) 支柱二:RL算法与架构 (RL & Architecture)
关键词: 视频生成 规划方法 世界模型 潜在轨迹优化 动作序列 物理约束 长时间计划
📋 核心要点
- 现有的视频生成模型在生成计划时常常缺乏时间一致性和物理约束,导致生成的计划不可执行。
- GVP-WM方法通过学习的世界模型将视频生成的计划转化为可行的动作序列,解决了可执行性问题。
- 实验结果表明,GVP-WM能够从违反物理约束的视频中恢复可行的长时间计划,表现出显著的性能提升。
📝 摘要(中文)
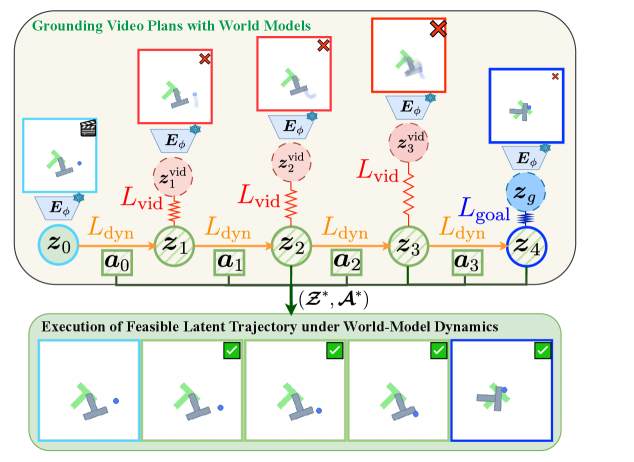
大规模视频生成模型在零-shot视觉规划方面展现出新兴能力,但生成的视频计划常常违反时间一致性和物理约束,导致在映射到可执行动作时出现失败。为了解决这一问题,本文提出了基于世界模型的Grounding Video Plans with World Models (GVP-WM)方法,该方法通过学习的动作条件世界模型将视频生成的计划转化为可行的动作序列。在测试阶段,GVP-WM首先从初始观察和目标观察生成视频计划,然后通过视频引导的潜在轨迹配合将视频指导投影到动态可行的潜在轨迹流形上。具体而言,我们将基础设定为一个目标条件的潜在空间轨迹优化问题,在世界模型动态下共同优化潜在状态和动作,同时保持与视频生成计划的语义一致性。实验证明,GVP-WM能够从零-shot图像到视频生成和违反物理约束的运动模糊视频中恢复可行的长时间计划,适用于导航和操作仿真任务。
🔬 方法详解
问题定义:本文旨在解决视频生成计划在映射到可执行动作时常常违反时间一致性和物理约束的问题。现有方法在处理这些生成计划时存在显著的局限性,导致计划的不可行性。
核心思路:GVP-WM通过引入学习的动作条件世界模型,将视频生成的计划与动态可行的潜在轨迹相结合,从而实现可行的动作序列生成。该方法的设计旨在优化潜在状态和动作,同时保持与视频生成计划的语义一致性。
技术框架:GVP-WM的整体流程包括两个主要阶段:首先生成视频计划,然后通过视频引导的潜在轨迹配合将其投影到可行的潜在轨迹流形上。该方法利用目标条件的潜在空间轨迹优化来实现这一过程。
关键创新:GVP-WM的主要创新在于将视频生成计划的基础设定转化为目标条件的潜在空间轨迹优化问题,这一方法与传统的规划方法在本质上存在显著区别,能够有效处理复杂的动态环境。
关键设计:在设计中,GVP-WM采用了特定的损失函数来确保生成的轨迹与视频计划的语义一致,同时在网络结构上引入了动作条件的世界模型,以提高生成计划的可行性和准确性。
🖼️ 关键图片


📊 实验亮点
实验结果显示,GVP-WM在处理零-shot图像到视频生成和运动模糊视频时,能够有效恢复可行的长时间计划,相较于基线方法,性能提升显著,展示了其在导航和操作仿真任务中的优势。
🎯 应用场景
该研究的潜在应用领域包括机器人导航、自动化操作和智能视频分析等。通过将视频生成的计划转化为可行的动作序列,GVP-WM能够在复杂环境中实现更高效的任务执行,具有重要的实际价值和未来影响。
📄 摘要(原文)
Large-scale video generative models have shown emerging capabilities as zero-shot visual planners, yet video-generated plans often violate temporal consistency and physical constraints, leading to failures when mapped to executable actions. To address this, we propose Grounding Video Plans with World Models (GVP-WM), a planning method that grounds video-generated plans into feasible action sequences using a learned action-conditioned world model. At test-time, GVP-WM first generates a video plan from initial and goal observations, then projects the video guidance onto the manifold of dynamically feasible latent trajectories via video-guided latent collocation. In particular, we formulate grounding as a goal-conditioned latent-space trajectory optimization problem that jointly optimizes latent states and actions under world-model dynamics, while preserving semantic alignment with the video-generated plan. Empirically, GVP-WM recovers feasible long-horizon plans from zero-shot image-to-video-generated and motion-blurred videos that violate physical constraints, across navigation and manipulation simulation tasks.