Efficient Epistemic Uncertainty Estimation for Large Language Models via Knowledge Distillation
作者: Seonghyeon Park, Jewon Yeom, Jaewon Sok, Jeongjae Park, Heejun Kim, Taesup Kim
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
提出基于知识蒸馏的高效LLM不确定性估计方法,降低幻觉并提升安全性。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大型语言模型 不确定性估计 知识蒸馏 认知不确定性 幻觉检测 在线随机蒸馏 数据增强
📋 核心要点
- 现有方法难以在大规模LLM中高效估计认知不确定性,深度集成计算成本过高。
- 利用小型draft模型,通过偏差-方差分解近似认知不确定性,降低计算复杂度。
- 引入在线随机蒸馏和数据多样性Draft策略,提升目标近似的准确性和draft的多样性。
📝 摘要(中文)
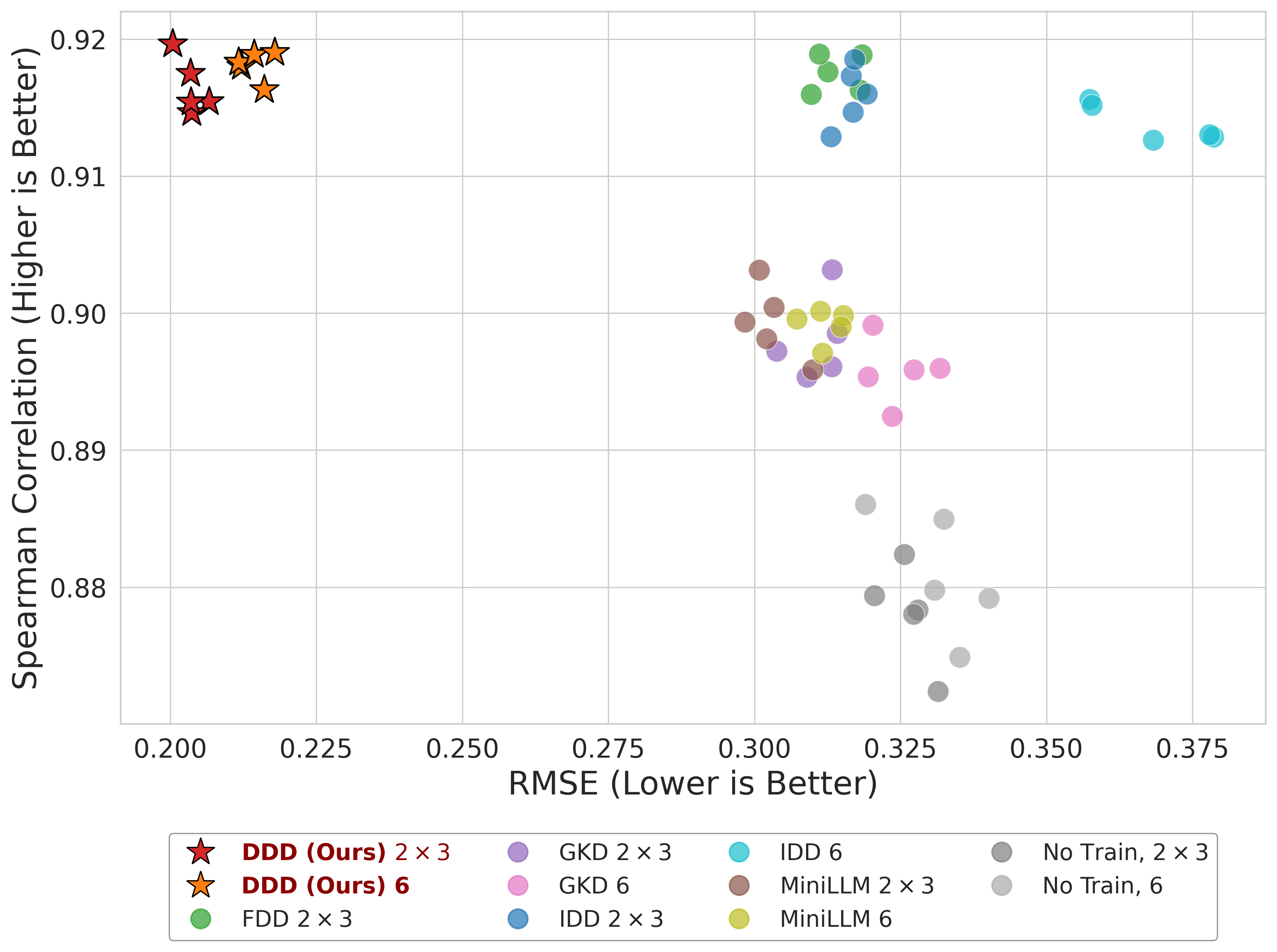
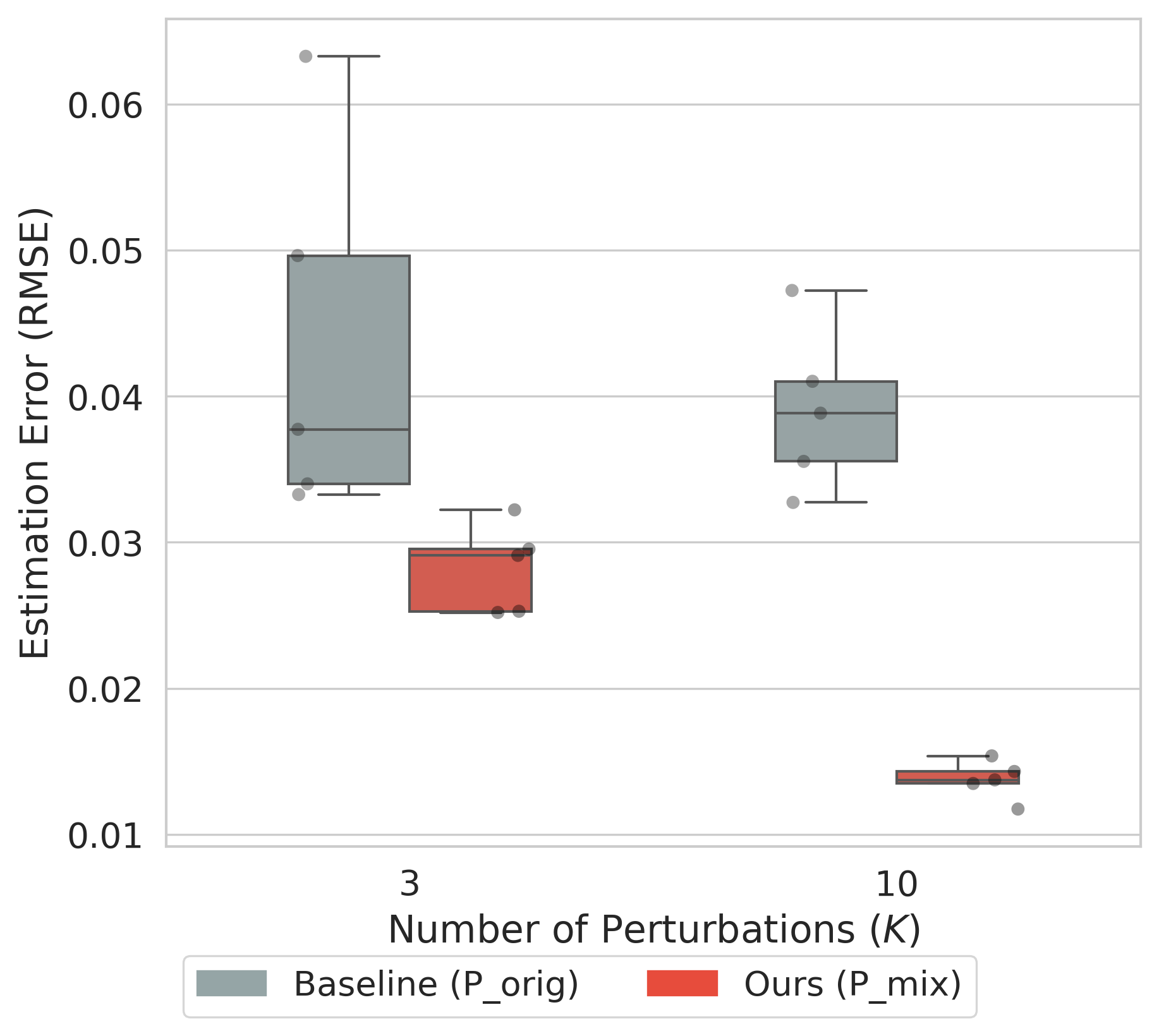
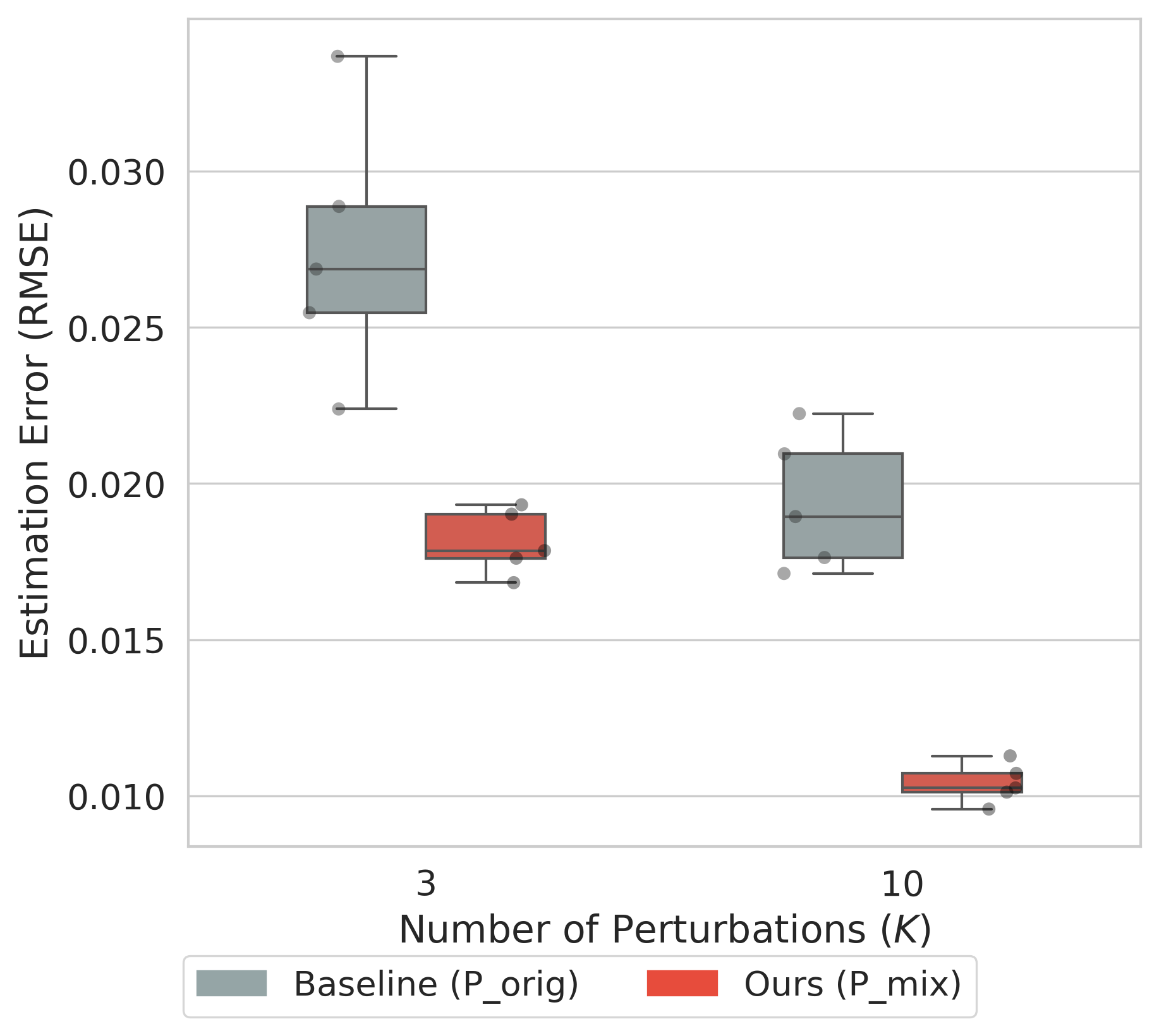
大型语言模型(LLM)的不确定性量化对于缓解幻觉以及在安全关键任务中实现风险感知部署至关重要。然而,通过深度集成来估计认知不确定性(EU)在现代模型规模下计算成本过高。我们提出了一个框架,利用小型draft模型来有效估计token级别的EU,避免了全尺寸集成的需求。该方法在偏差-方差分解的理论基础上,通过draft之间的Jensen-Shannon散度(方差代理)和draft混合与目标之间的KL散度(偏差代理)来近似EU。为了进一步确保准确性而又不产生显著的开销,我们引入了在线随机蒸馏(OSD)来有效近似目标聚合,以及数据多样性Draft(DDD)策略来增强draft多样性,从而更好地近似目标。在GSM8K上的大量实验表明,与基线相比,我们的方法将估计误差(RMSE)降低了高达37%。至关重要的是,我们的方法实现了与基于重度扰动的方法(如TokUR)相媲美的幻觉检测性能,同时产生的推理成本可以忽略不计,为不确定性感知的LLM部署提供了一种实用的解决方案。
🔬 方法详解
问题定义:论文旨在解决大型语言模型(LLM)中认知不确定性(Epistemic Uncertainty, EU)难以高效估计的问题。现有方法,如深度集成,虽然可以较好地估计EU,但由于需要训练和推理多个完整的LLM,计算成本非常高昂,使其在实际应用中难以落地。因此,如何在保证不确定性估计准确性的前提下,显著降低计算成本,是本研究要解决的核心问题。
核心思路:论文的核心思路是利用知识蒸馏,将大型目标模型的知识迁移到多个小型“draft”模型上,然后通过分析这些draft模型之间的差异来估计EU。具体来说,通过Jensen-Shannon散度来衡量draft模型之间的方差,作为EU的方差代理;通过KL散度来衡量draft模型混合分布与目标模型之间的偏差,作为EU的偏差代理。这种方法避免了直接对大型模型进行集成,从而大大降低了计算成本。
技术框架:该框架主要包含以下几个关键模块:1) Draft模型训练:使用知识蒸馏技术,训练多个小型draft模型,使其能够模仿大型目标模型的行为。2) 不确定性估计:利用draft模型之间的Jensen-Shannon散度(方差代理)和KL散度(偏差代理)来近似token级别的EU。3) 在线随机蒸馏(OSD):用于高效地近似目标聚合,减少偏差。4) 数据多样性Draft(DDD)策略:通过增加训练数据的多样性,提升draft模型的多样性,从而更好地近似目标。
关键创新:该论文的关键创新在于提出了一种基于知识蒸馏的EU估计方法,该方法能够在保证不确定性估计准确性的前提下,显著降低计算成本。与传统的深度集成方法相比,该方法避免了对大型模型进行集成,从而大大降低了计算复杂度。此外,OSD和DDD策略进一步提升了目标近似的准确性和draft的多样性。
关键设计:在知识蒸馏过程中,使用了在线随机蒸馏(OSD)来近似目标聚合,这是一种高效的蒸馏方法,可以在训练过程中动态地更新目标模型。数据多样性Draft(DDD)策略通过对训练数据进行增强,例如使用不同的prompt或数据增强技术,来增加draft模型的多样性。Jensen-Shannon散度和KL散度的计算方式采用了标准公式,并针对token级别的EU估计进行了优化。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在GSM8K数据集上将不确定性估计的RMSE降低了高达37%,显著优于基线方法。更重要的是,该方法在幻觉检测方面取得了与基于重度扰动的方法(如TokUR)相媲美的性能,同时推理成本几乎可以忽略不计,这使其成为一种极具实用价值的LLM不确定性估计方法。
🎯 应用场景
该研究成果可广泛应用于对安全性要求较高的LLM应用场景,例如医疗诊断、金融风控、自动驾驶等。通过量化LLM的不确定性,可以有效降低模型产生幻觉的风险,提高决策的可靠性,从而避免潜在的严重后果。此外,该方法还可以用于提升LLM的可解释性,帮助用户更好地理解模型的决策过程。
📄 摘要(原文)
Quantifying uncertainty in Large Language Models (LLMs) is essential for mitigating hallucinations and enabling risk-aware deployment in safety-critical tasks. However, estimating Epistemic Uncertainty(EU) via Deep Ensembles is computationally prohibitive at the scale of modern models. We propose a framework that leverages the small draft models to efficiently estimate token-level EU, bypassing the need for full-scale ensembling. Theoretically grounded in a Bias-Variance Decomposition, our approach approximates EU via Jensen-Shannon divergence among drafts (variance proxy) and KL divergence between the draft mixture and the target (bias proxy). To further ensure accuracy without significant overhead, we introduce Online Stochastic Distillation (OSD) to efficiently approximate target aggregation and the Data-Diverse Drafts (DDD) strategy to enhance draft diversity for better target approximation. Extensive experiments on GSM8K demonstrate that our method reduces the estimation error (RMSE) by up to 37% compared to baselines. Crucially, our approach achieves Hallucination Detection performance competitive with heavy perturbation-based methods like TokUR while incurring negligible inference costs, offering a practical solution for uncertainty-aware LLM deployment.