VLM-Guided Experience Replay
作者: Elad Sharony, Tom Jurgenson, Orr Krupnik, Dotan Di Castro, Shie Mannor
分类: cs.LG, cs.AI
发布日期: 2026-02-02
💡 一句话要点
利用VLM引导经验回放,提升强化学习样本效率与性能
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture) 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 强化学习 经验回放 视觉-语言模型 优先级排序 样本效率
📋 核心要点
- 现有强化学习方法在利用经验回放时缺乏有效的优先级排序机制,导致样本效率低下。
- 该论文提出利用预训练的视觉-语言模型(VLM)作为自动评估器,指导经验回放缓冲区中子轨迹的优先级排序。
- 实验结果表明,该方法在游戏和机器人等多种场景下,显著提升了强化学习的样本效率和成功率。
📝 摘要(中文)
大型语言模型(LLMs)和视觉-语言模型(VLMs)的最新进展带来了强大的语义和多模态推理能力,为提升强化学习(RL)中的样本效率、高层规划和可解释性创造了新的机会。虽然之前的工作已经将LLMs和VLMs集成到RL的各个组件中,但作为存储和重用经验的核心组件——回放缓冲区,仍未被探索。我们提出利用VLMs来指导回放缓冲区中经验的优先级排序,以解决这一差距。我们的核心思想是使用一个冻结的、预训练的VLM(不需要微调)作为自动评估器,以识别和优先排序来自agent经验的有希望的子轨迹。在包括游戏和机器人等离散和连续领域的各种场景中,与以前的方法相比,使用我们提出的优先级排序方法训练的agent实现了11-52%的平均成功率提升,并将样本效率提高了19-45%。
🔬 方法详解
问题定义:现有强化学习方法在经验回放时,通常采用均匀采样或基于TD误差的优先级排序,这些方法无法有效识别和利用有价值的子轨迹,导致样本效率低下。尤其是在复杂任务中,agent需要探索大量的状态空间,低效的经验回放机制会严重限制学习速度和最终性能。
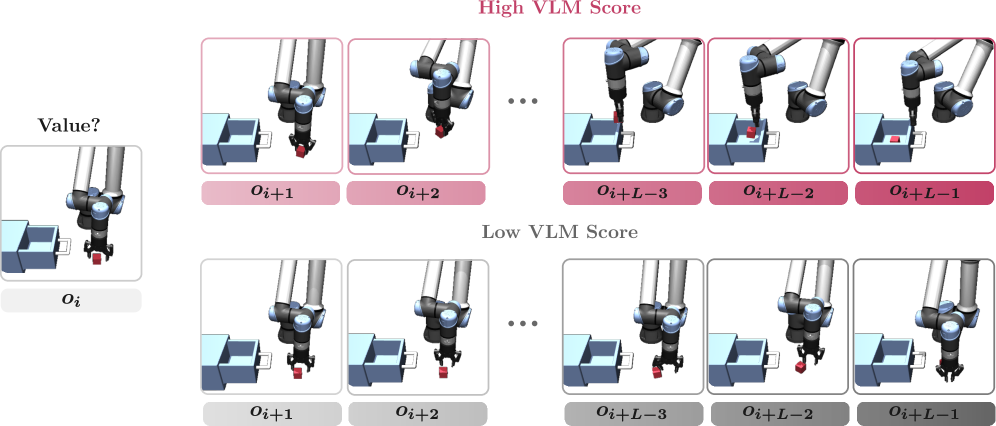
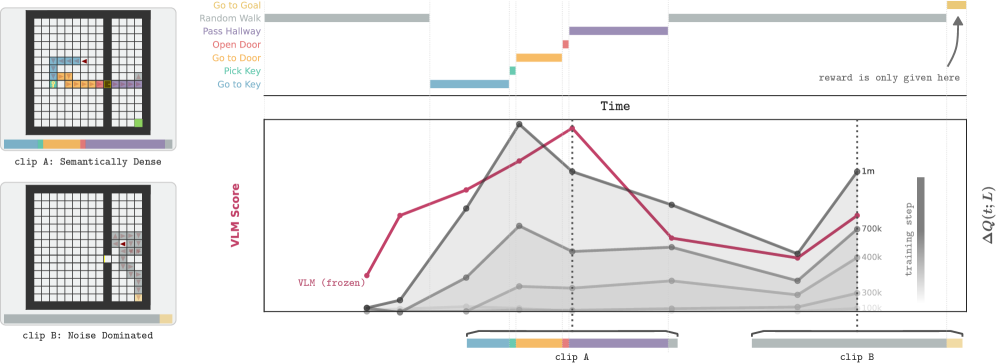
核心思路:该论文的核心思路是利用预训练的视觉-语言模型(VLM)的强大语义理解能力,对agent产生的经验进行评估,并根据VLM的评估结果对回放缓冲区中的子轨迹进行优先级排序。VLM能够识别有希望的、与任务目标相关的子轨迹,从而提高样本利用率。
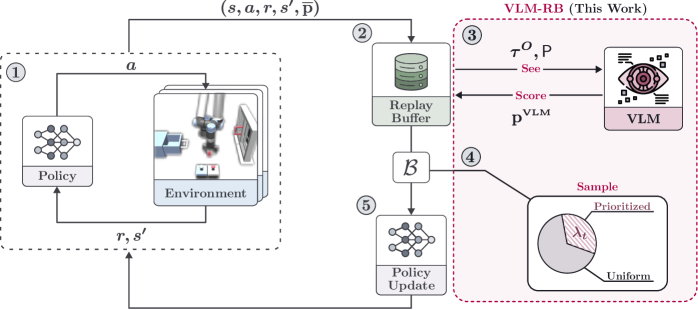
技术框架:整体框架包括三个主要部分:1) Agent与环境交互产生经验数据;2) VLM作为自动评估器,对agent产生的子轨迹进行评估打分;3) 根据VLM的评分结果,对回放缓冲区中的子轨迹进行优先级排序,并在训练时优先采样高优先级的子轨迹。VLM保持冻结状态,无需针对特定任务进行微调。
关键创新:最重要的创新点在于将预训练的VLM引入到强化学习的经验回放机制中,利用VLM的语义理解能力指导经验的优先级排序。与传统的基于TD误差的优先级排序方法相比,VLM能够更准确地评估经验的价值,从而提高样本效率。此外,使用冻结的VLM避免了额外的训练开销。
关键设计:VLM被用作子轨迹的评估器,输入为子轨迹中的状态序列(例如,图像帧),输出为该子轨迹的得分。具体来说,论文使用VLM计算子轨迹与任务目标之间的语义相似度,相似度越高,得分越高。回放缓冲区的采样概率与子轨迹的得分成正比。论文还探索了不同的VLM模型和子轨迹长度对性能的影响。
🖼️ 关键图片
📊 实验亮点
实验结果表明,在游戏(Atari)和机器人控制(Meta-World)等多个benchmark上,该方法显著提升了强化学习的性能。具体来说,与基线方法相比,该方法在平均成功率上提升了11-52%,样本效率提升了19-45%。这些结果表明,利用VLM指导经验回放能够有效地提高强化学习的效率和性能。
🎯 应用场景
该研究成果可广泛应用于机器人控制、游戏AI、自动驾驶等领域。通过利用VLM对经验进行更智能的筛选和利用,可以显著降低强化学习的训练成本,加速智能体的学习过程,并提升智能体在复杂环境中的适应能力。未来,该方法有望扩展到更复杂的任务和环境,并与其他强化学习技术相结合,实现更强大的智能体。
📄 摘要(原文)
Recent advances in Large Language Models (LLMs) and Vision-Language Models (VLMs) have enabled powerful semantic and multimodal reasoning capabilities, creating new opportunities to enhance sample efficiency, high-level planning, and interpretability in reinforcement learning (RL). While prior work has integrated LLMs and VLMs into various components of RL, the replay buffer, a core component for storing and reusing experiences, remains unexplored. We propose addressing this gap by leveraging VLMs to guide the prioritization of experiences in the replay buffer. Our key idea is to use a frozen, pre-trained VLM (requiring no fine-tuning) as an automated evaluator to identify and prioritize promising sub-trajectories from the agent's experiences. Across scenarios, including game-playing and robotics, spanning both discrete and continuous domains, agents trained with our proposed prioritization method achieve 11-52% higher average success rates and improve sample efficiency by 19-45% compared to previous approaches. https://esharony.me/projects/vlm-rb/