Internal Flow Signatures for Self-Checking and Refinement in LLMs
作者: Sungheon Jeong, Sanggeon Yun, Ryozo Masukawa, Wenjun Haung, Hanning Chen, Mohsen Imani
分类: cs.LG
发布日期: 2026-02-02
💡 一句话要点
提出内部流签名用于LLM的自检与优化,提升生成可靠性。
🎯 匹配领域: 支柱九:具身大模型 (Embodied Foundation Models)
关键词: 大语言模型 自检 内部流签名 深度动态 模型优化
📋 核心要点
- 现有大语言模型生成内容可能不忠实于上下文,且依赖外部验证或独立判断,效率较低。
- 提出内部流签名方法,通过监控模型内部深度动态来审计决策过程,实现自检与优化。
- 实验表明,该方法能有效定位错误并进行针对性优化,在保证性能的同时降低了开销。
📝 摘要(中文)
大型语言模型会生成流畅但不忠实于上下文的答案,而许多安全措施依赖于外部验证或生成后的独立判断。本文提出“内部流签名”,通过在固定块间监控边界处的深度动态来审计决策形成过程。该方法通过以偏差为中心的监控来稳定token级别的运动,然后在每个深度窗口内,从top token及其紧密竞争者构建的紧凑“移动”读出对齐子空间中总结轨迹。相邻窗口帧通过正交变换对齐,产生深度可比的变换步长、转角和子空间漂移摘要,这些摘要对于窗口内的基选择是不变的。在这些签名上训练的轻量级GRU验证器执行自检,而无需修改基础模型。除了检测之外,验证器还可以定位有问题的深度事件,并实现有针对性的优化:模型回滚到有问题的token,并在识别的块处钳制异常的变换步长,同时保留正交残差。由此产生的流程提供可操作的定位和来自内部决策动态的低开销自检。代码已开源。
🔬 方法详解
问题定义:大型语言模型在生成文本时,可能会产生与输入上下文不一致或不忠实的内容。现有的安全措施通常依赖于外部验证或独立的判别模型,这些方法增加了计算开销,并且无法直接干预模型的内部决策过程,难以实现高效的自纠错。因此,如何让LLM在生成过程中进行自我检查和修正,提高生成内容的可靠性,是一个亟待解决的问题。
核心思路:本文的核心思路是通过监控模型内部的token流动轨迹,捕捉模型在不同深度层次上的决策动态。具体来说,作者提出了一种名为“内部流签名”的方法,该方法通过分析模型内部的激活状态,提取关键的决策信息,并利用这些信息来判断模型是否偏离了正确的生成路径。这种方法的核心在于,它将模型的内部状态视为一种动态系统,通过分析token在不同深度层次上的运动轨迹,来理解模型的决策过程。
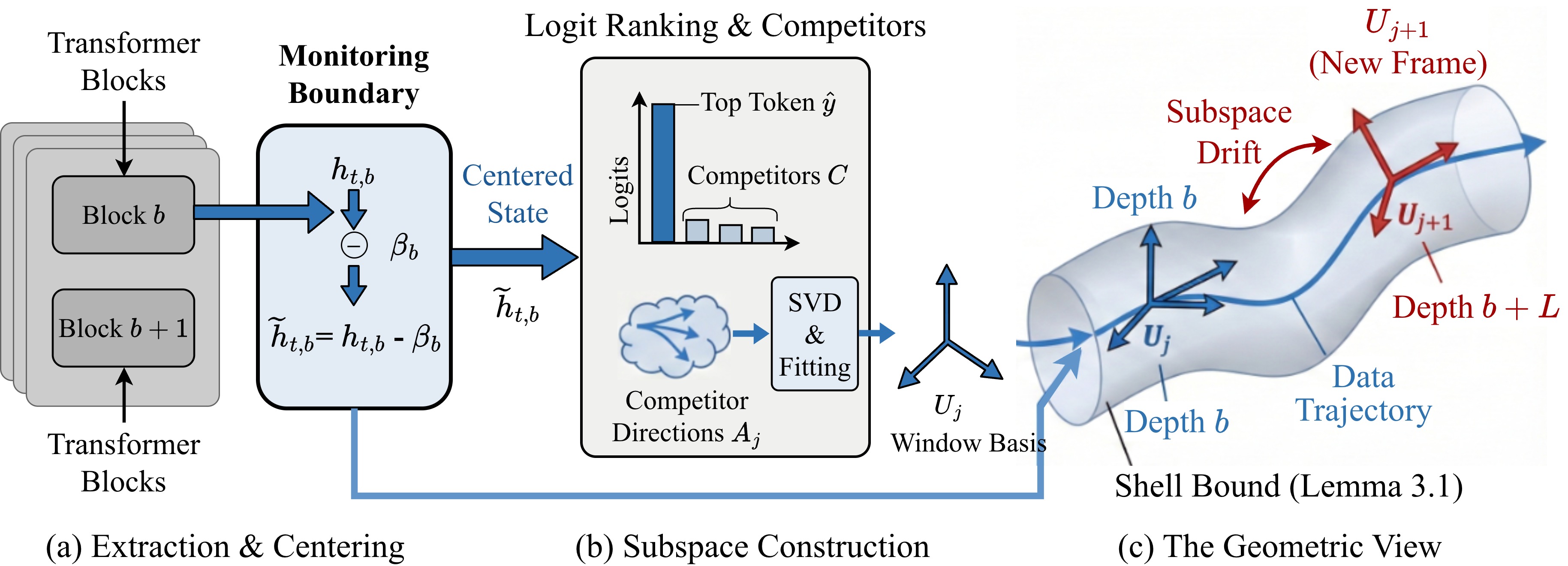
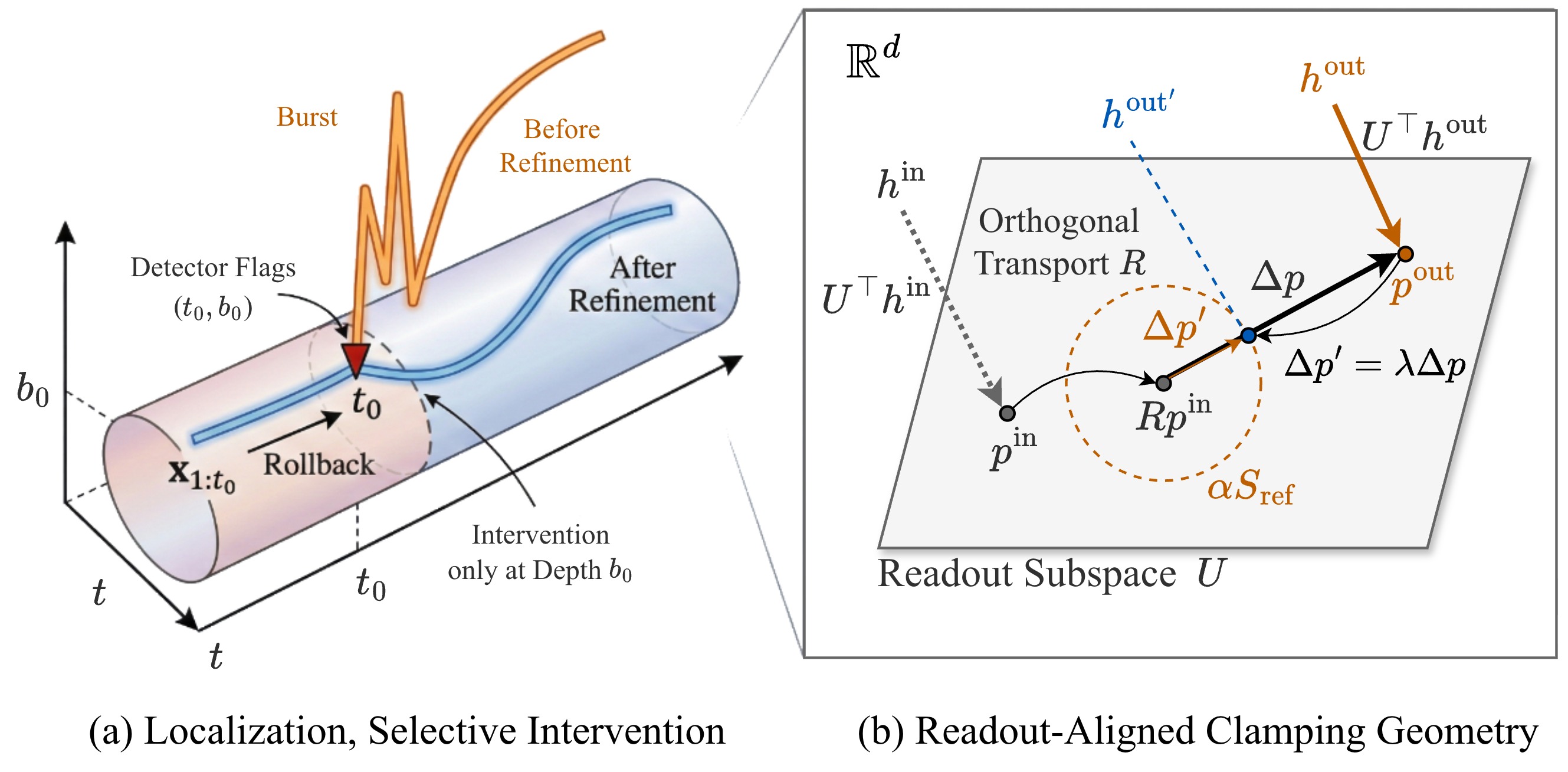
技术框架:该方法主要包含以下几个阶段:1) Token运动稳定化:通过以偏差为中心的监控,稳定token级别的运动轨迹。2) 子空间构建:在每个深度窗口内,从top token及其竞争者构建紧凑的“移动”读出对齐子空间。3) 帧对齐:通过正交变换对齐相邻窗口帧,生成深度可比的变换步长、转角和子空间漂移摘要。4) 自检验证:使用在内部流签名上训练的轻量级GRU验证器执行自检。5) 定位与优化:定位有问题的深度事件,并回滚到相应的token,钳制异常的变换步长,同时保留正交残差。
关键创新:该方法最重要的创新点在于提出了“内部流签名”的概念,并将其应用于LLM的自检与优化。与传统的外部验证方法不同,该方法直接监控模型的内部状态,能够更早地发现错误并进行干预。此外,该方法还提出了一种基于正交变换的帧对齐方法,使得不同深度层次上的token运动轨迹具有可比性,从而能够更准确地判断模型的决策过程。
关键设计:在token运动稳定化阶段,作者采用了以偏差为中心的监控策略,以减少噪声的影响。在子空间构建阶段,作者选择top token及其竞争者来构建子空间,以捕捉关键的决策信息。在帧对齐阶段,作者采用了正交变换,以保证变换后的步长具有可比性。在自检验证阶段,作者使用轻量级的GRU网络,以降低计算开销。此外,作者还设计了一种回滚机制,使得模型能够回到错误发生的token,并进行修正。
🖼️ 关键图片

📊 实验亮点
该论文提出了内部流签名方法,通过监控模型内部状态实现自检与优化。实验结果(具体数值未知)表明,该方法能够在不显著增加计算开销的情况下,有效定位并纠正LLM生成过程中的错误,提升生成内容的可靠性。与现有方法相比,该方法具有更高的效率和更强的可解释性。
🎯 应用场景
该研究成果可应用于各种需要高可靠性的大语言模型应用场景,例如智能客服、金融分析、医疗诊断等。通过提高LLM生成内容的准确性和一致性,可以减少错误信息的传播,提升用户体验,并降低潜在的风险。未来,该方法有望与其他安全措施相结合,构建更安全、更可靠的大语言模型系统。
📄 摘要(原文)
Large language models can generate fluent answers that are unfaithful to the provided context, while many safeguards rely on external verification or a separate judge after generation. We introduce \emph{internal flow signatures} that audit decision formation from depthwise dynamics at a fixed inter-block monitoring boundary. The method stabilizes token-wise motion via bias-centered monitoring, then summarizes trajectories in compact \emph{moving} readout-aligned subspaces constructed from the top token and its close competitors within each depth window. Neighboring window frames are aligned by an orthogonal transport, yielding depth-comparable transported step lengths, turning angles, and subspace drift summaries that are invariant to within-window basis choices. A lightweight GRU validator trained on these signatures performs self-checking without modifying the base model. Beyond detection, the validator localizes a culprit depth event and enables a targeted refinement: the model rolls back to the culprit token and clamps an abnormal transported step at the identified block while preserving the orthogonal residual. The resulting pipeline provides actionable localization and low-overhead self-checking from internal decision dynamics. \emph{Code is available at} \texttt{github.com/EavnJeong/Internal-Flow-Signatures-for-Self-Checking-and-Refinement-in-LLMs}.