Designing Time Series Experiments in A/B Testing with Transformer Reinforcement Learning
作者: Xiangkun Wu, Qianglin Wen, Yingying Zhang, Hongtu Zhu, Ting Li, Chengchun Shi
分类: cs.LG, stat.ME, stat.ML
发布日期: 2026-02-02
💡 一句话要点
提出基于Transformer强化学习的时间序列A/B测试设计方法,优化策略评估。
🎯 匹配领域: 支柱二:RL算法与架构 (RL & Architecture)
关键词: A/B测试 时间序列 Transformer 强化学习 实验设计 策略评估 因果推断
📋 核心要点
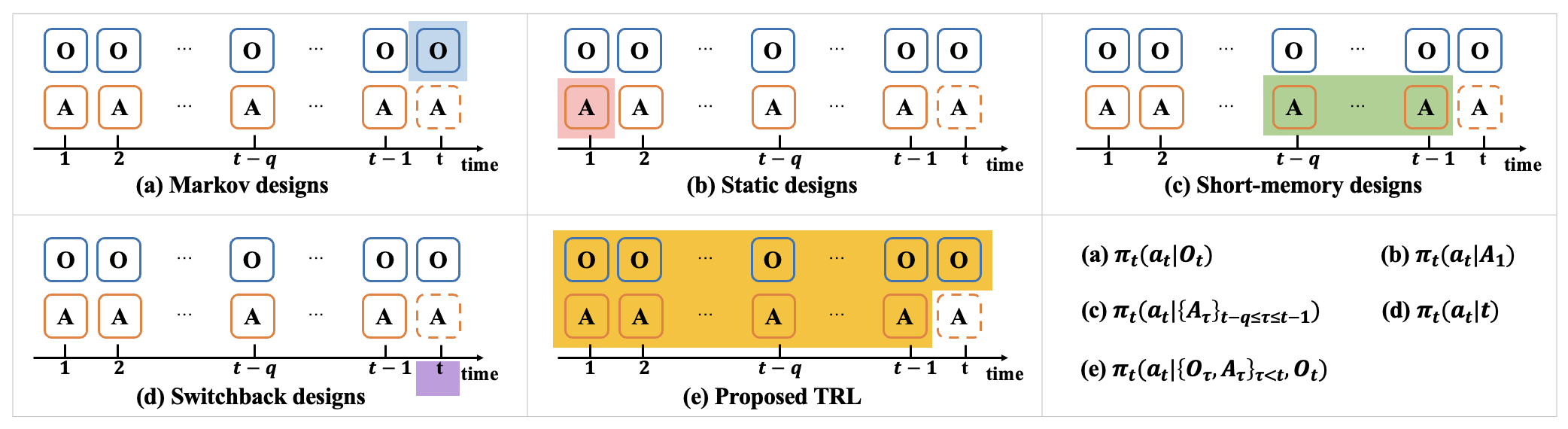
- 现有时间序列A/B测试设计未能充分利用历史信息,且依赖强假设近似目标函数,导致次优结果。
- 提出Transformer强化学习方法,利用Transformer处理历史信息,并用强化学习直接优化均方误差,避免强假设。
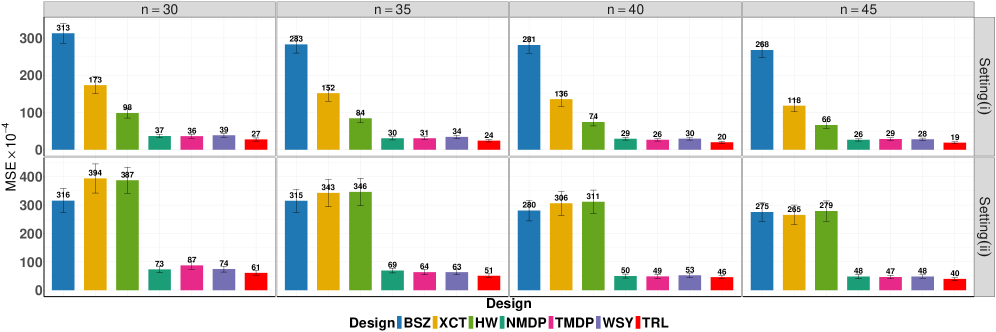
- 在合成数据、调度模拟器和网约车数据集上验证,表明该方法优于现有设计,提升策略评估效果。
📝 摘要(中文)
A/B测试已成为现代科技公司进行策略评估的金标准。然而,将其应用于时间序列实验,即策略随时间顺序分配的场景,仍然具有挑战性。现有的设计存在两个局限性:(i)它们没有充分利用整个历史信息进行处理分配;(ii)它们依赖于强假设来近似目标函数(例如,估计处理效应的均方误差)以优化设计。我们首先建立一个不可能定理,表明由于时间序列实验中的动态依赖性,未能以完整的历史信息为条件会导致次优设计。为了同时解决这两个局限性,我们接下来提出了一种Transformer强化学习(RL)方法,该方法利用Transformer以整个历史信息为条件进行分配,并采用RL直接优化MSE,而无需依赖于限制性假设。在合成数据、公开可用的调度模拟器和真实世界的网约车数据集上的经验评估表明,我们的方案始终优于现有设计。
🔬 方法详解
问题定义:论文旨在解决时间序列A/B测试中,现有方法无法有效利用历史信息进行策略分配,以及依赖强假设近似目标函数的问题。现有方法的痛点在于,忽略了时间序列数据的动态依赖性,导致次优的实验设计和策略评估结果。
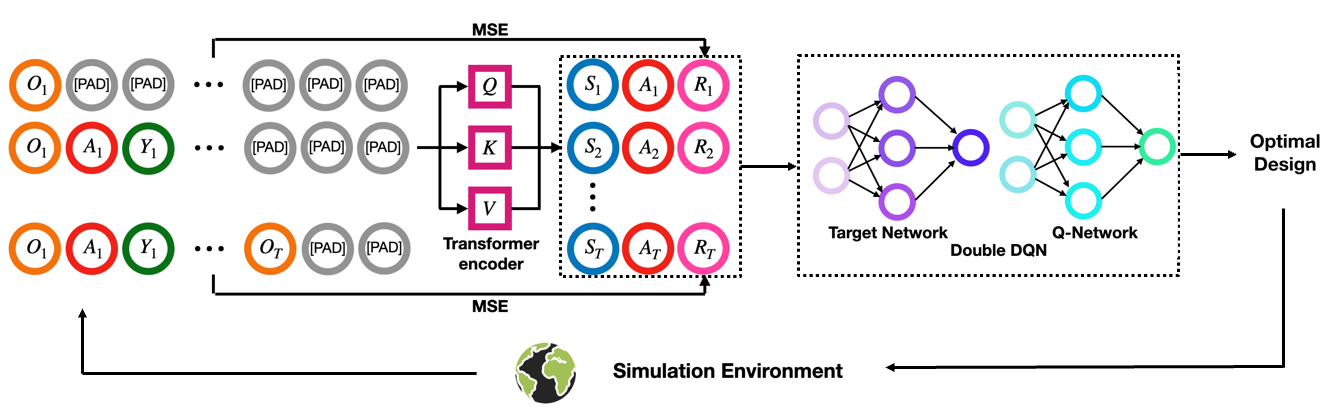
核心思路:论文的核心思路是利用Transformer模型来捕捉时间序列数据的长期依赖关系,并结合强化学习直接优化实验设计的均方误差(MSE)。通过将整个历史信息作为Transformer的输入,模型能够更准确地预测不同策略分配方案对结果的影响,从而选择最优的分配方案。
技术框架:整体框架包含以下几个主要模块:1) 环境模拟器:用于模拟时间序列数据和策略交互的过程。2) Transformer模型:用于编码历史信息,并预测不同策略分配方案的奖励。3) 强化学习算法:用于训练Transformer模型,使其能够选择最优的策略分配方案。4) 评估模块:用于评估不同实验设计的性能,例如估计处理效应的均方误差。
关键创新:最重要的技术创新点在于将Transformer模型引入到时间序列A/B测试设计中,并结合强化学习直接优化MSE。与现有方法相比,该方法能够更有效地利用历史信息,避免了对目标函数的强假设,从而获得更优的实验设计。
关键设计:Transformer模型采用标准的encoder-decoder结构,encoder用于编码历史信息,decoder用于预测不同策略分配方案的奖励。强化学习算法采用策略梯度方法,目标是最大化期望奖励。损失函数为均方误差(MSE),用于衡量估计处理效应的准确性。具体的参数设置需要根据具体的数据集和实验场景进行调整。
🖼️ 关键图片
📊 实验亮点
实验结果表明,该方法在合成数据、公开的调度模拟器和真实网约车数据集上均优于现有设计。在网约车数据集上,该方法能够显著降低估计处理效应的均方误差,提升策略评估的准确性。具体的性能提升幅度取决于数据集和实验设置,但总体趋势表明该方法具有较强的优势。
🎯 应用场景
该研究成果可广泛应用于需要进行序列决策的场景,例如在线广告投放、推荐系统优化、智能交通调度、金融交易策略等。通过优化A/B测试设计,可以更准确地评估不同策略的效果,从而提高决策效率和收益。该方法在网约车调度系统中的应用,可以优化派单策略,提升用户体验和平台效率。
📄 摘要(原文)
A/B testing has become a gold standard for modern technological companies to conduct policy evaluation. Yet, its application to time series experiments, where policies are sequentially assigned over time, remains challenging. Existing designs suffer from two limitations: (i) they do not fully leverage the entire history for treatment allocation; (ii) they rely on strong assumptions to approximate the objective function (e.g., the mean squared error of the estimated treatment effect) for optimizing the design. We first establish an impossibility theorem showing that failure to condition on the full history leads to suboptimal designs, due to the dynamic dependencies in time series experiments. To address both limitations simultaneously, we next propose a transformer reinforcement learning (RL) approach which leverages transformers to condition allocation on the entire history and employs RL to directly optimize the MSE without relying on restrictive assumptions. Empirical evaluations on synthetic data, a publicly available dispatch simulator, and a real-world ridesharing dataset demonstrate that our proposal consistently outperforms existing designs.